2026.01.05
nanobananaで4コマ漫画を作ろう
まとめ
- Nano Banana Proはプレゼンテーションや漫画等の文字混じりの画像生成を可能にした
- 4コマ漫画に注目して、生成を行う
- このとき、起承転結のストーリーをつけることや、キャラクタライズするといった工夫を施して、わかりやすい/面白い構成にする。
- その内容をバッチ処理化したコードベースを作成して、Githubで公開した。
はじめに – 伝えたいことはNano Bananaで作ろう –
M.Sです。
Nano Banana Proで作成されたプレゼンが巷に溢れ始めている2025年の冬ですが、皆さんもお試ししたでしょうか?
箇条書き等の平文の内容をグラフィカルにするとすぐわかるのですが、平文よりも明らかに認知負荷が下がります。内容は差がなく、明らかに追加要素が加わる分、情報処理がしにくくなるように見えて、逆にとてもわかり易くなります。(もともと内容があることが前提ですが笑)このあたりは、生物学的にヒトが文字よりも空間的な情報を処理することが得意で「疲れない」「ドーパミンが出る」みたいな部分がポイントになっている気がしますが、このあたりは専門家に任せたいですね笑
またプレゼンに関しては、ほとんど自分のプレゼンテーションスキルを超えたという感じがしており、「平文の内容は今後Nano Banana Pro(等の画像生成)でレンダリングする」という新しいビジネスマナーが生まれてくるのではないかとか思っています。
と長々と語っている内容をまるまるNano Banana Proにプレゼンテーションしてもらいました。皆さんはどちらが読みやすい/理解しやすいと思いますか?

さて、今回私が注目したのは、「漫画」で、今回Nano Banana Proを使っていい4コマ漫画を作ることを探求したいと思います。このときなるべくもともとの内容を「面白く」「わかりやすく」要約することを目指したいと思います。
例: 山月記を4コママンガ化
まずは、私が大好きな物語「山月記」より。山月記は、高校の現代文に採用されていることが多く、読んだことがある人もおおいのではないでしょうか。話の概要をいうと「詩人として成功したかった男が、高すぎるプライドのせいで人間としての心を失い、虎になってしまう物語(gemini 3 proより)」で『「臆病な自尊心」と「尊大な羞恥心」』というフレーズが有名です。高校生の頃の私は、読みづらくて人が虎になる変な話だな、という認識でしたが、大人になって読むと内容が刺さりまくるんですよね笑
まず、ブラウザのGeminiに雑になげて4コマ漫画を作ってもらいます。

早速かなりいい感じです。笑
特に、山月記の一番重要な主題(の一つ)である「なぜ李陵は虎になったのか」という部分についてフォーカスされ、「傲慢な心が猛獣となって、己の外形を内面にふさわしいものに変えてしまったのだ」と端的に説明されています。高校生のときの自分にもまずはこれを読ませてあげたい、、、
逆に今ひとつな部分としては、
- 4コマが縦一列に並んでいない(上の写真の場合Zの順に読む必要があり、日本の漫画の普通の順番に並んでいない。)
- 「なぜ虎になったのか」以外について捨象されているので、その他のバリエーションも見てみたい
というところでしょうか。
ここで、Geminiと相談して、よい四コママンガとなるための要件を詰めていきます。
4コマ漫画の条件
まず題材についての向き不向きは、以下のようになっていると思います。

(gemini 3 proとともに行った分析結果)
この中でも「対話形式」「動き、変化、比較」といった要素は、かなり重要な気がしますね。山月記は物語なので、キャラクターが活きるように登場人物のキャラを強調するようにプロンプトを組んでみた結果出てきたものがこれです。

これもかなりいい感じです笑
厳密には李陵は話の序盤で「段々と人間から虎に変わった際の具体的な経緯」を延々と話すので、詩の話をいきなり始めたわけではないことや(順番が逆だろう、、、)というツッコミは後付けのメタ的な視点であるという物語の二次創作?が行われていますが、
一枚目と比べてボケとツッコミという構図となっていて、しかも李陵とエンサンそれぞれのキャラクターが明確で親しみやすく、かなり面白い4コママンガに仕上がっています。
皆さんもGeminiやChatGPTを用いて、面白くてわかりやすい4コママンガを作ってみてください。
4コマ漫画ジェネレータの作成
さて、いくつか知見がたまってきたところでこのジェネレータをNanobanana ProのAPIを用いて実装してみます。
実装してみたものはGithubに公開しており、こちらになります。
アーキテクチャ
![]()
![]()
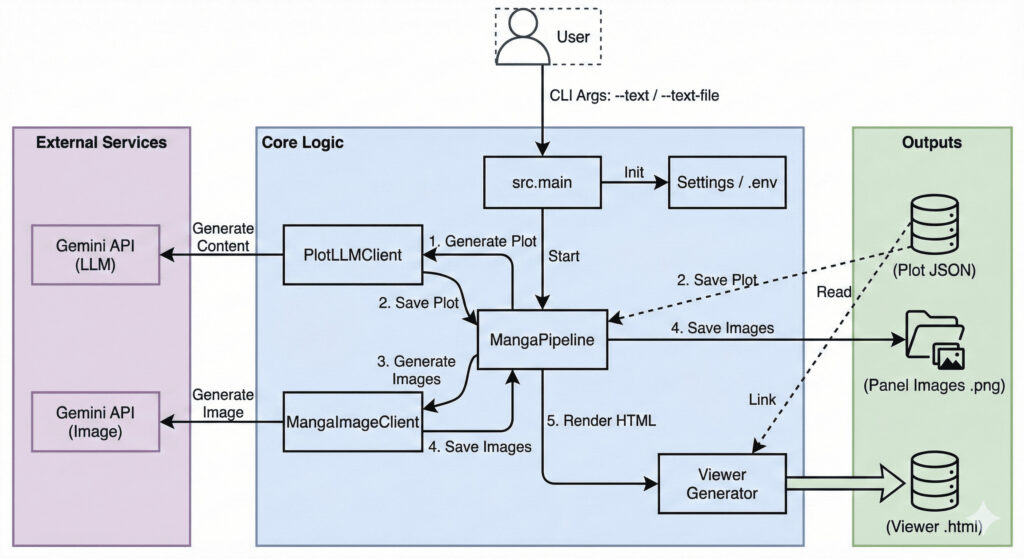
少しoutputがごちゃごちゃしていますが、要するに
- 4コマ漫画にしたいテキストを入力
- llmで4コマ漫画として良くなるようにプロンプトエンハンス(Gemini API)
- イメージ生成(Nano Banana ProのAPI)
- 保存
という流れになっており、イメージ生成前にいわゆるプロンプトエンハンスがなされています。
実行・結果
今回の入力テキストは最新論文である
Stabilizing Reinforcement Learning with LLMs: Formulation and Practices
にします。これにした理由は、かなり理論よりの論文でどのような4コマ漫画に仕上がるのか見たかったためです。
本当は論文全体を入れたかったのですが、トークンがもったいなかったので笑、アブストだけ入れて結果を見て見ました。
[Abstract] This paper proposes a novel formulation for reinforcement learning (RL) with large language models, explaining why and under what conditions the true sequence-level reward can be optimized via a surrogate token-level objective in policy gradient methods such as REINFORCE. Specifically, through a first-order approximation, we show that this surrogate becomes increasingly valid only when both the training-inference discrepancy and policy staleness are minimized. This insight provides a principled explanation for the crucial role of several widely adopted techniques in stabilizing RL training, including importance sampling correction, clipping, and particularly Routing Replay for Mixture-of-Experts (MoE) models. Through extensive experiments with a 30B MoE model totaling hundreds of thousands of GPU hours, we show that for on-policy training, the basic policy gradient algorithm with importance sampling correction achieves the highest training stability. When off-policy updates are introduced to accelerate convergence, combining clipping and Routing Replay becomes essential to mitigate the instability caused by policy staleness. Notably, once training is stabilized, prolonged optimization consistently yields comparable final performance regardless of cold-start initialization. We hope that the shared insights and the developed recipes for stable RL training will facilitate future research.
こちらを生成した結果がこちらになります。

かなり意味不明な結果になりました 笑。とはいえ、漫画的な表現は破綻なくなされていて、最低限のクオリティには達しているように見えます。
元々のアブストをよく読むと、シーケンス報酬がケーキ全体の比喩で、トークン報酬がケーキを構成する一部(いちごなど)であるということ等すこしずつ漫画の意味が理解できるようになってきますが、これでは本末転倒ですね笑
論文はbefore/afterを意識した構成のplotにすることで4コママンガという枠組みに収めることが可能なような気がしますが、今回のような理論よりの論文に対しては特に荷が重いようです、、。
工夫ポイントや苦労した点
- 起承転結プロンプトの型を固定:src/prompts.py でJSONフォーマット&視覚フック指示を明示し、パネルごとに「動き・対比」が入るようテンプレ化しました。
- また、JSON抽出の堅牢化して、Geminiの返答がコードブロックやプローズでも _extract_json_text でパースできるように正規表現とフェンス除去を実装しました
- 画像を縦一列に並べることが大変でした。特にブラウザのGeminiでは、縦長な画像(103 : 256)を生成することができるのですが、API利用の場合、最も縦長なもので16:9で、一コマあたりが横長になっています。
- 出力が不安定である: 今回はコマ間に不要な文字が表示されているように、不必要な文字等が描写されがちである。
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD