2026.03.16
Gemini Embedding 2 を使ってみた〜テキスト・画像・音声・動画・PDFの類似度比較〜
TL;DR
- GoogleはGemini Embedding 2を発表しました。テキストだけではなく、画像、音声、ビデオやPDFなどの異なるモーダルの埋め込みを同一の空間に埋め込めるマルチモーダル埋め込みモデルです。社内ドキュメントを参照し業務知識を活用するための重要な技術の一つであるRetrieval-Augmented Generation (RAG)において、テキスト以外の情報の活用に応用できると期待されます。
はじめに
こんにちは、グループ研究開発本部のAI研究開発室のT.I.です。先日、Googleは「Gemini Embedding 2: Our first natively multimodal embedding model」を発表しました。生成AIに自社内のドキュメント・情報を活用させるための重要な技術の一つであるRetrieval-Augmented Generation (RAG)は、テキストの埋め込みを用いて、関連するドキュメントを抽出し、それを生成AIの回答の元にする技術です。Gemini Embedding 2は、テキストだけではなく、画像、音声、ビデオやPDFなどの異なるモーダルの埋め込みを同一の空間に埋め込めるマルチモーダル埋め込みモデルです。画像を与えて意味が近い文章を抽出したり、音声データや動画データなどのデータを検索したりなど、様々なモーダルのデータの横断的な利用が期待できます。
Gemini Embedding 2の対応しているモーダルは以下のようになっています。
- テキスト: 8192トークンまで
- 画像: PNG/JPEGで、一度に6枚まで可能
- 音声: 文字起こしの事前処理は不要(長さの制限は特に記載されておらず)
- ビデオ: 120秒までのMP4/MOV形式
- PDF: 6ページまで
埋め込みの次元数は3072, 1536, 768の3種類が用意されています。必要とされる精度とパフォーマンスに応じて選択できます。
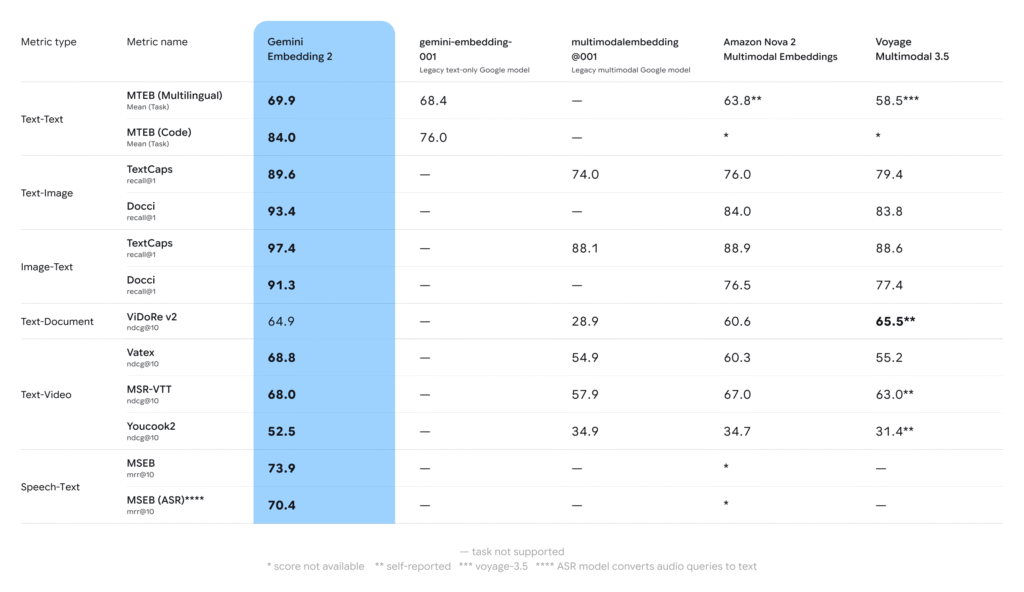
Gemini Embedding 2のパフォーマンスは以下の通りです。旧来のGemini Embedding 001 よりも MTEB(Code)は大幅に改善、他のモーダル間のベンチマークについても、旧来のモデルからは大きく改善しています。
Gemini Embedding 2を使ってみる
さて、さっそくですがGemini Embedding 2を使ってみます。Pythonの場合、google-genaiライブラリをインストールし、モデルはgemini-embedding-2を指定します。 GEMINI_API_KEYの環境変数にAPIキーを設定しておく必要があります。詳細は公式ドキュメントを参照してください。(Gemini API Embeddings)
from google import genai
from google.genai import types
client = genai.Client()
with open("data/photo_jasper.png", "rb") as f:
image_bytes_jasper = f.read()
with open("data/aloha.png", "rb") as f:
image_bytes_aloha = f.read()
with open("data/zundamon_christmas.mp3", "rb") as f:
audio_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"クリスマスツリーがきれいなのだ!",
types.Part.from_bytes(
data=image_bytes_jasper,
mime_type="image/png",
),
types.Part.from_bytes(
data=image_bytes_aloha,
mime_type="image/png",
),
types.Part.from_bytes(
data=audio_bytes,
mime_type="audio/mpeg",
),
],
)
print(result.embeddings)
通常のテキスト、画像データ、そして「クリスマスツリーがキラキラ光るお部屋で、トナカイ柄の赤いセーターを着たお兄さんがコーヒーを持ってニコニコしているのだ。とってもあったかそうな冬のひとときなのだ!」(by ずんだもん)
(こんな感じのセリフです Voicevoxで作成)
という音声ファイルなど、異なるモーダルのデータを一度に入力し埋め込みを生成できます。生成された埋め込みは、テキスト、画像、音声のモーダルに関係なく、同一の空間に埋め込まれます。得られた埋め込み間のcosine類似度から、異なるモーダルのデータ間の意味的な類似度を測定できます。
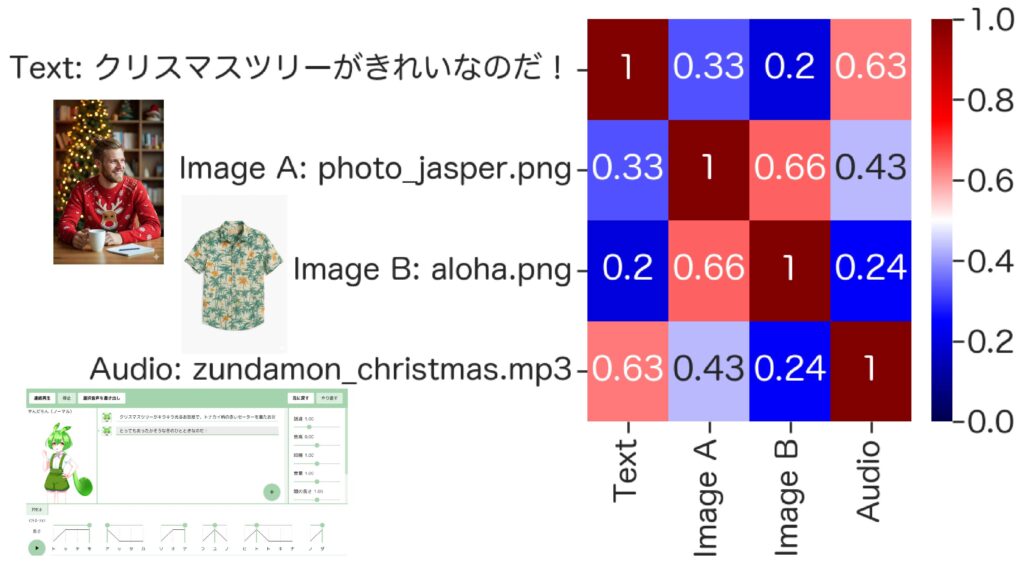
一部のセリフが重なるテキストと音声の埋め込みの類似度は他の画像などと比べると高く、またクリスマスっぽい雰囲気の画像の方が、アロハの画像よりも音声との類似度が高くなるなど、それらしい結果が得られています。
画像だけでなく、動画も埋め込みが計算可能ですので、試してみます。昔、FramePackで作成したロボットが荒野で手を叩いている動画を入力します。また、よく似たロボットの類似した画像のファイルも用意しました。
with open("data/robot_sample_frame.jpg", "rb") as f:
image_bytes_robo = f.read()
with open('data/robot_claps_hands.mp4', "rb") as f:
video_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"クリスマスツリーがきれいなのだ!",
"これはね、かわいいロボットの子なのだ!",
"ロボットが手を叩いている動画なのだ!",
types.Part.from_bytes(
data=image_bytes_robo,
mime_type="image/jpeg",
),
types.Part.from_bytes(
data=image_bytes_aloha,
mime_type="image/png",
),
types.Part.from_bytes(
data=video_bytes,
mime_type="video/mp4",
),
],
)
print(result.embeddings)
さて、埋め込みの類似度はどうなっているでしょうか? 類似している動画とロボットの画像の類似度は高い点は期待通りですが、テキストの内容との類似度に関しては、「手を叩いている動画なのだ!」が「かわいいロボットの子なのだ!」よりも動画との類似度が高くなっている点は、動画の内容をある程度理解していることが伺えます。

複数のモーダルの埋め込みを1つにまとめることも可能です。図とキャプション、動画とその説明文など、複数のモーダルの情報を統合して、意味的な内容を表す埋め込みを生成できます。
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"ロボットが手を叩いている動画なのだ!",
types.Part.from_bytes(
data=image_bytes,
mime_type="image/jpeg",
),
types.Part.from_bytes(
data=video_bytes,
mime_type="video/mp4",
),
types.Content(
parts=[
types.Part(text="ロボットが手を叩いて踊っている"),
types.Part.from_bytes(
data=video_bytes,
mime_type="video/mp4",
),
]
)
],
)
print(result.embeddings)

確かに、動画とキャプションを加えることで、テキストの「ロボットが手を叩いている動画なのだ!」の埋め込みと、動画と画像の埋め込みの類似度が高くなっています。より精度の高い検索にはこのような複数モーダルの情報を統合した埋め込みが有効そうです。
最後に、PDFの埋め込みも試してみます。注意点として最大6ページまでのPDFしか対応していないです。「Attention is all you need」の論文のPDFを入力してみますが、冒頭6ページではモデル構造の解説まででとどまります。そのPDF埋め込みと、PDFから変換して作成したmarkdownテキスト、それからそれっぽい学術的なテキストをいくつか用意して、埋め込みを生成して類似度を計算してみます。
with open('data/1706.03762v7_p1-6.pdf', 'rb') as f:
pdf_bytes = f.read()
result = client.models.embed_content(
model='gemini-embedding-2-preview',
contents=[
types.Part.from_bytes(
data=pdf_bytes,
mime_type='application/pdf',
),
attention_is_all_you_need,
"Attention is all you need という論文は、Transformerアーキテクチャを提案し、自然言語処理に革命をもたらした。",
"Chain-of-Thoughtプロンプトは、複雑な推論タスクに対してモデルが中間ステップを生成するよう促すことで、性能を大幅に向上させる技法である。",
"RNAワールドの中心的な分子であるRNAは、遺伝情報の保存と伝達に加えて、触媒活性や遺伝子発現調節など多様な機能を持つ。",
"single-cell RNAシーケンシングは、個々の細胞のトランスクリプトームをプロファイリングする技術であり、細胞異質性と発生過程の理解に革命をもたらした。",
"AdS/CFT対応は、重力理論と量子場理論の双対性を示し、弦理論と量子重力の理解に重要な洞察を提供する。",
"g-2実験は、ミュオンの異常磁気モーメントを高精度で測定し、標準模型の予測と比較することで新物理の兆候を探る。",
"g-2実験の結果の差は、結局のところ格子QCDの計算精度の問題であったとする最近の論文が発表された。",
]
)
print(result.embeddings)
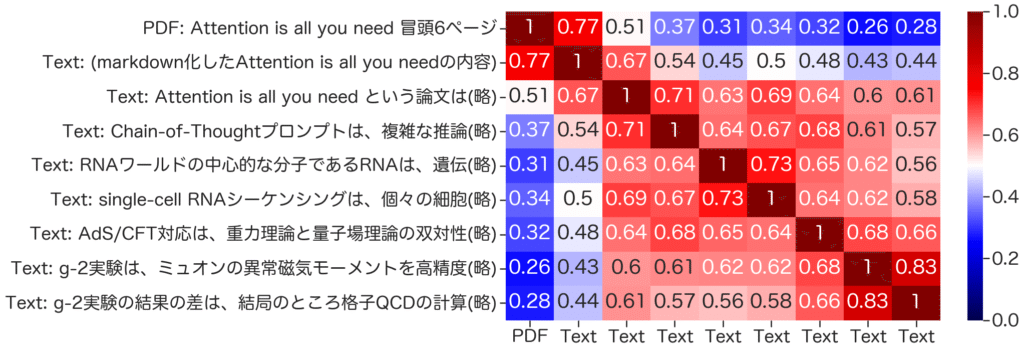
これらのPDF、テキストとの類似度を計算してみると、PDFの内容に関連するテキストの方が、他のテキストよりもPDFの埋め込みと類似度が高くなっていることがわかります。学術的な内容に関するテキストに関しては、同一分野間での類似度が高くなっています。
まとめ:RAGの可能性と課題
Gemini Embedding 2は、テキストだけではなく、画像、音声、ビデオやPDFなどの異なるモーダルの埋め込みを同一の空間に埋め込めるマルチモーダル埋め込みモデルです。これにより、マルチモーダルなRAGが可能となると期待されます。例えば、画像を与えて意味が近い文章を抽出し、それを元に回答させるといった活用が考えられます。
さて、RAGを利用して社内ドキュメントの知識を生成AIで活用しよう!というプロジェクトが仮にあったとします。しかし、往々にしてよくある問題ですが、バージョン管理がされていない、WordやExcel、PDFなど様々な形式で保存されている。などの理由で中々に期待通りの結果を得ることが難しいケースがあります。今回のGemini Embedding 2では、PDFの埋め込みも可能となりましたが、最大6ページまでと制限があり、活用のためには創意工夫が必要になりそうです。まずは、AIが利用しやすい形式でのドキュメント整理が重要かと思います。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD