2026.04.06
未来を予測してロボットが動く世界が!? – DreamDojo
こんにちは。
少し出遅れましたが,今回はNVIDIAが中心となって2月に発表した基盤世界モデルDreamDojoを紹介します。
公式サイトはこちら:
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
DreamDojo は,ロボットが動作を学習・検証するために使う「世界モデル」(= 現実世界の法則をそれっぽく再現したシミュレーション環境を生成する AI)の一種です。
「ロボット向けの基盤モデルを世界モデルでもやろう」という野心的なプロジェクトになっています。
1.これまでの世界モデルの課題
ここ数年,「世界モデル」系の研究はかなり盛り上がっていますが,実際にロボットで使うところまで持っていこうとすると,いろいろとつらい問題がありました。
代表的なところを挙げると:
- 使えるデータが圧倒的に少ない
- 実機ロボットを動かして撮影した動画データを大量に集める必要がある
- ロボットを長時間テレオペしてデータ収集するのは,労働が集約されるような形になり様々な意見あり
- アクションラベル(関節の動き)がない / 付けづらい
- 「このフレームのとき,ロボットは各関節をどれだけ動かしたか?」というラベルが必要
- 人間の一人称視点動画には当然そんな情報は入っていない
世界モデルにやってほしいのは,本来,「こういう動きをすると,世界はこう変わる」というマッピングを学ぶことです。
でも,そのためのデータ(特にアクションラベル付きのロボット動画)が足りていないし,集めるのもコストが高い。
DreamDojo は,このあたりの根本的なボトルネックを潰しに来ているモデルです。
2.DreamDojoのすごいところ
DreamDojo が面白いのは,「データ」と「アーキテクチャ」の両方で攻めてきているところです。ざっくり特徴をまとめると:
- 超でかいデータセットを自前で用意(DreamDojo-HV)
- 約 4.4 万時間分の動画
- 家庭,工場,小売店など,かなり多様な環境
- アクションラベル付きのデータが少なくても学習できる工夫
- まずはラベルのない人間視点動画から「潜在アクション」を学習
- その後,少量のロボット動画でロボット固有の動きを適応させる
- リアルタイム生成ができる
- 640×480 で 10 FPS という,実時間に近い速度
- Self-forcing パラダイムに基づく蒸留で高速化している
この結果,
- 多様なロボット/環境に適用可能
- しかもリアルタイムで世界を生成できる
という,かなり実用寄りの性質を持った世界モデルになっています。
この特徴を活かすと,例えばこんな使い方が考えられます。
- 生成したシミュレーション空間内で,ロボットをリアルタイムにテレオペしてデータ収集
- ロボットの行動計画生成
- 現実に動かす前に,シミュレーション空間で複数パターンを並列実行
- 一番良さそうな行動だけ実機に流す
- 学習済みポリシーの評価
- シミュレーション上で大量のテストケースを叩いてみる
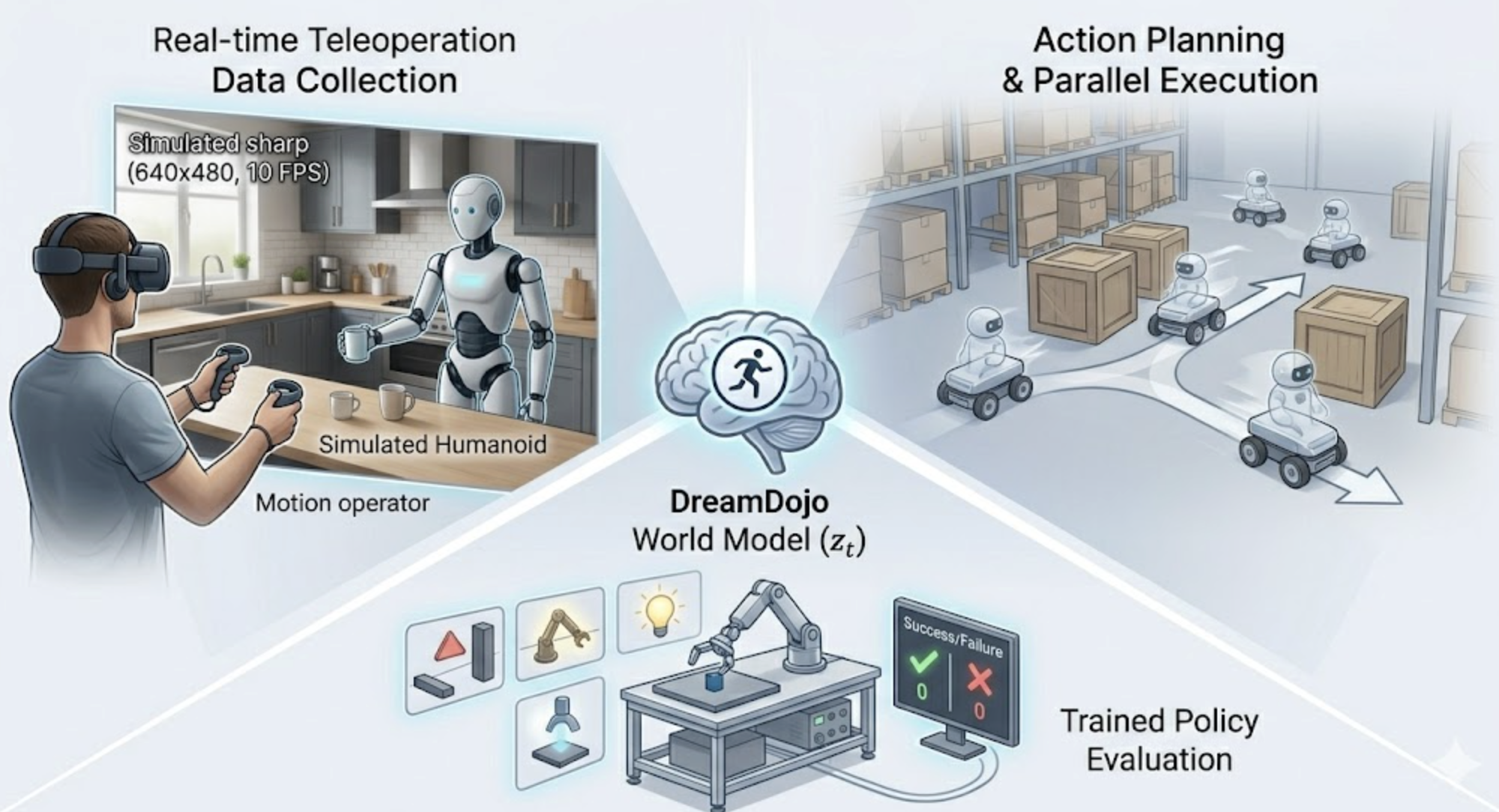
DreamDojoのユースケース
要するに,「ほどよくフォトリアルで,物理もそれっぽいシミュレータ」を汎用的に量産するエンジンとして使える,という感じです。
3.DreamDojo-HVについて
その基盤になっているのが,先ほどから出てきている DreamDojo-HV というデータセットです。ざっくり言うと:
- クラウドソーシングで集めた,人間の主観視点(一人称視点)のビデオが中心
- アクションラベルは基本的に付いていない
- そもそも人間とロボットでは構造が違うので,生の人間動作をそのままロボットにマッピングするのは無理
それでも DreamDojo は,この「ラベルなし・主観視点動画」をうまく使って,「どういう動きをすると,世界がどう変わるか?」という,かなり一般的な知識を事前学習しています。
- りんごを押したら転がる
- 布の端をつまんで引っ張ると,ひらっと垂れ下がる
- ドアノブを回して引くと扉が開く
…といった「世界の振る舞いパターン」を大量に覚えさせておきます。
その上で,「実際のロボット+アクションラベル付きの少量データ」を使って微調整(post トレーニング)することで,現実のロボットでも破綻しない世界モデルを作っている,という流れです。
ここでキモになるのが「潜在アクション」という考え方です。
4. 技術のキモ:潜在アクション
DreamDojo では,人間視点動画から直接「関節角度」みたいなものを推定するのではなく,「どういう動きをすると,世界がどう変わるか?」に対応する 潜在アクション(latent action) を定義して,それを学習しています。
この潜在アクションを抽出する部分には,VAE(変分オートエンコーダ)+時空間 Transformer(約 700M パラメータ) を使ったモデルが入っています。
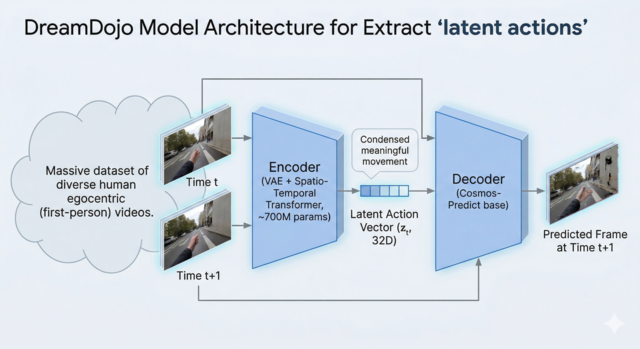
潜在アクションの抽出と利用
構成はざっくりこんな感じです。
- エンコーダ:連続した 2 フレーム(時刻 t と t+1)の画像を入力,そこから「この 1 ステップで何をしたか?」を表す潜在アクションベクトルを出力
- デコーダ:現在のフレーム(時刻 t)と潜在アクションベクトルを入力,次のフレーム(時刻 t+1)を予測
このとき,予測したフレームと,実際のフレームとの誤差を見ながら学習を進めていきます。
DreamDojoでは,潜在アクションベクトルの次元は32次元と,かなりコンパクトに設計されています。
小さいベクトルで次のフレームをそれなりに予測しようとすると,自然と腕や手,物体の「意味のある動き」だけが凝縮された表現になりやすい,というわけです。
この「潜在アクション」をきれいに抽出できると,
- まずは人間視点動画から世界の物理・因果を学ぶ(pre トレーニング)
- その後,ロボット動画で「潜在アクション」とロボット関節の対応を学ぶ(post トレーニング)
という2段構えがうまくハマります。
5. 学習パイプライン:pre トレーニング / post トレーニング / 蒸留
DreamDojo全体の学習フローは,大きく分けて3段階あります。
世界モデルのpreトレーニング
世界モデル本体は,NVIDIAのCosmos-Predict2.5という動画生成モデルをベースにしています。Cosmosは,物理法則を考慮したフォトリアリスティックな動画生成モデルです。
この Cosmos 系モデルは,本来は「過去数フレームを見て,その先のフレームを予測する」という形で学習されていますが,DreamDojoではここに「アクション」の情報を足していきます。
具体的には,モデル内部のtime embedding(タイムステップ情報)に対して,潜在アクションベクトルからMLPを通して生成したベクトルを「加算」してやるという形で,行動の影響を条件付けしています。
この工夫で,「時間が進むことで変わる部分」と「行動によって変わる部分」を同じ空間で扱えるようにしています。
ロボットに合わせた post トレーニング
次のステップが,ロボット固有の「関節角度」と世界モデルを結びつけるpostトレーニングです。
ここでは,
- それまで使っていた潜在アクションからベクトルを生成するMLPをいったん外す
- 代わりに,ロボットの実際の関節角度データを入力するMLPを接続
- そのMLPの出力をtime embeddingに加算する
という構成に差し替えます。
つまり,
- preトレーニング:「潜在アクション」という抽象的な行動表現で世界を動かす
- postトレーニング:「ロボットの関節角度」から抽象的な行動表現にマッピングし直す
という感じです。
こうすることで,物理的な常識(りんごは転がる,布は垂れ下がる…)は保ったまま,各ロボットごとの関節角度・稼働範囲・制約を正しく解釈できるようになります。
リアルタイム性を実現する蒸留(Self-forcing)
最後に,実用上かなり重要なのが リアルタイム性 の確保です。
元の世界モデルは巨大なので,そのままだとかなり重いという問題があります。そこでDreamDojoでは,Self-forcingパラダイムに基づく蒸留を使って,より軽量なモデルに知識を圧縮しています。
これにより,640×480解像度で10FPS程度という実時間に近いスピードで世界を生成可能というところまで持っていっています。
ここまで来ると,ロボットのテレオペ,並列シミュレーションによる行動計画,学習済みポリシーのリアルタイム評価みたいな用途にも,かなり現実味が出てきます。
6. まとめ・所感
最後に,個人的なまとめです。
- 人間の主観視点データを使って,ロボットの学習に使える世界モデルを pre トレーニングするアーキテクチャが提案された
- 人間視点の動画データはすでに大量に存在していて,集めやすい
- ロボットの種類によらない「共通の世界モデル」をベースとして持てる
- しかも,高速に世界を生成できるので,テレオペやリアルタイムシミュレーションなどアプリケーションレイヤでもかなり使えそう
このようなモデルが実用化されてくると,ロボット側の制御ロジックを直接書き換えるのではなく,「世界をよく知っている基盤モデル」を一枚かませて,その上でプランニングやテレオペ,ポリシー学習を行うというスタイルのフレームワークが,いろいろ出てきそうだな,という印象です。
ロボットに興味がある方は,一度公式ページのデモ動画を眺めてみると,「世界モデルの解像度が上がると,ロボットのやり方も変わりそうだな」という感覚がつかめると思います。
グループ研究開発本部 AI研究開発室では,フィジカルAI・ロボティクスのリサーチエンジニア・リサーチサイエンティストを募集しています。ヒューマノイドの全身制御やその他の要素技術,社会実装にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD