2026.02.26
Amazon BedrockによるCodeCommit用の独自PR-Agentの構築
結論
- Amazon Bedrockと連携して、AWS CodeCommit用のPR-Agentを構築できた
- トークン最適化とチャンク分割により、大規模プルリクエストにも対応できた
はじめに
こんにちは。次世代システム研究室のT.Tです。
現在開発運用に携わっているWebサービスは、AWS環境で稼働しています。このWebサービスでは内部ロジック自体に機密性のある内容を扱っているため、リポジトリ管理にはAWS環境でセキュリティ的に強みがあるAWS CodeCommitを利用しています。一方、CodeCommitは2024年7月に段階的な廃止方針が発表されて以降、積極的な機能開発が止まっていて、標準ではAI機能が提供されていない状況となっています。このような状況のため、CodeCommitでAI連携する場合は独自に開発する必要があります。
現在、プロジェクト内でCodeCommitでのAI連携の導入を進めていて、直近ではレビューを自動化するためにAmazon Bedrockと連携するPR-Agentを開発しました。本記事では、CodeCommit用に開発したPR-Agentについてご紹介します。
※GitHub向けにはQodo AIのPR-AgentのようなOSSもあります。本記事で紹介するPR-Agentは、Qodo AIのPR-Agentとは別の独自実装です。
1.CodeCommit用のPR-Agentを開発した背景
AIを用いた業務改善の一環として、開発のレビューの効率化に取り組んでいます。プルリクエストの最終レビュー段階での手戻りを防ぐために、開発段階でのレビューを自動化して、レビュー工数を削減するのが目標です。CodeCommitには標準のAI機能がないため、AIでの自動レビューは独自に開発する必要があります。
次にCodeCommitを利用している経緯ですが、主にセキュリティの観点からCodeCommitを利用しています。CodeCommitのメリットとデメリットは以下のようなものが挙げられます。
- メリット
- AWS内のネットワークで完結して利用できるためソースコードの機密性を保てる
- IAMで認証権限を一元管理できる
- CloudWatch/CloudTrailで操作ログを追跡できる
- ランニングコストが安い
- デメリット
- UI/UXが弱い
- エコシステムが弱く、標準のAIツール連携等がない
CodeCommitとのAI連携が弱いところが課題となっていました。Webサービスの内部ロジックの機密性の保持のためにGitHub等への移行も難しいため、Bedrockを利用したPR-Agentをプロジェクト内で開発しました。
2.PR-Agentの概要
PR-Agentのレビュー結果
PR-Agentのレビュー結果は、以下のようにCodeCommitのプルリクエストのコメントとして投稿されます。トークン最適化のために英語でレビューしています。
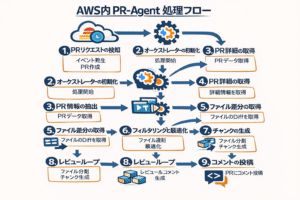
PR-Agentの処理フロー
PR-Agentは以下のフローで自動でレビューします。
- プルリクエストの検知
- オーケストレーターの初期化
- プルリクエスト情報の抽出
- プルリクエスト詳細の取得
- ファイル差分の取得
- フィルタリングと最適化
- チャンクの生成
- レビューループ
- レビューコメントの投稿
3.EventBridge用のCDK
CDKでプルリクエストのイベントをトリガーとするEventBridgeを登録します。Lambda実行用のロールを作成して、実行ファイルを登録します。
コードの概要は以下のようになります。
import ...
export class CodeCommitPRReviewStack extends cdk.Stack {
constructor(scope: Construct, id: string) {
super(scope, id);
const lambdaCodePath = "lambda-handler/codecommit-pr-review";
const lambdaRole = this.createIamRole(...);
const lambdaCode = this.createLambdaCode(...);
const lambdaFunction = this.createLambdaFunction(
lambdaRole,
lambdaCode
);
const eventRule = this.createEventBridgeRule(lambdaFunction, targetBranches);
this.createLambdaPermission(...);
}
private createIamRole(...): iam.CfnRole {
return new iam.CfnRole(this, `codecommit-pr-reviewer-role`, {
...
});
}
private createLambdaCode(lambdaCodePath: string): lambda.Code {
const fullPath = path.join(__dirname, '../', lambdaCodePath);
return lambda.Code.fromAsset(fullPath, {
bundling: {
image: cdk.DockerImage.fromRegistry('python:3.12-slim'),
command: [
'bash',
'-c',
[
'pip install -r requirements.txt -t /asset-output --platform manylinux2014_x86_64 --implementation cp --python-version 3.12 --only-binary=:all: --upgrade',
'cp -r *.py /asset-output/',
].join(' && '),
],
},
});
}
private createLambdaFunction(
role: iam.CfnRole,
code: lambda.Code
): lambda.CfnFunction {
const codeConfig = code.bind(this);
const lambdaFunction = new lambda.CfnFunction(this, `codecommit-pr-reviewer-function`, {
functionName: `codecommit-pr-reviewer`,
runtime: "python3.12",
handler: "lambda_function.lambda_handler",
role: role.attrArn,
timeout: 900,
memorySize: 1024,
description: 'Reviews CodeCommit PRs using Amazon Bedrock',
code: {
s3Bucket: codeConfig.s3Location?.bucketName,
s3Key: codeConfig.s3Location?.objectKey,
}
});
lambdaFunction.addDependency(role);
return lambdaFunction;
}
private createEventBridgeRule(
lambdaFunction: lambda.CfnFunction,
targetBranches: string[]
): events.CfnRule {
return new events.CfnRule(this, `codecommit-pr-reviewer-rule`, {
name: `codecommit-pr-reviewer-trigger`,
description: 'Trigger Lambda when CodeCommit PR is created or updated',
state: 'ENABLED',
eventPattern: {
source: ['aws.codecommit'],
'detail-type': ['CodeCommit Pull Request State Change'],
detail: {
event: ['pullRequestCreated', 'pullRequestSourceBranchUpdated'],
...
},
},
targets: [
{
id: 'PRReviewerLambda',
arn: lambdaFunction.attrArn,
},
],
});
}
private createLambdaPermission(...)
{
...
}
}
4.Lambdaの処理
プルリクエストをトリガーにして実行するLambdaでは、以下のコンポーネントで処理してレビュー結果をプルリクエストのコメントとして返します。
- PR Review Orchestrator
- CodeCommit Client
- Token Optimizer
- Bedrock Reviewer
PR Review Orchestrator
オーケストレーターは、各コンポーネントを制御して一連のレビュー処理を実行します。プルリクエスト内のファイルの差分を抽出して、Bedrock APIを実行して、レビュー結果を取得してプルリクエストにコメントとして投稿します。レビュー対象の差分が多くなりトークン数が肥大化する場合への対処として、Bedrock APIを実行する際に対象ファイルのフィルタやレビューの優先順を付けて、トークン最適化した状態でAPIを実行しています。
コードの概要は以下のようになります。
import ...
class PRReviewOrchestrator:
def __init__(self):
self.codecommit = CodeCommitClient()
self.optimizer = TokenOptimizer()
self.reviewer = BedrockReviewer()
def process_pr_event(self, event: Dict) -> Dict:
detail = event.get('detail', {})
repository_name = detail.get('repositoryNames', [])[0]
run_id = str(uuid.uuid4())[:8]
pr_id = detail.get('pullRequestId')
pr = self.codecommit.get_pull_request(pr_id)
target = pr.get('pullRequestTargets', [])[0]
source_commit = target.get('sourceCommit')
destination_commit = target.get('destinationCommit')
merge_base = target.get('mergeBase')
before_commit = merge_base if merge_base else destination_commit
file_changes = self.codecommit.get_differences(
repository_name, before_commit, source_commit
)
filtered_files = self.optimizer.filter_and_sort_files(file_changes)
chunks = self.optimizer.create_chunks(filtered_files)
findings = []
previous_summary = None
for chunk_idx, chunk in enumerate(chunks):
result = self.reviewer.review_chunk(
chunk, chunk_idx, len(chunks),
previous_summary
)
chunk_findings = result.get('findings', [])
summary = result.get('summary', '')
findings.extend(chunk_findings)
previous_summary = summary
grouped = self.reviewer.group_findings_by_file(findings)
total_comments = self._post_findings(
pr_id, repository_name, before_commit, source_commit,
grouped, self.reviewer
)
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Review completed',
'run_id': run_id,
'pr_id': pr_id,
'model_used': self.reviewer.model_name,
'files_reviewed': len(filtered_files),
'chunks_processed': len(chunks),
'total_comments': total_comments
})
}
def _post_findings(self, pr_id: str, repository_name: str,
before_commit: str, after_commit: str,
grouped_findings: Dict[str, List[Dict]],
reviewer: BedrockReviewer) -> int:
count = 0
total = sum(len(findings) for findings in grouped_findings.values())
for file_path, findings in grouped_findings.items():
for finding in findings:
comment = reviewer.format_finding_as_comment(finding)
actual_path = finding.get('original_path', file_path)
if actual_path.endswith(')'):
actual_path = actual_path.split(' (part ')[0]
line = finding.get('line', 1)
self.codecommit.post_comment_for_pull_request(
pr_id, repository_name, before_commit, after_commit,
comment, actual_path, line
)
count += 1
return count
def lambda_handler(event, context):
orchestrator = PRReviewOrchestrator()
return orchestrator.process_pr_event(event)
CodeCommit Client
CodeCommitクライアントは、プルリクエストの詳細な変更内容からの差分の取得とプルリクエストへのコメントの投稿を実行します。
コードの概要は以下のようになります。
import ...
class CodeCommitClient:
def __init__(self):
self.client = boto3.client('codecommit', region_name='ap-northeast-1')
def get_pull_request(self, pr_id: str) -> Dict:
response = self.client.get_pull_request(pullRequestId=pr_id)
return response['pullRequest']
def get_differences(self, repository_name: str,
before_commit: str,
after_commit: str) -> List[Dict]:
file_changes = []
paginator = self.client.get_paginator('get_differences')
page_iterator = paginator.paginate(
repositoryName=repository_name,
beforeCommitSpecifier=before_commit,
afterCommitSpecifier=after_commit
)
for page in page_iterator:
for difference in page.get('differences', []):
file_change = self._process_difference(
repository_name,
difference,
after_commit
)
if file_change:
file_changes.append(file_change)
return file_changes
def _process_difference(self, repository_name: str,
difference: Dict,
commit_id: str) -> Optional[Dict]:
change_type = difference.get('changeType')
before_blob = difference.get('beforeBlob', {})
after_blob = difference.get('afterBlob', {})
file_path = after_blob.get('path', '')
blob_size = after_blob.get('blobSize', 0)
diff_content = self._get_file_diff(
repository_name,
difference,
commit_id
)
return {
'file_path': file_path,
'change_type': change_type,
'blob_size': blob_size,
'diff': diff_content,
'before_blob': before_blob,
'after_blob': after_blob
}
def _get_file_diff(self, repository_name: str,
difference: Dict,
commit_id: str) -> str:
change_type = difference.get('changeType')
before_blob = difference.get('beforeBlob', {})
after_blob = difference.get('afterBlob', {})
if change_type == 'A': # 追加されたファイル
after_content = self._get_blob_content(
repository_name,
after_blob.get('blobId')
)
return self._format_added_diff(after_blob.get('path'), after_content)
elif change_type == 'D': # 削除されたファイル
...
elif change_type == 'M': # 修正されたファイル
...
def _get_blob_content(self, repository_name: str, blob_id: str) -> str:
...
def _format_added_diff(self, file_path: str, content: str) -> str:
lines = content.split('\n')
diff_lines = [
f"diff --git a/{file_path} b/{file_path}",
"new file mode 100644",
f"--- /dev/null",
f"+++ b/{file_path}",
f"@@ -0,0 +1,{len(lines)} @@"
]
for line in lines:
diff_lines.append(f"+{line}")
return '\n'.join(diff_lines)
def post_comment_for_pull_request(self, pr_id: str,
repository_name: str,
before_commit: str,
after_commit: str,
content: str,
file_path: Optional[str] = None,
file_position: Optional[int] = None) -> Dict:
comment_params = {
'pullRequestId': pr_id,
'repositoryName': repository_name,
'beforeCommitId': before_commit,
'afterCommitId': after_commit,
'content': content
}
if file_path:
comment_params['location'] = {
'filePath': file_path,
'filePosition': file_position or 1,
'relativeFileVersion': 'AFTER'
}
return self.client.post_comment_for_pull_request(**comment_params)
Token Optimizer
プルリクエスト内のレビュー対象となる差分のサイズが大きい場合、一度にBedrock APIに渡すとトークン数の上限を超過してしまう可能性があります。Token Optimizerは、プルリクエスト内のレビュー対象となる差分のサイズが大きい場合でも、Bedrock APIのトークン上限内に収まるように適切なチャンクに分割します。また、ライブラリ等のレビュー対象から外したいファイルを除外したり、優先度の高いファイルからレビュー対象にする処理も実行しています。レビューはトークン効率を優先し、英語で実行しています。これにより日本語に比べてトークン消費を抑えつつ、安定したレビュー結果を得やすくしています。
コードの概要は以下のようになります。
import ...
class TokenOptimizer:
SYSTEM_PROMPT_OVERHEAD = 1500 # プロンプトとメタデータ用のトークン数
def __init__(self):
self.encoder = tiktoken.get_encoding("cl100k_base")
self.max_context = 200000
self.buffer_percentage = 0.15
self.chunk_size = 2048
self.chunk_overlap = 256
self.max_tokens_per_request = 8192
self.effective_context = int(self.max_context * (1 - self.buffer_percentage))
def _count_tokens(self, text: str) -> int:
return len(self.encoder.encode(text))
def _should_ignore_file(self, file_path: str) -> bool:
ignore_patterns = ['*.min.js', '*.min.css', ...]
for pattern in ignore_patterns:
if fnmatch.fnmatch(file_path, pattern):
return True
return False
def _get_file_priority(self, file_path: str) -> int:
priority_extensions = ['.php', '.js', '.ts', ...]
for idx, ext in enumerate(priority_extensions):
if file_path.endswith(ext):
return idx
return len(priority_extensions) + 100
def filter_and_sort_files(self, file_changes: List[Dict]) -> List[Dict]:
max_file_size = 1500 * 1024
max_files = 200
filtered = []
for file_change in file_changes:
file_path = file_change.get('file_path', '')
if self._should_ignore_file(file_path):
continue
blob_size = file_change.get('blob_size', 0)
if blob_size > max_file_size:
continue
diff_content = file_change.get('diff', '')
file_change['token_count'] = self._count_tokens(diff_content)
file_change['priority'] = self._get_file_priority(file_path)
filtered.append(file_change)
sorted_files = sorted(
filtered,
key=lambda x: (x['priority'], -x['token_count'])
)
return sorted_files[:max_files]
def _create_empty_chunk(self) -> Dict:
return {
'files': [],
'token_count': self.SYSTEM_PROMPT_OVERHEAD
}
def create_chunks(self, file_changes: List[Dict]) -> List[Dict]:
chunks = []
current_chunk = self._create_empty_chunk()
for file_change in file_changes:
file_tokens = file_change['token_count']
file_path = file_change['file_path']
if current_chunk['token_count'] + file_tokens > self.chunk_size:
if current_chunk['files']:
chunks.append(current_chunk)
current_chunk = self._create_empty_chunk()
if file_tokens > self.chunk_size:
file_chunks = self._split_large_file(file_change)
chunks.extend(file_chunks)
continue
current_chunk['files'].append(file_change)
current_chunk['token_count'] += file_tokens
if current_chunk['files']:
chunks.append(current_chunk)
return chunks
def _split_large_file(self, file_change: Dict) -> List[Dict]:
file_path = file_change.get('file_path', 'unknown')
diff_content = file_change.get('diff', '')
hunks = self._split_diff_into_hunks(diff_content)
chunks = []
current_chunk = self._create_empty_chunk()
for idx, hunk in enumerate(hunks):
hunk_tokens = self._count_tokens(hunk)
was_truncated = False
if hunk_tokens > self.chunk_size:
was_truncated = True
lines = hunk.split('\n')
target_lines = int(len(lines) * 0.8 * self.chunk_size / max(1, hunk_tokens))
truncated_lines = lines[:max(1, target_lines)]
truncated_hunk = '\n'.join(truncated_lines) + '\n... [TRUNCATED - hunk too large for review]'
hunk = truncated_hunk
hunk_tokens = self._count_tokens(hunk)
if hunk_tokens > self.chunk_size:
continue
if current_chunk['token_count'] + hunk_tokens > self.chunk_size:
if current_chunk['files']:
chunks.append(current_chunk)
current_chunk = self._create_empty_chunk()
partial_file = {
'file_path': f"{file_path} (part {idx + 1}/{len(hunks)})",
'diff': hunk,
'token_count': hunk_tokens,
'original_path': file_path,
'is_partial': True
}
if was_truncated:
partial_file['warning'] = f"Content truncated due to size limit"
current_chunk['files'].append(partial_file)
current_chunk['token_count'] += hunk_tokens
if current_chunk['files']:
chunks.append(current_chunk)
return chunks
def _split_diff_into_hunks(self, diff_content: str) -> List[str]:
if not isinstance(diff_content, str):
diff_content = str(diff_content)
lines = diff_content.split('\n')
hunks = []
current_hunk = []
header = []
for line in lines:
if line.startswith('diff --git') or line.startswith('index ') or \
line.startswith('--- ') or line.startswith('+++ '):
header.append(line)
elif line.startswith('@@'):
if current_hunk:
hunks.append('\n'.join(header) + '\n' + '\n'.join(current_hunk))
current_hunk = [line]
else:
current_hunk.append(line)
if current_hunk:
hunks.append('\n'.join(header) + '\n' + '\n'.join(current_hunk))
return hunks if hunks else [diff_content]
Bedrock Reviewer
Bedrock Reviewerは、プルリクエストの差分を分割されたチャンクごとに、プロンプトと合わせてBedrock Runtime APIに渡してレビュー結果を取得し、プルリクエストのコメント用に整形して返します。さらに、複数チャンクに分割してレビューする場合でも一貫性を保てるように、前チャンクの要約をプロンプトに含めています。モデルには、Claude Sonnet 4.5を利用しています。
基本的なプロンプトは以下のようになります。
You are an expert code reviewer. Review code changes and provide constructive feedback.
Focus on:
- security vulnerabilities
- performance issues
- code quality and best practices
- potential bugs
- error handling
Severity: critical, high, medium, low, info
IMPORTANT: If an issue at a specific file:line was already identified (see below), do NOT report it again - including similar issues or different wording of the same problem.
Respond ONLY with valid JSON:
{
"findings": [
{
"file": "path/to/file",
"line": line_number,
"severity": "critical|high|medium|low|info",
"category": "security|performance|bug|quality|style",
"issue": "Description",
"suggestion": "Fix"
}
],
"summary": "Brief assessment"
}
コードの概要は以下のようになります。
import ...
class BedrockReviewer:
def __init__(self):
self.temperature = 0.7
boto_config = Config(...)
self.client = boto3.client('bedrock-runtime', region_name='ap-northeast-1', config=boto_config)
def review_chunk(self, chunk: Dict, chunk_num: int, total_chunks: int,
previous_summary: Optional[str] = None) -> Dict:
prompt = self._build_prompt(chunk['files'], chunk_num, total_chunks, previous_summary)
response = self._invoke_claude(prompt)
return self._parse_response(response)
def _build_prompt(self, files: List[Dict], chunk_num: int, total_chunks: int,
previous_summary: Optional[str]) -> str:
focus = [
'security vulnerabilities',
'performance issues',
'code quality and best practices',
'potential bugs',
'error handling',
]
severities = ['critical', 'high', 'medium', 'low', 'info']
instruction = f"""You are an expert code reviewer. Review code changes and provide constructive feedback.
Focus on:
{chr(10).join(f'- {area}' for area in focus)}
Severity: {', '.join(severities)}
IMPORTANT: If an issue at a specific file:line was already identified (see below), do NOT report it again - including similar issues or different wording of the same problem.
Respond ONLY with valid JSON:
{{
"findings": [
{{
"file": "path/to/file",
"line": line_number,
"severity": "critical|high|medium|low|info",
"category": "security|performance|bug|quality|style",
"issue": "Description",
"suggestion": "Fix"
}}
],
"summary": "Brief assessment"
}}"""
ctx = ""
if total_chunks > 1:
ctx = f"\n\nChunk {chunk_num + 1}/{total_chunks}"
if previous_summary:
ctx += f"\nPrevious: {previous_summary}"
files_content = "\n\n".join([
f"### File: {f['file_path']}\n```diff\n{f['diff']}\n```"
for f in files
])
return f"{instruction}{ctx}\n\n{files_content}"
def _invoke_claude(self, prompt: str) -> str:
MAX_PROMPT_LENGTH = 100000
if len(prompt) > MAX_PROMPT_LENGTH:
last_file_marker = prompt.rfind('### File:', 0, MAX_PROMPT_LENGTH)
if last_file_marker > 0:
prompt = prompt[:last_file_marker] + "\n\n[Additional files truncated due to size limit]"
else:
prompt = prompt[:MAX_PROMPT_LENGTH]
request_body = {
'anthropic_version': 'bedrock-2023-05-31',
'max_tokens': 4096,
'temperature': self.temperature,
'messages': [{'role': 'user', 'content': prompt}]
}
response = self.client.invoke_model(
modelId='jp.anthropic.claude-sonnet-4-5-20250929-v1:0',
body=json.dumps(request_body)
)
response_body = json.loads(response['body'].read())
content = response_body.get('content', [])
return content[0].get('text', '')
def _parse_response(self, response: str) -> Dict:
... # Bedrock APIからの戻り値をパースする
def group_findings_by_file(self, findings: List[Dict]) -> Dict[str, List[Dict]]:
grouped = {}
for finding in findings:
file_path = finding.get('file', 'unknown')
if file_path not in grouped:
grouped[file_path] = []
grouped[file_path].append(finding)
severity_order = ['critical', 'high', 'medium', 'low', 'info']
max_comments = 30
for file_path in grouped:
for finding in grouped[file_path]:
severity = finding.get('severity', 'info')
grouped[file_path].sort(
key=lambda f: severity_order.index(f.get('severity', 'info'))
)
grouped[file_path] = grouped[file_path][:max_comments]
return grouped
def format_finding_as_comment(self, finding: Dict) -> str:
... # 見つかったバグをコメント用にフォーマットする
5.まとめ
今回は、CodeCommit用に開発したPR-Agentについてご紹介しました。このPR-Agentはプロジェクト内で利用していますが、レビュー精度はまだ改善の余地があります。プルリクエスト内の差分だけを使ってレビューしているため、ファイルを部分的に修正する場合は、ファイル全体のコンテキストが理解できておらず、変数が定義されていない等の誤ったレビュー結果を返す状態です。今後は、レビュー精度を上げるために、変更箇所だけではなくファイル内の関連箇所や関連ファイルも含めてレビューするように改善していく予定です。
余談になりますが、AWS CodeCommitの今後についてによると、2025年11月からCodeCommitの一般提供が再開されているようです。まだCodeCommitの今後のロードマップは不明ですが、AI連携機能の強化も期待できそうです。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD


