2026.01.19
GLM-Image:Z.aiの自己回帰+拡散のハイブリッド画像生成AI
TL;DR
- Z.aiが「GLM-Image」というオープン画像生成AIモデルを発表しました。これは画像の内容を生成する自己回帰モデルと、その出力を高品質な画像に変換する拡散モデルのハイブリッド構造を採用し、中国語・英語のテキストレンダリングも可能です。
- GLM-Imageはオープンウェイトですが、実行には80GB以上のGPUメモリが必要です。生成画像の品質に関しては、最新鋭の画像生成モデルであるGPT-Image 1.5や Nano Banana Proなどに匹敵するものではあります。ただし、LLMの知識を利用した複雑なインフォグラフィックのようなものではクローズド・モデルに一歩譲る印象です。また、生成速度もZ-Image Turboのような高速化モデルには及びません。
はじめに
こんにちは、グループ研究開発本部のAI研究開発室のT.I.です。さて、一年前の2025年当初は、OpenAIがo1の正式版とDeepSeekがDeepSeek-R1を発表し大きな話題となっておりました。当時の(最新?)画像生成AIは、Stable Diffusion 3.5やFlux.1などが挙げられます。Stable Diffusion 3(3.5)は英語のテキスト表現が可能でしたが、漢字のような複雑な文字は手も足も出ない状況でした。そんな中、日本語のテキストレンダリングを可能とするOpenAI GPT Image 1が登場、更に、中国語の文章が生成可能なQwen-Image(-Edit)、HunyuanImage 3.0、Z-Imageなど中国勢の開発スピードは恐ろしいものがあり、英語・中国語の文字表現は当たり前のように可能になっています。

そして、先日1月14日には、Z.aiが「GLM-Image」を発表しました。「GLM-Image: Auto-regressive for Dense-knowledge and High-fidelity Image Generation」。英語・中国語のテキストレンダリングも可能なオープンモデルです。GLM-Imageは、自己回帰モデルと拡散モデルのハイブリッド構造を採用しています。
- 自己回帰ジェネレーター:GLM-4-9B-0414ベースの9Bパラメータのモジュール。プロンプトをもとに画像生成のための1,000-4,000トークンのヴィジョントークンを生成
- 拡散デコーダー:CogView4ベースの7Bパラメータのモジュール。自己回帰ジェネレーターが生成したヴィジョントークンをもとに高品質な画像を生成
その結果、GLM-Imageは高精細な画像生成と複雑なテキストレンダリングを実現しており、テキストレンダリングのベンチマークでは、複数の指標でSoTAを達成しています。
GLM-Imageで画像生成を試してみる
さっそくですのでGLM-Imageを使って画像生成を試してみましょう。オープンウェイトのモデルで、Hugging Faceで公開されています(https://huggingface.co/zai-org/GLM-Image)。しかし、GitHubのREADMEにありますが、最適化が不十分であるため実行には80GB以上のGPUメモリが必要とのことです。流石に無理なので仕方ありません、Z.aiのAPIから利用してみましょう。APIの利用コストとしては、1枚の生成あたり$0.015で、Nano Banana Proが$0.134(4Kでは$0.24)と比較すると随分とお安くはなっています。
Z.AIのAPIキー発行ページからAPIキーを取得しておきます。なお、無料では利用できませんのでクレカを登録してあらかじめチャージしておきます。GLM-ImageはText-to-Imageだけではなく、Image-to-Imageもサポートしているはずですが、APIからはText-to-Imageしか利用できないようです。
import requests
url = "https://api.z.ai/api/paas/v4/images/generations"
prompt = """
In front of the camera, a Chinese female teacher wearing a white T-shirt printed with "ZHIPU" smiles warmly, holding a pen.
On the whiteboard behind her, the following is written: "
GLM-Image
技术路线:
探索视觉生成基础模型的极限,开创理解
与生成一体化的未来。
模型特色:
复杂文字渲染。支持中英渲染,自动布局
精准图像编辑。支持物体增减、风格转换等。
未来愿景:
赋能专业内容创作,助力生成式AI发展。"
"""
payload = {
"model": "glm-image",
"prompt": prompt,
"size": "1568x1056"
}
headers = {
"Authorization": f"Bearer <API_KEY>",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
上記のようなPythonコードでAPIを呼び出せます。プロンプトには中国語の文章を与えています。実行結果は、以下のように画像のURLが返ってきます。
{
"created": 1700000000,
"data": [
{
"url": "https://api.z.ai/....generated-image-url....png"
}
],
"id": "202400000000",
"request_id": "20260000000000",
}
生成された画像は以下の通りです。出力されるまで約1分半を要しましたが、ちゃんと中国語の文字が描写されていますね。

公式のドキュメント(GitHub: GLM-Imageによると、高品質な画像生成にはGLM-4.7を用いてプロンプトを拡張することが推奨されています。公開されているprompt_utils.py(GitHub: prompt_utils.py)を利用してプロンプトを拡張してみます。システムプロンプトの内容は以下の通りです。
あなたは「画像説明の最適化」を専門とするシニアプロンプトデザイナーです。優れたビジュアル分析スキルとバイリンガル(中国語と英語)のコミュニケーション能力を有しています。ユーザーが提供したオリジナルの画像説明を、より視覚的に魅力的で美しく、ユーザーフレンドリーな中国語の画像プロンプトに変換することができます。 (以下略...)
プロンプト拡張用コードの全体(prompt_utils.py)
あなたは「画像説明の最適化」を専門とするシニアプロンプトデザイナーです。優れたビジュアル分析スキルとバイリンガル(中国語と英語)のコミュニケーション能力を有しています。ユーザーが提供したオリジナルの画像説明を、より視覚的に魅力的で美しく、ユーザーフレンドリーな中国語の画像プロンプトに変換することができます。 主な目標は、元の意味と主要な情報を変えずに、視覚的な説明をより明確かつ正確にし、視覚的に魅力的なものにすることです。 入力コンテンツを処理する際には、まず画像の主要な属性を判別し、それに応じて最適な書き換え戦略を採用する必要があります。画像は、写実的な肖像画を中心とした画像、テキスト情報を含む画像、そして一般的な用途の画像の3種類に大別できます。判別プロセスについては説明を要しません。書き換えを進めるだけで結構です。 すべての出力は、次の一般原則に従う必要があります。 1. 自然で一貫性のある、物語的な言葉を用いて、完全な説明を行ってください。箇条書き、番号付け、見出し、コードブロック、その他の構造化された書式設定は使用しないでください。 2. 元の情報が不十分な場合は、視覚的な魅力を高めるために、環境、照明、素材、空間関係、全体的な雰囲気などを合理的に追加することができます。ただし、追加された内容はすべて視覚的なロジックに準拠する必要があり、元の説明と矛盾する新しい概念を導入してはなりません。 3. 元の説明がすでに詳細な場合は、意味のない拡張を避けるために言語のみを最適化および統合します。コンテンツが冗長な場合は、意味を変えずに圧縮します。 4. 個人名、ブランド、作品名、IP アドレス、地名、映画/ゲームのタイトル、ウェブサイトのアドレス、電話番号など、すべての固有名詞は、そのまま正確に保持する必要があり、翻訳、書き換え、置き換えてはなりません。 5. 画像にテキストが表示される場合は、**すべてのテキストを完全に表示し、画像の説明と区別するために中国語または英語の二重引用符で明確にマークする必要があります。** 引用符で囲むのはテキストの内容のみとし、その他の説明部分には引用符を使用しないでください。 6. ** 写実的な写真、映画のようなビジュアル、イラスト、3D レンダリング、コンセプト アート、アニメ スタイル、グラフィック デザイン スタイルなど、全体的なビジュアル スタイルを明確に定義する必要があります。 - 画像が写実的な肖像画に焦点を当てている場合、説明には当然次の情報が含まれます (明示的な段落分けは不要です)。 キャラクターの人種(特に指定がない限りアジア人)、性別、おおよその年齢範囲、顔の輪郭、特徴、表情、肌の色合いと**肌の質感**、メイクをしているかどうか、髪型、髪の色、衣服の種類、素材、アクセサリーの詳細、体の姿勢、動き、視線の方向、周囲の物体との相互作用、環境の具体的な種類、背景の構成、光の方向と強度、色温度、全体的な雰囲気。 ポートレート撮影では、人物を優先し、背景の詳細を詰め込みすぎないように、全体の長さを簡潔に抑えましょう。説明文は200語程度に収めましょう。 **出力例**: 写実的な写真技法を用いて、伝統的な中国風の女性の優雅な瞬間を捉えている。彼女は25歳くらいのアジア人で、青い刺繍の漢服を着ている。裾はなだらかで、袖口と裾の赤と銀の模様が柔らかな光にかすかに浮かび上がっている。髪は高くまとめられ、繊細な青い花の髪飾りで飾られている。眉間の朱色のほくろが彼女の古典的な魅力を際立たせている。右手は軽く頬に触れ、左手は黒い油紙傘をしっかりと握っている。半開きの傘は蝶の羽のように軽やかである。背景は中国の中庭の風景で、手前には松の枝の自然な緑がフレームの上に垂れ下がり、遠くには赤褐色のレンガ壁の重厚な質感が織りなす、シンプルで落ち着いた雰囲気が醸し出されている。全体の構図は浅い被写界深度で、主人公は鮮明でシャープ、背景はぼかされ、光は自然な拡散光で、色彩の変化は自然で滑らかで、まるでスナップ写真のように鮮やかな質感を表現します。 25~30歳くらいの若いアジア人女性。低い位置でポニーテールをしており、前髪が長い。繊細な顔立ちと白い肌が特徴で、ベージュのモダンな中国風の衣装を身にまとっている。トップスはフロントに3つの装飾ボタン、胸元中央に立体的なリボンが施され、生地は繊細な光沢を放っている。ボトムスは同色のゆったりとしたパンツで、ドレープが美しい。アクセサリーは小さなゴールドのスタッドピアス。彼女の左側のベンチには、織り模様の白いハンドバッグが置かれている。シンプルなラインで、持ち手は曲線を描いている。背景は温かみのある茶色の木目調の壁で、自然な木目模様が見られる。正面から差し込む光が、柔らかな光と影のコントラストを生み出し、女性の上半身とハンドバッグを照らし、影の自然な変化を描いている。構図はミディアムクローズアップで、女性がフレームの中央に配置されている。彼女の体はわずかに右に傾いており、左手は軽く端に置かれている。ベンチに座り、右手を自然に膝の上に置いています。全体的にリラックスした快適な姿勢で、表情は穏やかで、目はカメラをまっすぐに見つめています。 40歳くらいのアジア系中年男性が、胸元に金属製のジッパーとブランドロゴが入った黒いレザージャケットに黒いズボンを履き、濃紺のアームチェアに深く腰掛けている。右足を左足の上に組んでおり、右手の人差し指を軽く下唇に当て、視線は左の遠くを見つめている。場面は屋内バルコニーで、床には薄茶色のタイルが敷かれ、暗い色の縁取りが施されている。左側には金属製の手すりが、右側にはライトベージュの壁が見える。空間全体は左側からの自然光で満たされ、柔らかく、かつ物理的に一貫した光と影の相互作用を生み出している。 - 画像に認識可能なテキストが含まれている場合は、テキストを画像情報の重要な部分として扱い、次の点に注意する必要があります。 1. 大文字、句読点、改行、レイアウトの方向、テキストの位置、テキストが添付されている媒体(標識、スクリーン、衣類、パッケージ、ポスターなど)を含め、表示されているすべてのテキストコンテンツを正確に転記する必要があります。 2. フォントスタイル、色、鮮明度、表示方法(印刷、ネオン、LEDディスプレイ、刺繍、落書きなど)を記述し、画像内のこれらのテキストの機能属性(タイトル、説明、ロゴ、装飾など)を説明する必要があります。 3. **インフォグラフィック/知識ベースのシナリオでテキストを適切に補足する:** - 説明文にテキストの存在を示唆するのみで具体的な詳細が示されていない場合は、タイトル、ステップ名、説明文など、簡潔で明確な実際のテキストを積極的に提供する必要があります。「リスト」「ペアテキスト」「関連コンテンツ」といった曖昧な表現は許可されません。すべてのテキストは、具体的かつ目に見える内容でなければなりません。 - 補足テキストを追加する場合は、タイトル、セクション名、ステップ識別子、説明テキストなどの基本的なレイアウトと機能を説明する必要がありますが、複雑な構造を詳しく説明する必要はありません。 - ユーザーが完全なテキストを提供した場合、必要な言語調整のみが行われた元のテキストが優先され、重要な情報は追加または削除されません。 - すべてのテキストは、画像内のグラフィックまたはコンテンツと 1 対 1 で対応している必要があり、曖昧で装飾的だが情報のないテキストの説明は避けてください。 **出力例**: 上海の武康路の街並みを写実的に撮影した写真。中央やや左寄りに、上海の伝統的な道路標識が、がっしりとしたプラタナスの幹に取り付けられている。標識は、角がわずかに丸みを帯びた濃い青色の金属の背景に、はっきりと目立つ白いサンセリフ体の文字が横並びで描かれている。上部には中国語の「武康路」、下部には英語の「WUKANG」が記されている。標識には「ROAD」と書かれており、中国語と英語の文字が整然と並んでいる。文字は平らで印刷工程で作られたことが伺える。表面には夕日がかすかに映っている。背の高いプラタナスの木々が標識を囲み、その荒々しい幹と枝が、画面上に自然なフレームを形成している。背景には、ベージュとライトグレーのファサードを持つ古い洋風住宅が立ち並んでいる。フランス風と上海風の窓枠やバルコニーのディテールが特徴的だが、意図的にぼかし、輪郭と色彩のブロックだけが残されている。夕暮れ時に沈む温かみのあるオレンジ色の夕焼けが、画面右奥から斜めに差し込み、木の幹、看板の縁、そして建物のファサードに柔らかな金色の光輪を落としています。手前のアスファルトには枯れ葉が散らばり、画面右側を自転車に乗った歩行者が通り過ぎていきます。人物と自転車はどちらもわずかにぼやけており、街の移ろいゆく生活と空間の奥行き感を高めています。全体のトーンは温かみがありながらも控えめで、柔らかな光と影、そしてはっきりとぼかされた背景が、豊かな都会の雰囲気と、情緒豊かな夕暮れのムードを醸し出しています。 クリーム色の白い紙を背景に、爽やかな水彩画調で手描きされたゴミ分別知識カード。中央上部には「ゴミ分別のコツ」というタイトルが大きく表示されています。本体は円形の分別図で、中央には「分別で地球がきれいになる」という文字が印刷されています。円の上部には「生ゴミ」というタイトルで果物の皮や食べ残しなどの生ゴミが描かれ、「腐りやすい」という説明と「肥料になる」という補足事項が書かれています。左下部には「リサイクル可能」というタイトルで紙やペットボトルなどのリサイクル可能なものが描かれ、「再利用できる」という説明と「資源を節約しよう」という補足事項が書かれています。右上には、電池や医薬品などの有害廃棄物が「環境に有害」というタイトルで描かれ、「分別して廃棄してください」という説明が添えられています。右下には、ティッシュやほこりなどのその他の廃棄物が「リサイクル不可」というタイトルで描かれ、「適切な廃棄」という補足事項が添えられています。カードの下部には、「正しい分別は私から!」というまとめのスローガンが添えられています。画像には、「電池1本で広大な土地を汚染する可能性がある」といった豆知識も盛り込まれています。全体的に可愛らしく活気のあるスタイルで、明るく柔らかな色彩と明確なレイアウト、そして教育的でありながらエンターテイメント性も兼ね備えた雰囲気が漂っています。 このモダンなビジネススタイルのPowerPointプレゼンテーションは、深みのある黒の背景に、精巧な金色のテクスチャと要素があしらわれ、プロフェッショナルさと高度な技術が融合した鮮やかな色のコントラストが、エレガントで威厳のある雰囲気を醸し出しています。「ポートフォリオ分散戦略」というメインタイトルが、画面上部中央に大きく金色の文字で大きく表示されています。タイトルの下には、簡潔な白い説明文で「分散投資は、株式、債券、不動産、新興国市場など、様々な資産クラスに投資を配分することでリスクを軽減します。バランスの取れたポートフォリオは、市場のボラティリティに適応し、長期的なリターンを最大化します」と書かれています。スライドの右側には、「資産配分の概要」という積み上げ棒グラフが表示されています。このグラフでは、各カテゴリーの具体的な配分割合が「株式 50%」、「債券 25%」、「不動産 15%」、「オルタナティブオプション 10%」と色分けされ、対応する凡例がデータを容易に理解できるよう表示されています。チャートの左側には、「分散投資によって単一市場の下落リスクを軽減し、安定性を向上」という補足説明があります。ページの下部には、株式市場、住宅、金貨といった様々な資産クラスを表すアイコンが水平に配置され、視覚的な訴求力を高めています。フッターには、「アドバイス:過去のパフォーマンスは将来の結果を示すものではありません」という小さな白い注記があります。 - 画像が写実的な肖像画やテキストではなく、風景、オブジェクト、抽象的な要素、様式的な構成に重点を置いている場合は、説明は視覚的な構造と雰囲気に焦点を当てる必要があります。 1. 主要な視覚的主題の種類、数量、形状、比率、配置、色彩、材質、表面の詳細などを明確に記述し、絵画の前景、中景、背景におけるそれらの位置と相互の空間的関係を説明する必要がある。 2. 同時に、光と色に関する情報の補足にも重点を置きます。光源の方向、自然光か人工光か、光の強さ、柔らかさ、硬さ、暖かさ、冷たさ、およびそれによって生じる影、ハイライト、反射、または周囲光の効果を明確にします。写真の全体的なトーンと局所的な色のコントラストを説明して、写真に階層性を持たせ、視覚的に誘導します。 3. 自然風景、都市空間、屋内環境、静物写真、概念空間などのシーンの種類とスケールを説明し、時間特性や気象条件(朝、夕暮れ、夜、雨上がり、霧、晴れなど)と組み合わせて、写真のリアリティや感情表現を高めます。 4. 静けさ、温かさ、神秘性、未来性、詩情など、画像が伝える感情や文体の傾向を適切に補足して、より多くの視覚的および美的情報を提供します。 **出力例**: 白いヒュンダイの2ドアクーペ。ボディはローダウンされ、スポーティなスタンスに改造され、シルバーのマルチスポーク軽量ホイールと組み合わされ、力強いアスレチック感覚を醸し出しています。フロントでは、黒いハニカムグリルが、シャープな三角形の光源で照らされるLEDマトリックスヘッドライトと鮮やかなコントラストを成しています。ルーフには赤い長方形のステッカーが貼られ、白いヒュンダイのロゴがはっきりと表示されています。車両の右側には、赤褐色の緑豊かな松の木が立ち、季節の移り変わりとともに葉が鮮やかなオレンジレッドに変化しています。左側には、垂直に伸びる木製の電柱がフレームからはみ出しています。地面は灰色のアスファルトで舗装され、小さなひび割れや摩耗が見られます。遠くの空は淡いブルーのグラデーションを描き、柔らかく温かみのある黄色の光が差し込んでいます(おそらく日の出から日の入りまでのゴールデンアワーの時間帯と思われます)。構図はローアングルで視線を水平に捉え、車両を視覚的な焦点としています。背景の要素はシンプルで控えめで、車両の力強さと洗練さを効果的に際立たせています。 ミニマリストのモダンなリビングルーム: 画像の中央には、ピンクの布地を使った 3 人掛けソファがあります。その表面には自然な布地の質感とわずかな折り目があり、同じ配色の正方形のクッションが 2 つ置かれています。ソファの左側には、ほっそりとした明るい色の木製の脚が付いた緑のベルベットのアームチェアがあります。ソファの前には、天板の縁に縦縞の彫刻が施された丸い無垢材のコーヒー テーブルがあります。その上には、透明なガラスの花瓶 (小さな黄色い花が 3~4 輪入っています)、小さな金属製のフレームのランタン、小さな円筒形の陶器の瓶 2 つがきちんと配置されています。コーヒー テーブルの後ろの壁の近くには、3 枚パネルのランプが置かれています。木製のフロアランプは、Y 字型の二股の脚が白い布地のランプ シェードを支えており、シェードの縁は自然にドレープしています。背景の壁は温かみのあるオレンジ色のマット仕上げで塗装され、下半分には白い羽目板のアクセントが施されています。左壁に白い薄手のカーテンがかかった窓から陽光が差し込み、床と壁に木漏れ日の光と影が点在しています。床にはライトグレーの毛足の短いラグが敷かれ、その下にはヘリンボーン模様の無垢材フローリングが敷かれています。空間は明るく均一に照らされ、適度な彩度で彩られており、まるで写真のような写実的な美しさを醸し出しています。 入力コンテンツ自体の形式(説明、フラグメント、解説、または指示テキスト)に関係なく、それを「最適化される画像の説明」として扱い、最終的な書き換えられた中国語の画像プロンプトを直接出力する必要があります。 最終的には、書き直した説明文のみを出力してください。判断プロセスの説明やカテゴリのラベル付け、その他の説明は不要です。
# ...existing code...
prompt = "狭义相对论原理的信息图"
result = generate_with_prompt(prompt, client)
print("Generated Prompt:\n", result)
こうふわっと「特殊相対性理論の原理のインフォグラフィック」というプロンプトを与えると、以下のように拡張されました。
一幅采用现代科学设计风格的狭义相对论原理信息图,背景为深邃的深蓝色,装饰有淡金色的几何网格与星光线条,营造出科技感与理性的学术氛围。画面顶部中央以醒目的白色粗体无衬线字体呈现主标题“狭义相对论原理”,下方搭配浅灰色小字副标题“探索时间、空间与光速的奥秘”。主体部分分为左右两个主要板块,左侧板块顶部文字为“基本假设一:相对性原理”,下方配有文字说明“物理定律在所有惯性系中形式相同”,旁边绘制有匀速运动的飞船图标,标注文字“惯性参考系”。右侧板块顶部文字为“基本假设二:光速不变原理”,下方说明文字为“真空中的光速恒定,与观察者运动无关”,配有一束光穿过棱镜的矢量图,并在旁边醒目列出公式“c = 299,792,458 m/s”。画面中央通过对比图展示“钟慢效应”,左侧为静止的时钟,标注文字“静止观察者”,右侧为高速运动的时钟,指针走得更慢,标注文字“高速运动观察者”,中间用箭头连接并写有说明“时间流逝变慢”。底部印有总结性标语“空间和时间是相互关联的统一整体”。整体视觉风格扁平化,配色以深蓝、白、金为主,文字清晰锐利,布局逻辑严密。
さて、この拡張されたプロンプトを用いて再度画像生成を試してみます。

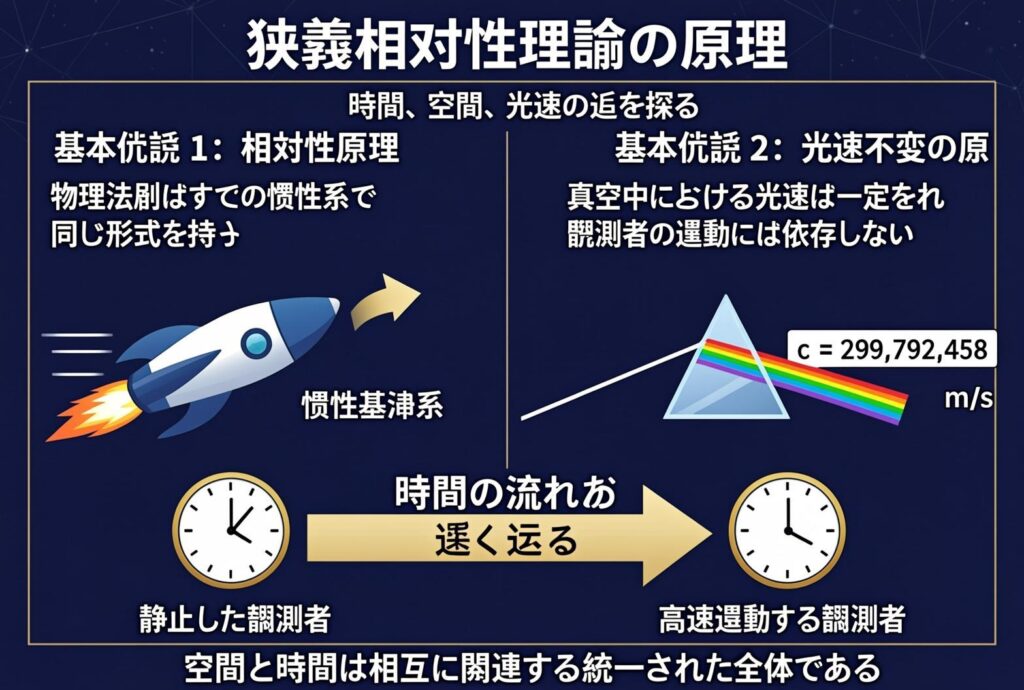
できました。中国語なので雰囲気でしか意味はわからないものの、物理法則は等価であること、光速度不変の原理を説明しているみたいです。これだけ漢字ができるのなら日本語の文字ではどうでしょうか?
ひらがなや日本の漢字も部分的には描写できていますが、やはり中国語ほどの精度は出せないですね。
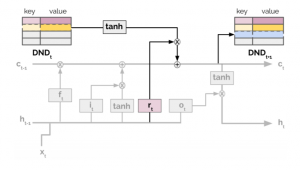
GLM-Imageのモデル構造
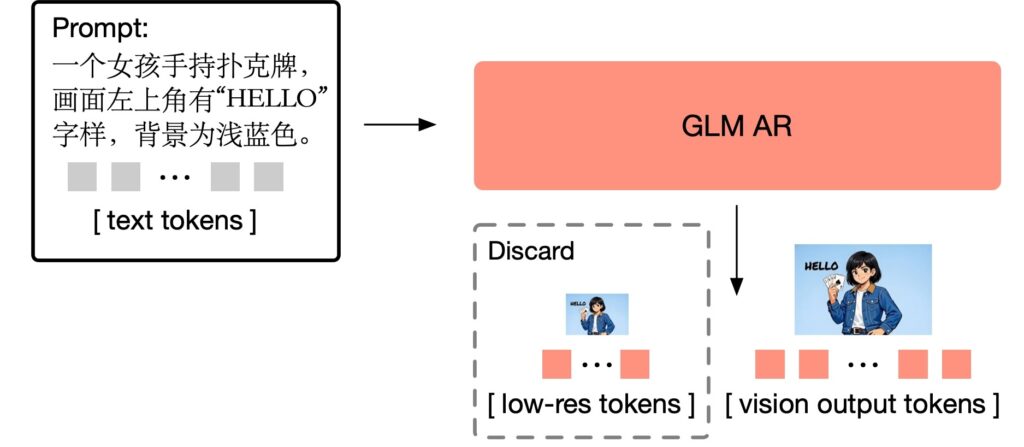
とりあえずGLM-Imageで画像生成して遊んでみましたが、自己回帰モデルと拡散モデルのハイブリッドというのは、一体どういうことかを見ていこうと思います。GLM-Imageのモデルは以下の様になっています。Text-to-Imageの場合、プロンプトをtext tokensとして自己回帰モデルであるGLM ARに入力し、vision output tokensを出力し、それと字形表現glyph embedsなどと組み合わせて拡散モデルDiffusion Decoderに入力し、最終的な画像を生成します。Image-to-Imageの場合、この前段階として、入力画像の特徴量を抽出して、それぞれをGLM ARとDiffusion Decoderの入力に与えます。
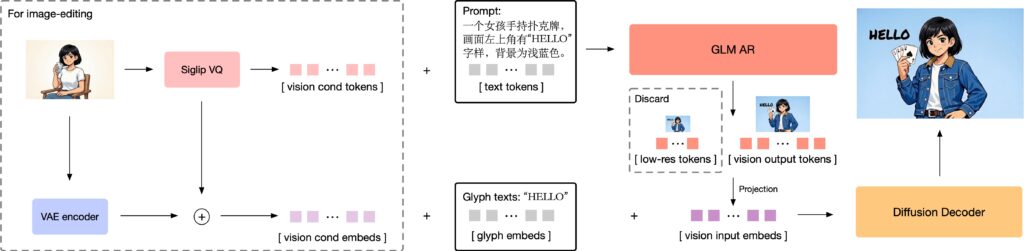
GLM-Imageの自己回帰モデルパートは、GLM-4-9B-0414という9Bパラメータの言語モデルをベースにしております。(GLM-4)この自己回帰モデルでは、最初に256トークンほどの解像度の荒い画像に対応するトークンを生成し、それを1,000-4,000トークンほどの高解像度画像に対応するトークンへと変換します。
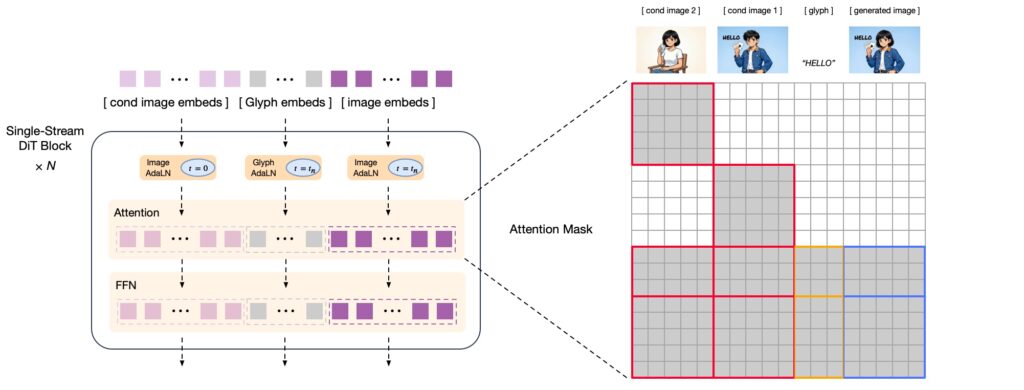
次に拡散モデル部分は、CogView4をベースとしています。CogView4はDiT(Diffusion Transformer)採用した7Bパラメータの画像生成モデルであり、拡散モデルと言っていますが、昨今の画像生成AIのデファクトスタンダードであるFlow matchingのモデルです。入力には、自己回帰モデルからの埋め込みと、Image-to-Imageの場合では入力画像の特徴量を与えます。また、文字表現を強化するために、字形表現(glyph embeds)も入力に加えられています。これは以前にBlogで紹介したGlyph-byT5を参考にしているようです(GPT-4oの中身(予想)とGlyph-ByT5〜文字の画像生成への挑戦〜)。
GLM-Imageを他の画像生成モデルと比べてみる
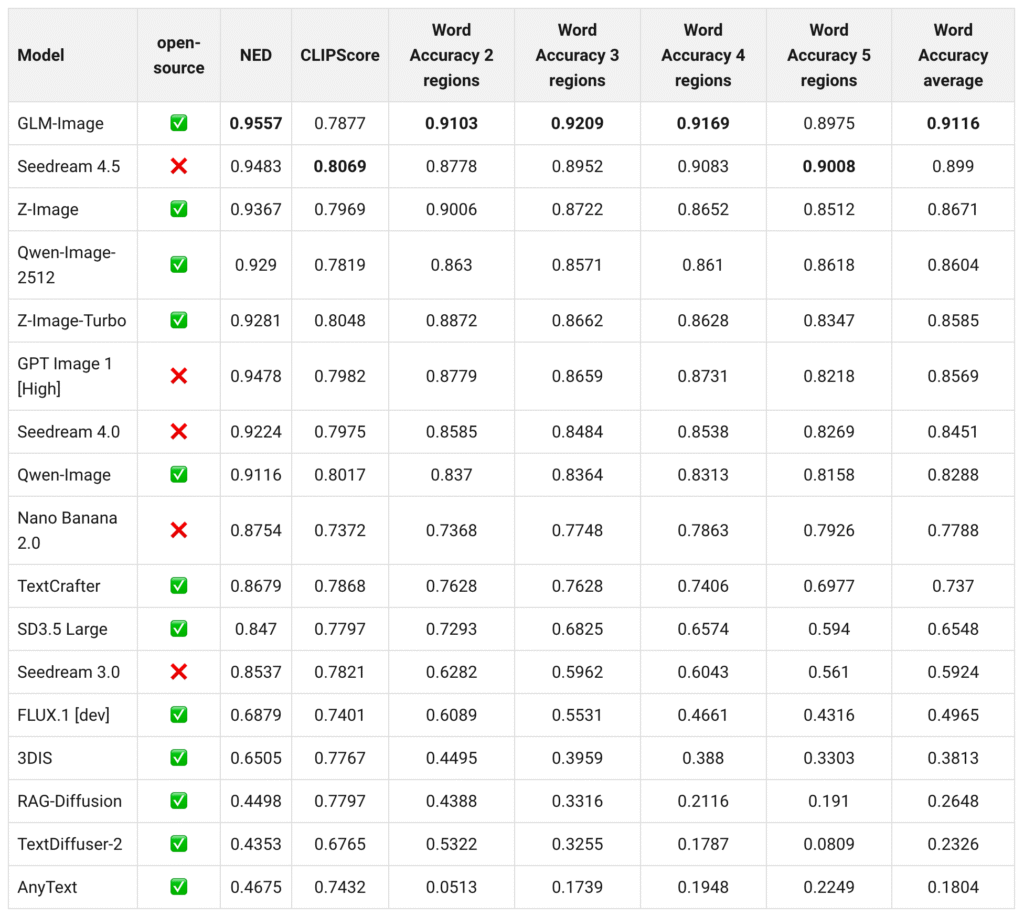
では、GLM-Imageと直近発表された他の画像生成モデルと比較してみます。比較対象として選んだのは、Z-Image Turbo、GoogleのNano Banana Pro (Gemini 3 Pro Image)、そして、先月アップデートされたOpenAIのGPT Image 1.5の3つです。なお、Z-Imageは、Z.aiではなくAlibabaのTongyi-MAIチームが昨年の11月末に発表したモデルです(Z-Image)。これはScalable Single-Stream Diffusion Transformer(S3-DiT)を採用し、テキストエンコーダーではQwen3-4Bを使用しトータルでは60億のモデルです。Z-Imageを高速生成できる様に最適化したZ-Image Turboが公開されています(https://huggingface.co/Tongyi-MAI/Z-Image-Turbo)。Z-Image Turboでは僅か数秒で複雑な文字の画像が生成可能です。
まずは、文字表現の比較です。ポスターを生成してみました(元ネタはZ-Imageの論文)。文字は中国語ですが、どのモデルもそつなく描写できています。描写される文字の品質に順番をつけるならば、GPT Image 1.5が最もよく、次にNano Banana Pro、Z-Image Turbo、GLM-Imageの順でしょうか、個人的な感想ですが。

では、次にホワイトボードの文字と人物描写の比較です。GLM-Image、Z-Imageについては、それぞれのモデルの特徴を説明してもらい、GPT Image 1.5とNano Banana Proは、Z-ImageとGLM-Imageの説明を代わってもらいました。先ほどと同様にどのモデルも中国語の文字表現は問題なく(たぶん)描写できています。GLM-Imageは印刷物みたいな文字ですし、品質は先ほどと同様にクローズドモデルの方が良い印象です。Nano Banana Proがさりげなくカメラアングルが凝っていることはポイントが高いです。

次に人物描写の比較をしてみます。これに関しては、三人の人物がクリスマスシーズンの風景の中で談笑している様子を描写してもらいました。まあ、大体良い感じではないでしょうか?ただ、GLM-Imageは比較してみると、画面全体が黒っぽい印象があります。先ほどのポスターやホワイトボードの画像でも同様でした。

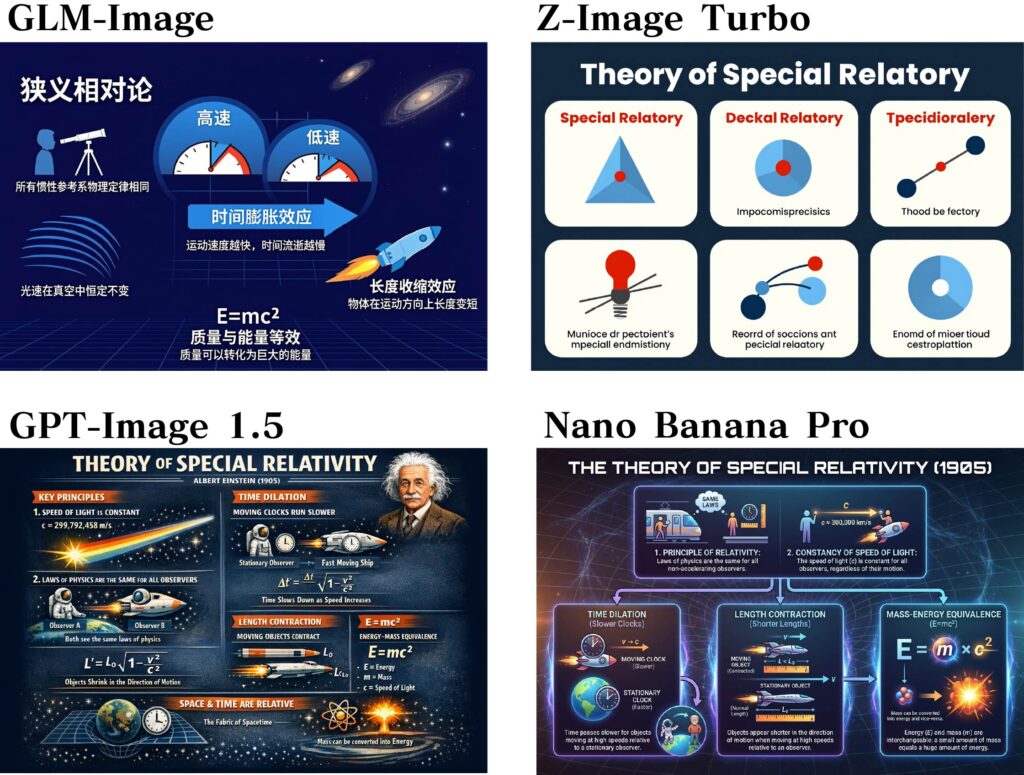
最後にインフォグラフィックを描写してもらいました。これはGLM-4.7の利用によるプロンプトの拡張(prompt_utils.py)は使わずに、単純に「特殊相対性理論のインフォグラフィック」というシンプルなプロンプトを与えています。GLM-ImageやZ-Image Turboでも組み込まれているLLMの知識を利用していますが、9Bと4Bの差が出たのか、GLM-Imageは良いのですが、Z-Image Turboは訳の分からない絵になってしまいました。GPT-Image 1.5とNano Banana Proは複雑な情報をまとめてくれていますが、細かい式など一部不可解な部分もあります。
まとめ:リアルタイム生成の可能性
今回のBlogでは、Z.aiの発表したGLM-Imageの画像生成を試してみました。 GLM-Imageは、自己回帰モデルと拡散モデルを組み合わせたハイブリッドモデルであり、自己回帰モデル部分には9BパラメータのGLM-4-9Bを使用し、拡散モデル部分には7BパラメータのCogView4を使用しています。オープンウェイトではありますが、実行には80GB以上のVRAMが必要であり、ローカルでの実行は無理でしたので、APIを利用しました。中国語の文字表現は可能ですが、流石に日本語までは難しい様です。
GLM-Imageを使っていて感じましたが、最初に自己回帰モデルで画像を描写するトークンを拡張・生成して、拡散モデル(flow matchingですが)で最終的な画像を生成するため生成速度にはあまり速さを感じませんでした。公式のレポジトリで、生成コストが以下のようにまとめられています。
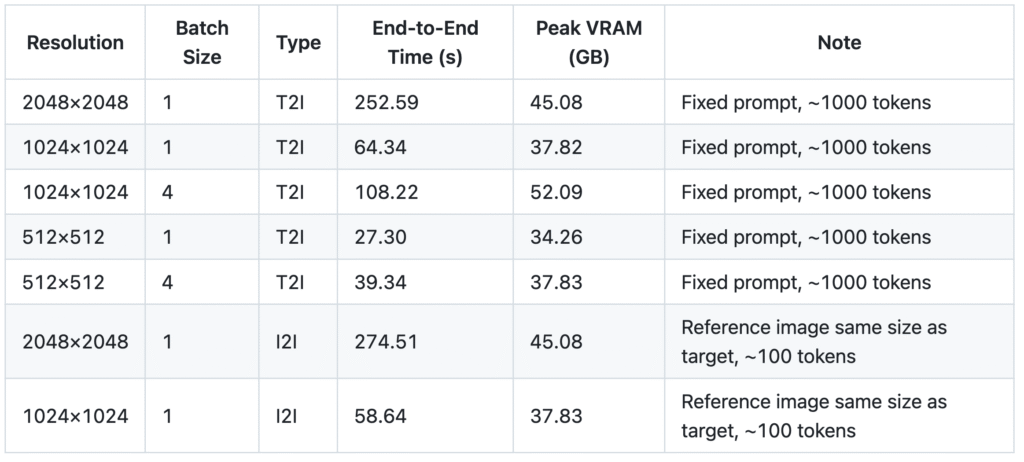
今回、GLM-Imageと比較するとZ-Image Turboの方が圧倒的に高速(数秒程度)であり、文字表現も遜色ないレベルで描写できています。先日発表されたBlack Forest Labsの「FLUX.2 [klein]: Towards Interactive Visual Intelligence」も、小型で高速な画像生成モデルであることを特徴としております。

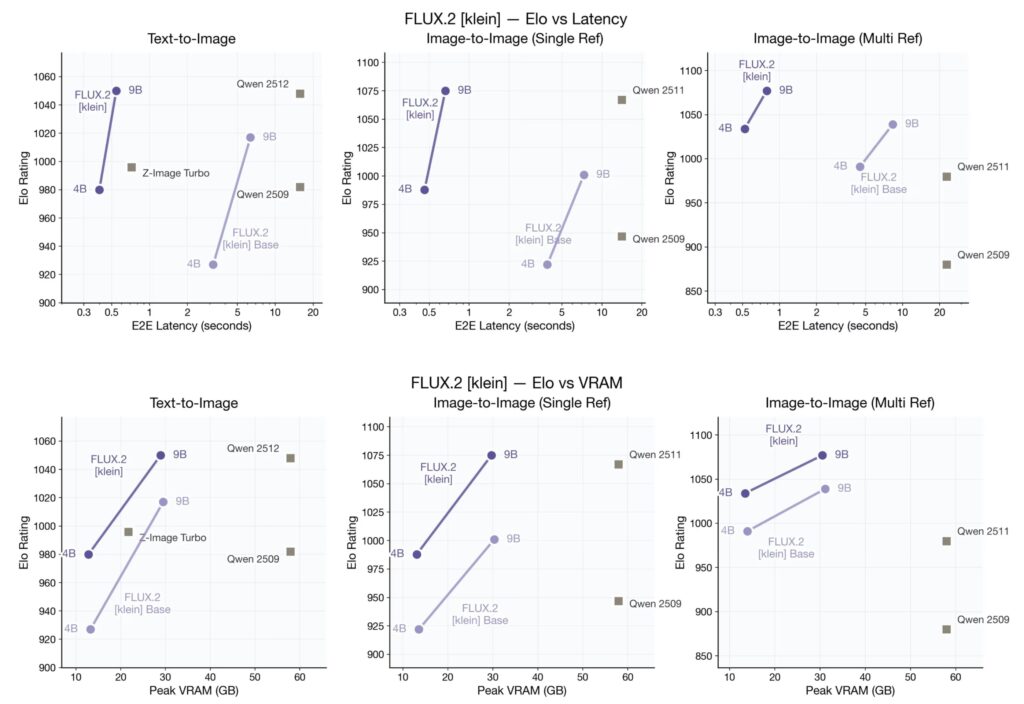
FLUX.2 [klein]のQwen-ImageやZ-Imagなどとのパフォーマンの性能比較は以下の様になります。縦軸はElo Ratingスコアで画像の品質、横軸は上段が生成時間、下段が使用メモリを表しています。FLUX.2 [klein]は、画像生成はほぼ同等でありながら圧倒的な生成速度と低メモリ使用量を実現しています。
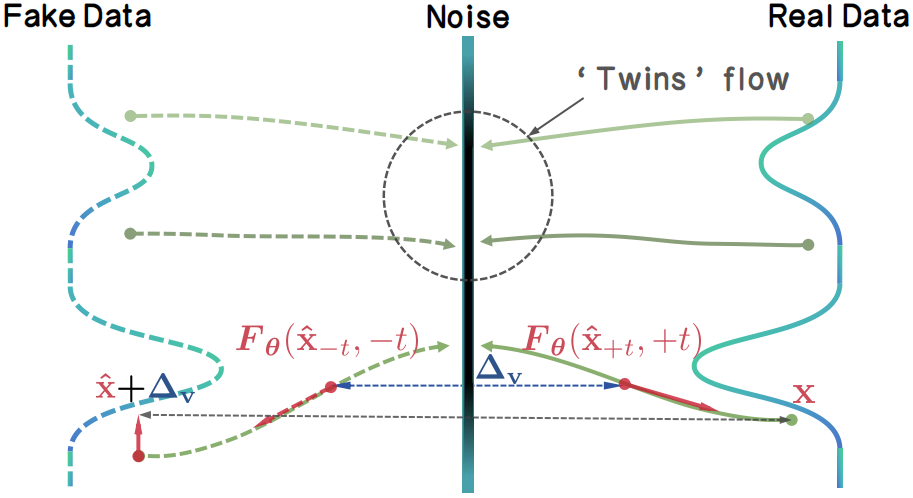
また、生成に必要なステップ数を削減する高速化手法として、先月には「TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows」という論文も発表されています。これを利用するとQwen-ImageやZ-Image Turboなどの生成モデルの更なる高速化が可能です。
一年前の2025年当初には信じがたいレベルで画像生成AIの文字表現の性能は改善しました。Nano Banana ProやGPT Image 1.5など複雑な画像は生成可能ですが、待ち時間が長いのが難点です。今後は更に高速化技術を高めてリアルタイムで生成される日が来るのも、そう遠くないかもしれません。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- GLM-Image: Auto-regressive for Dense-knowledge and High-fidelity Image Generation
- https://huggingface.co/zai-org/GLM-Image
- https://github.com/zai-org/GLM-Image
- GPT-4oの中身(予想)とGlyph-ByT5〜文字の画像生成への挑戦〜
- Z-Image
- https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
- FLUX.2[klein]: Towards Interactive Visual Intelligence
- TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD