2024.07.08
ABテストの自動化の取り組みについて
まとめ
- ABテスト自動化のジョブフローとデータパイプラインの構成を整理した
- ABテスト自動化を検討している方は参考にしてほしい
AI研のM. S.です。ここでは我々データサイエンティストの心の拠り所であるABテストの自動化を試みたので紹介させていただきます。基本的には、メルカリ社の「メルカリにおけるA/Bテスト分析自動化の取り組み」の流れを踏襲しています。
私は現在モバイルアプリを運営するグループ会社でデータサイエンティストとして、日々、データ分析観点に基づいた施策立案や、ABテストの効果測定のための統計検定、施策の効果の事前見積もり、KPI整理と可視化、データ分析基盤構築など幅広くデータ分析業務に携わっています。
背景
現代のビジネス環境において、意思決定の迅速化とデータに基づく戦略の最適化は、成功を収めるための重要な要素です。特にマーケティングやプロダクト開発において、ユーザーの行動を理解し、最も効果的なアプローチを見つけるための手法としてABテストは広く利用されています。しかし、ABテストの実施は手間と時間がかかる作業であり、頻繁に行うには効率化が求められます。
ABテストの効率化・標準化についてはメルカリ社の「メルカリにおけるA/Bテスト標準化への取り組み」が詳しいです。
特に、現状の課題感として
- 週に1,2回程度の頻度で行うABテストの設計や効果測定に工数を多く割かれている。
- Google Colaboratoryを用いて効果測定の分析をしていたので、計算資源と再利用性に制約があった。
- プロセスが標準化されておらず、分析担当者によって分析内容にばらつきがあった。
といったものがあり、それを改善するために、ABテストの自動化を行うこととなりました。
ジョブフロー
少し登場人物が多いですが、メインアーキテクチャは以下のようになっていてこれもメルカリ社のメルカリにおけるA/Bテスト分析自動化の取り組みに倣っています。
- 設定ファイルからのDAG生成することでデータパイプライン定義
- DAGによるA/Bテストの統計値計算
- アプリケーション上での統計値表示
以下メインアーキテクチャに絞って詳しく解説していきます。
設定ファイルからのDAG作成することでデータパイプライン定義
ステップ概要: 設定ファイルからDAGを生成し、A/Bテストを管理するタスクを定義します。設定ファイルにはテストのパラメータやデータソースが含まれます。cloud composer上で実装されており、設定ファイルの日時データをもとに、A/Bテストを自動実行します。
この工程はABテスト設計時に行われます。
まずは設定ファイルを作成します。
設定ファイルには、DAG生成に必要な引数と後段のA/Bテストの統計値計算を行うために必要な引数を記述します。全てのA/Bテスト共通の設定ファイルとA/Bテスト個別の設定ファイルがあります。
共通設定の例
metrics:
- metric_name: active_user
agg_type: probability
metric_elements:
- activity_tap_buying_button
- activity_tap_subscribing_button
- metric_name: cost
agg_type: count
metric_elements:
- cost_hoge
- cost_hogehoge
個別設定の例
# start_date: 実験開始日 "YYYY-MM-DD"
# end_date: 実験終了日 "YYYY-MM-DD"
# allocation_method: 割り付け方式
# test_key: テストキー
# os_name: OS名 "iOS" or "Android"
# min_app_version: 最小アプリバージョン "X.X.X"
# max_app_version: 最大アプリバージョン "X.X.X"
# trigger_metric_name: トリガーメトリック名 "activity_XXX" or "impression_XX" など
# outlier_ratio: 外れ値比率 0以上1以下
# significance_level: 有意水準 0以上1以下
# unique_metrics:
# - metric_name: テスト固有のメトリック名 "revenue" or "impression" など
# agg_type: activityなら"probability"、それ以外"count"
# metric_elements:
# - この配列のelementsが、足し算されてmetric_nameを指標としてttestが行われる
change_hoge_color:
start_date: "2024-01-29"
end_date: "2024-02-06"
allocation_method: "firebase"
test_key: "firebase_exp_01"
os_name: "iOS"
min_app_version: "8.23.0"
max_app_version: ""
trigger_metric_name: "activity_show_home_screen"
outlier_ratio: 0.01
significance_level: 0.05
unique_metrics:
- metric_name: "cost_fuga"
agg_type: "count"
metric_elements:
- "cost_fuga"
- "cost_fugafuga"
- metric_name: "revenue_hoge"
agg_type: "count"
metric_elements:
- "revenue_hoge"
特に重要となる設定をpickupして説明します。
- start_date/end_date:
- 実験の開始日/終了日を示します。形式は “YYYY-MM-DD” です。
- この情報をもとに、終了日になると生成されたDAGがkickされ、後段のA/Bテストの統計値計算が実行されます。
- allocation_method/test_key :
- テスト対象者の割り付け方法を指定します。
- RCTとなる必要があります。
- trigger_metric_name:
- トリガーメトリックの名前を指定します。
- SRMが発生しないように設定する必要があります。詳しくは過去ブログにて。
- metrics/ unique_metrics:
- metricsで全テスト共通のメトリクスの定義を行い、unique_metricsでテスト固有のメトリクスを定義します。
- 以下のサブ項目があります:
- metric_name: メトリック名です。
- agg_type: 集計タイプを指定します。”probability”と”count” があり、DAUのような日当たりのユニーク回数がサンプルとなる場合は、”probability”、その他の売上や費用などの一般的な合計値がサンプルとなるような場合は”count”を指定します。
- metric_elements: メトリックを構成する要素のリストです。ここに指定された各要素の値が合計されてメトリックが計算されます。
次にこの設定ファイルを読み込んで、DAGを生成するPythonファイルを記述します。
from datetime import datetime, timedelta
import os
import yaml
from airflow import models
from operators.bigquery import ExecuteBigQueryOperator
DAG_DATA_DIR = "/path/hoge"
config_yaml_path = os.path.join(DAG_DATA_DIR, "config.yaml")
with open(config_yaml_path, "r", encoding="utf-8") as f:
config = yaml.safe_load(f)
for test_name in config.keys():
# DAG作成
dag_id = f"env_ab-testing_{test_name}"
dag_config = config[test_name]
execution_date = datetime.strptime(dag_config["end_date"], '%Y-%m-%d') + timedelta(days=1)
execution_date = execution_date.replace(hour=12, minute=0, second=0, microsecond=0)
globals()[dag_id] = models.DAG(
dag_id=dag_id,
default_args={
"start_date": execution_date,
"retries": 2,
"retry_delay": timedelta(minutes=5),
},
schedule_interval=None,
catchup=False,
tags=["ab-testing"],
)
dataset_suffix = "_stg"
# task 1: Extract triggered users
triggered_users_task = ExecuteBigQueryOperator(
task_id="extract_triggered_users",
dag=globals()[dag_id],
)
# task 2: Make Samples
all_metrics_task = ExecuteBigQueryOperator(
task_id="all_metrics",
dag=globals()[dag_id],
)
# task 3: Perform t-test
ttest_task = ExecuteBigQueryOperator(
task_id="ttest",
dag=globals()[dag_id],
)
# Set task dependencies
triggered_users_task >> all_metrics_task >> ttest_task
こちらでは、以下の3つのタスクのDAGを作成しています。
- A/Bの割当とトリガー日付の割当
- サンプルテーブルの作成
- ttestの実行
それぞれがどのようなタスクなのかは次の章で説明します。
そもそもDAG作成とはなにかというとデータパイプラインの定義の方法です。
本案件ではApache Airflowのpython apiを用いています。このあたりは公式ドキュメントやこの記事が詳しいです。
DAGによるA/Bテストの統計値計算
以下の3ステップのタスクがcloud composerからExecuteBigQueryOperatorが呼び出され定義されているsqlが実行されます。
inputとoutputはgoogle cloud storageで完結しており、BigQueryでETLを行います。
またこのタスクを行う前提として、メトリクスの中間集計テーブルが作成されているとクリーンなコードにすることができるので、その点もゼロ番目の工程として説明します。
全体の処理イメージは以下

メトリクスの中間集計テーブル作成
ステップ概要: このステップでは、様々なメトリクスをユーザーごとに日次で集計して、メトリクステーブルを作ります。
まず前提として、テストをしたい指標に関するデータが、データウェアハウスに蓄積されていてreadできることが前提となります。ここでは、SalesやCost、firebaseのEvent等のデータを想定しています。
これらのデータを日次でユーザーごとに集計して、中間テーブルにまとめます。例えば、ユーザーの売上をメトリクスとしてテストする場合、Salesテーブルからユーザー、日毎の売上を足し合わせて、metrics_name=”sales” metric_value = 5.6(円)のような形で、中間集計テーブルにinsertしていきます。そして、メトリクスの数×ユーザー数が、毎日insertされていくイメージです。(実業務は、GCPのサービスであるパーティションの機能を使っているので、insertではなく、日毎にtableをcreateしています。)
ABテストの度に生テーブルを直接読み込むこともできますが、日次バッチで中間テーブルを作成することは以下のメリットが存在します。
- データスキャン量を減らすことができる。特にBigQueryを用いる場合はデータスキャン料に応じて課金がなされるため、コスト削減に直結する。
- その他のダッシュボード作成や分析タスクに横流しができる。
このあたりはそもそも中間テーブルを作るかとか、どの指標を中間テーブルに含めるかに効果とコストのトレードオフの関係があるので、データ活用の程度を見極めて実装するのがいいと思われます。データ活用の程度・規模が大きくなると中間テーブルがより便利になってくると思われます。
A/Bの割当とトリガーの割当
ステップ概要: このステップでは、対象ユーザーにA/Bテストのグループ(AまたはB)とトリガー情報を割り当てます。
A/Bテストの心臓とも言える無作為割当を行います。我々のA/Bテストは、ユーザーごとにuser_patternとして、”treat”または”control”をアサインしていきます。また、トリガーされた日付も付与します。トリガー日付は、テスト開始からユーザーが決まった条件を初めて達成した日付を書き込みます。例えば、firebase eventでイベント定義をして、「Home画面の閲覧」をtrigerとして設定ファイルに定義して、テスト開始から最も早くそのイベントを体験した日付をtriggered_dateに書き込みます。(簡略化のため図示されていませんが、ユーザーのeventのlogデータをreadする必要があります)
トリガーの設定の目的は、データを絞り込むことで分析対象を絞り込み、計算資源の負荷を減らすことと検出力が(多少)上がることです。
ここはアンチパターンがいくつか存在して、以下に注意する必要があります
- 本当に無作為化されているか
- SRM(Sample Ratio Mismatch)が発生していないか
最終的に結果をA/Aテストすることで、この問題を発見することができますが、計画の時点で、このような問題が起きないようにしておきたいものです。
サンプルテーブルの作成
ステップ概要: このステップでは、ユーザーの割当情報とメトリクス集計情報をjoinします。
割当情報と集計情報でジョインすることで、日、指標ごとのサンプルが作成されます。日付に関するデータはここで、施策開始から何日経ったか(”past_days”)というかたちに変形しておくことで、後段のttestの解釈が容易になります。
ttestの実行
ステップ概要: 最終ステップでは、集計されたデータを使用してt検定を実行し、A/Bテストの統計的有意性を評価します。
サンプルテーブルで日、指標ごとに統計検定を行い結果のテーブルをGCSに格納します。例えば、テスト期間が28日で定義している指標がsalesとcostsの2指標だとすると、28×2個の組み合わせでサンプルができるので統計検定を行います。詳しく説明すると、20日目のcostsに注目するとpast_days=20 かつ metric_name=”costs”について、user_idがNtreat + Ncontrol人いるので、それぞれtreatとcontrolをサンプルとしてttestを行うという要領です。
工程としては、
- 指標の集計
- 外れ値の処理
- 統計検定
となります。
指標の集計は、サンプルテーブルから更に集計を行うときに必要で、例えば、サンプルテーブルに入っているcost_hogeとcost_hogehogeを合わせて、costとして統計検定をしたい場合に、2つの指標を足し合わせるという処理を行います。このあたりの操作は最初に設定ファイルで定義をしておきます。
外れ値はbigqueryの`APPROX_QUANTILES`関数を用いて、quantileベースで異常に大きい値を取り除きます。
統計検定は、サンプルに対してウェルチのt検定を行い、平均値の差、標準誤差、p値や信頼区間等を算出して、最終的にp値をもとに有意差を判定します。
余談ですが、このとき、bigqueryには、統計検定の組み込み関数が準備されていないので、LANGUAGEを用いてJavaScriptからライブラリを借りてきます。
以下がttestをbigqueryで行うためのTEMP FUNCTIONとなります。ライブラリは、BQがアクセスできる場所に格納してurlで指定する必要があります。(参考)
CREATE TEMP FUNCTION tscore_to_p( tscore FLOAT64, n FLOAT64, sides FLOAT64 ) RETURNS FLOAT64 LANGUAGE js --JavaScriptのライブラリを用いる AS """ return jStat.ttest( tscore, n, sides); """ OPTIONS ( library=["https://storage.googleapis.com/hogehoge/jstat.js"] ) --JavaScriptのライブラリを所定のurlの場所に格納する ;
このあたりをBigQueryで完結するようにしましたが、よくよく考えるとサンプルごとの平均値と標準偏差、サンプル数等統計検定に必要な引数を集約したテーブルを作り、pythonで統計検定するとかのほうが自然だったかもしれません。というのも、結局bigqueryができないのは、t値↔p値の変換と有意水準↔信頼区間といったt分布のx↔p(x)(の積分)を用いる部分だけなので。
アプリケーション上での統計値表示
ステップ概要: 計算された統計量をアプリケーションに表示します。
streamlitを用いてデータを可視化します。
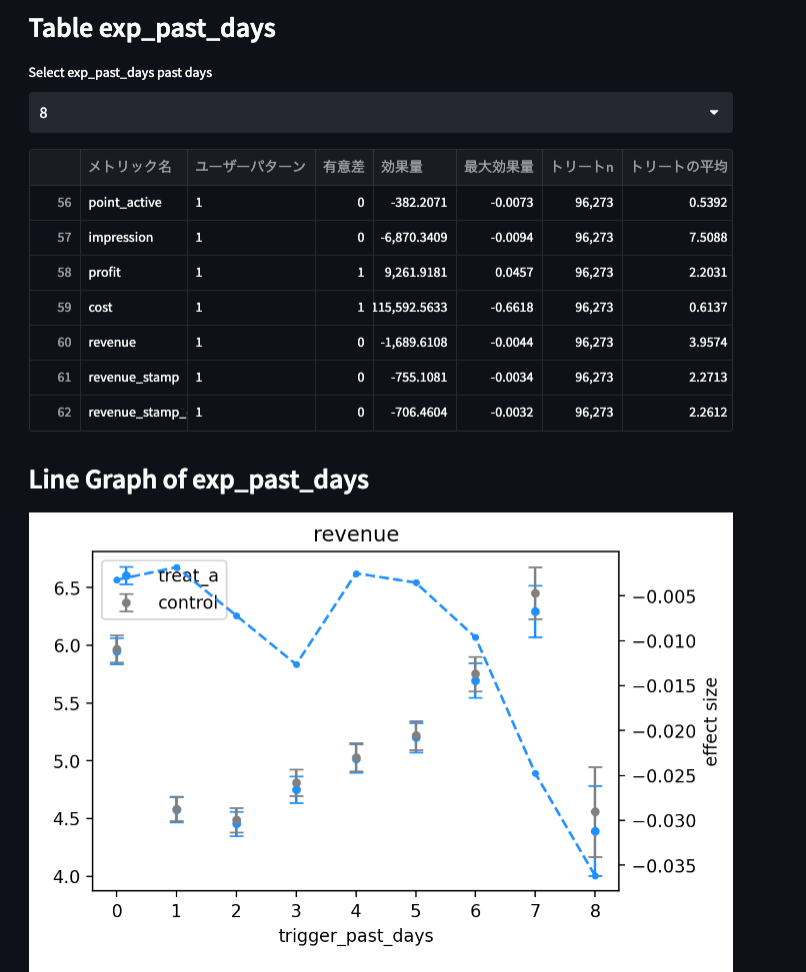
以下の指標を可視化していきます。
- 有意差
- サンプル数
- 最大効果量、最小効果量など各種効果量(このブログ参照)
- p値
- などなど
なお、このアプリケーションはcloud run上にデプロイされており、アクセス制限のためにロードバランサを経由して、ホワイトリストのipからcloud runにアクセスするという構成としています。
今後の課題
主要3工程ごとに分けて課題を述べていきます
設定ファイルからのDAG生成することでデータパイプライン定義
- KPIの結果がとても悪い/とても良い際に早期にアラートを出す機能の実装
DAGによるA/Bテストの統計値計算
- 中間テーブルに蓄積するイベントの選定
- 複雑な割当条件への対応
- 例えば、施策がある条件を満たすユーザーにのみ行われる場合(ex. 新規ユーザー)、そのユーザーの絞り込みを設定ファイルを変更するだけで行えるようにしたい。
- 複雑な指標への対応
アプリケーション上での統計値表示
- SRMの検出と可視化
- 多重比較の問題の検出と可視化
- 本件メトリクス*日数だけの統計検定を行うので、個々の結果の有意差をそのまま利用すると多重比較の問題が生じやすい
感想
これからサービスインをするので、よりよくなるよう改善を行っていきたいです。
個人的な関心としては、分析結果の蓄積をしてMeta Analysisを行いたいです。
LLM余談
アイキャッチ画像作成のため、gpt4oに「ABテスト自動化 図示」で作成してもらったところ、奇妙なフロー図が作成されました。
ABテスト自動化のフローをtextで生成して、それをもとにimg生成しているのだと思いますが、文字が書けていたり書けていなかったり、インコンテキストラーニングしたstreamlitが右下にはめ込まれていたり。
不気味の谷のようなクオリティなので、今後の性能アップに期待です!
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集要項一覧からご応募をお願いします。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD