2025.11.18
playwright使ってみた
こんにちは。次世代システム研究室のK.Sです。
今回の記事では、playwrightを使ってみましたのでご紹介します。
tenbin.aiサービスのtestを元に実施していければと思います。
現在以下の課題を感じております。その課題解決の一手になればと思います。
少し大きな開発チームにおいて、起きている問題。レビューが溜まってしまう。
問題1
開発組織が大きくなった。
→ コーディング作業する人が多い
→ さらに手元でAIを使い、devinなどでもAI使うから作業が早い
→ 大量のpull requestが来る
→ レビューするシニアエンジニアがレビューで一日終わるorz…
問題2
既存コードを実際に今まで書いてきていて、
仕様、設計、など把握しているエンジニアがレビューしている。
今後1~2年で新規開発の95%くらい、AIが書くことが予想される。
→ レビューする人が大量のコードレビューする
→ かなり読み込まないといけない。
→ 極論、毎日 知らないライブラリのコード全体を見てレビューしてといわれるような状態
→ まず、シニアエンジニアをそのようなタスクに使うのもったいないという話
→ 毎日、レビューに追われる、「責任はシニアエンジニア」。地獄。人が辞めてしまう。
となる。
このフローを組織的にどう改善していくかという問題。
振り返り
そこで、振り返るが、そもそもコードレビューって何のためだっけ?
→教科書的には、「ソフトウェアの品質とチームの生産性を高めるため」
コーディングする人がAIであるということを踏まえて一般的にコーディングの役割を見てみる。
- 品質向上(バグの早期発見)
- 可読性: 他人が読んで理解できるコードか?
- ロジックの妥当性: 意図通り動く実装か?
- エッジケースへの考慮: 境界・例外条件をカバーできているか?
- パフォーマンスリスクの検出: 無駄なループ・重いDBクエリやAPI呼び出しがないか?
→ コードの静的チェックを、他者の目で行うことで製品の品質を高める
- チームの共通理解・ナレッジ共有
- 他のメンバーが実装内容を知ることで「属人化回避」
- プロジェクト全体のコード構造・アーキテクチャを共有
- 将来の機能追加・不具合修正をしやすくする
- ベストプラクティス・規約の順守
- スタイルガイドやアーキテクチャ方針の徹底
- 安全なコード(セキュリティ・例外処理)を書いているかを担保
- 育成・フィードバック
- Jr. エンジニアが上級者からフィードバックを受け、改善を学ぶ
- 良いコード・悪いコードの「レビュー文化による教育」
上記のほとんどがAIが9割コーディングする時代が来たら、変わるよねという話。
その場合に、どのように「ソフトウェアの品質」を担保していくか。
そもそも、現在でもこんなこと起きている。
- コードレビューしたコードをbuildしたら、error
- UIはコードだけではわからない。
- リリース後にエラー
- レビューする人によって、指摘や、レベルがバラバラ
- 既存のクソコードも直す?いや、今じゃない。すでに動いているし、変更すると確認事項増えるからやめて。
- 宗教的なルールを守らせるに特化する人もいる
ちゃんと一生懸命現場はやってきたが、
俯瞰してみると「ソフトウェアの品質」という意味では、担保できていたとも言い切れない。
今後、AIの時代に「ソフトウェアの品質」が変わっていく可能性がある。
「AIが書いたコードを人間が読む」より、「実行して確認する」「異常を自動検出する」が中心に
テストフローも、もしかしたら、e2eのテストが重要度が増してくるのではないか。
unitなどのテストが重要ではないというわけではなく、ロジックなどの単体でのテストは、AIの得意分野である。
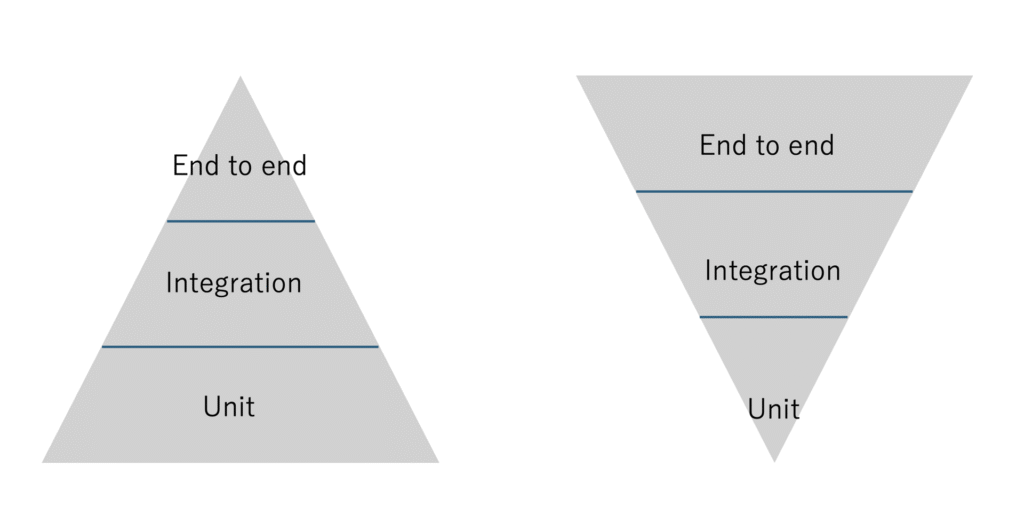
AI開発時代はコードレビューからテストレビューへのシフトが必要
少し、考え方を変えないと、AIと対立して、ストレス溜めて終わる。
そこで今回、e2eのplaywrightを使ってみた。
なお、上記だけでは十分でなく、他のテストも必要ですが、本稿では割愛します。
例えば、E2Eテストでは「1ユーザーの動作確認」はできても、「100万アクセス時に破綻するコード」は検出できない。
負荷や、同一リソースへの複数スレッド同時アクセス時の挙動を検証するコンカレンシーテストの導入も必要でしょう。
UATの自動化も必要でしょう。
メールとか外部連携系とか
Playwrightでやるテスト。
AIが生成したコードは「ロジック上は正しくても、ユーザー体験として破綻する」ケースが増える。
そのため、Playwrightを中心に「実際に動くこと」を自動検証する。
2. 対象とするテスト範囲
実際にやってみた
- Regressionテスト(機能テスト(e2e))
- Visual Regressionテスト
設定は、以下のようにして、workersを増やすことで、並列実行できます。(遅い問題)
また若干チューニングに難しさを感じるが、ビジュアルリグレッションテストでどこまで許容するかなど指定します。
export default defineConfig({
testDir: './tests',
timeout: 90000, // 90秒のタイムアウト(並列実行時の待ち時間を考慮)
fullyParallel: true,
forbidOnly: !!process.env.CI,
retries: process.env.CI ? 2 : 1, // ローカルでも1回リトライ
workers: 1, // 順次実行(並列実行による競合を回避)
reporter: [
['html'],
['./reporter.ts'],
],
// テスト開始前にスクリーンショットフォルダを削除
globalSetup: require.resolve('./global-setup.ts'),
// テスト終了後に前回実行との比較レポート生成
globalTeardown: require.resolve('./global-teardown.ts'),
// ビジュアルリグレッションテストの設定
expect: {
toHaveScreenshot: {
// 許容する差分の最大ピクセル数(小さい変更は無視)
maxDiffPixels: 100,
// ピクセル単位の差分閾値(0–1、0.2 = 20%の色差まで許容)
threshold: 0.2,
// アニメーションを無効化して安定したスクリーンショットを取得
animations: 'disabled',
// CSSの拡大縮小を無視
scale: 'css',
},
},
use: {
baseURL: 'https://stg-biz.tenbin.ai',
trace: 'on-first-retry',
screenshot: 'only-on-failure',
navigationTimeout: 60000, // ページ遷移のタイムアウト
actionTimeout: 30000, // アクションのタイムアウト
headless: true, // ヘッドレスモード
},
projects: [
{
name: 'chromium',
use: {
...devices['Desktop Chrome'],
},
},
],
});
テストについて、実際には、詳細な動作確認をコードとして記述していく形になりますが、基本的にAIに書かせます。
/**
* モデル選択モーダルを開く
* @param page Playwrightのページオブジェクト
*/
export async function openModelSelectionModal(page: Page): Promise<void> {
const addButton = page
.locator('button.ButtonSecondary.sizeIcon.rounded-corners')
.filter({
has: page.locator('svg'),
})
.first();
await addButton.click();
await page.waitForTimeout(1500);
// モーダルが開いたことを確認
const modalTitle = page.locator('text=/AIを選択する/i');
await expect(modalTitle).toBeVisible({ timeout: 10000 });
}
画像比較は、以下のようにtoHaveScreenshotを使って比較します
test('許容差分を大きくして比較', async ({ page }) => {
await page.goto('/chat');
await expect(page).toHaveScreenshot('chat-flexible.png', {
fullPage: true,
maxDiffPixels: 500, // 500ピクセルまで差分を許容
threshold: 0.3, // 30%の色差まで許容
});
});
立ち上げ後、ログインを自動的に行います。
![]()
![]()
modelを選択など、指示通り実行してくれます。
![]()
![]()
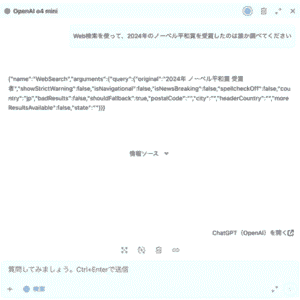
AIに対して問いをした結果。正常に返却されているかに関しては、以下のように返却文言を比較します。
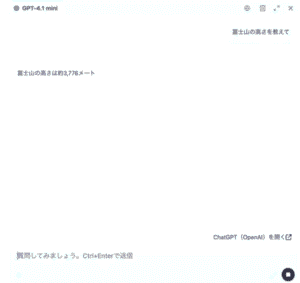
返答
/**
* 返答テキストを抽出する
* @param page Playwrightのページオブジェクト
* @returns 返答テキスト
*/
export async function extractResponseText(page: Page): Promise<string | null> {
// AIの返答が含まれている paragraph や div を探す
const responseSelectors = [
'p:has-text("富士山")',
'p:has-text("3,776")',
'p:has-text("3776")',
'div:has-text("富士山")',
'div:has-text("3,776")',
'div:has-text("3776")',
];
// 該当する最初の要素を順に確認
for (const selector of responseSelectors) {
const element = page.locator(selector).first();
if (await element.isVisible()) {
return await element.innerText();
}
}
return null; // 見つからなかった場合
}
web検索が行われているかも同様に返却文言などを比較します。
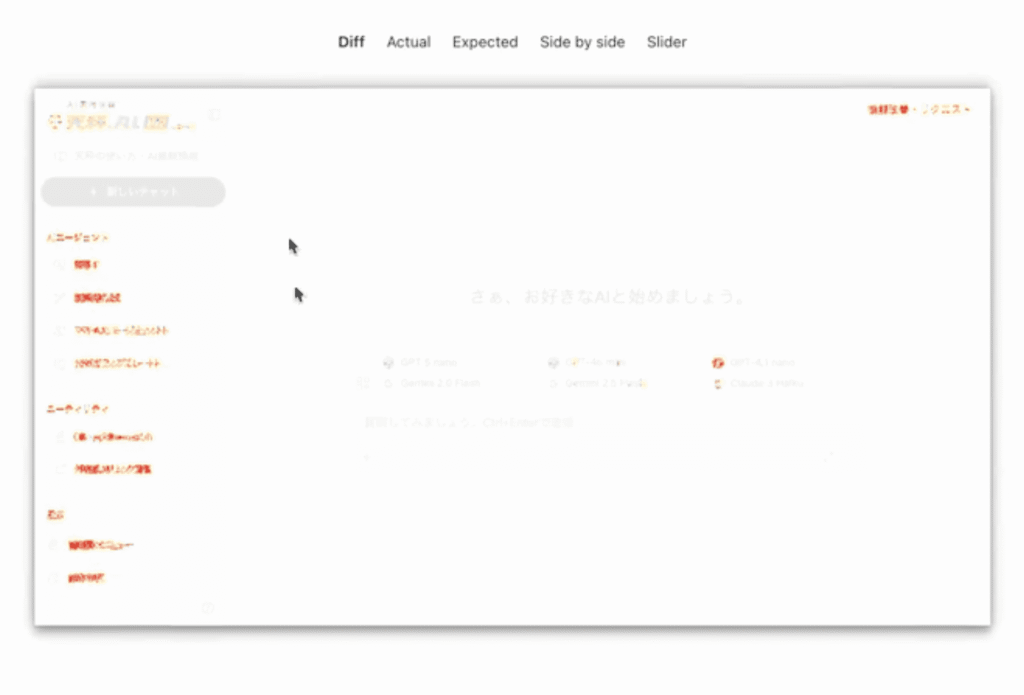
Visual Regressionテストの結果についてですが、diffを行い、違いが出ていくるので、思ってもみない箇所を触ってしまって、へんな修正が入っていないかなどチェックできます。
結論:
十分実用に耐えると感じました。しかしながら、時間がかかるので、リリースなどのworkflowのどこに組み込むのかが、一つ考える必要がある。
テストチームなどのへの展開もありかもしれない。
将来的には、visual regressionテストは、Figma MCPと連携して、差分チェックもできそうだなと考える。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





