こんにちは。グループ研究開発本部 次世代システム研究室のT.D.Qです。
2025年10月、Playwright 1.56 のリリースとともに「Playwright Test Agents」が登場しました。
テスト計画からコード生成・自己修復といった日々のQA業務をAIに自律的に任せられる、十分に実用的なツールとして大きな期待が寄せられています。一方で、実システムの挙動をそのまま「正」として学習する仕組み上、人間によるレビューや仕様書ベースでの指示を前提とした運用(主にリグレッションテストでの活用)が不可欠になるという側面もあります。
今回は、実運用を見据えた技術検証を通じて得られた本ツールのポテンシャルと、現場に投入する際の「リアルな評価・注意点」をエンジニア目線でお届けします。
📝 この記事でわかること
- Playwright Test Agents(Playwright 1.56)のアーキテクチャとマルチエージェントの全体像
- Claude Code と MCP を使ったセットアップ手順・実行ワークフロー全歩
- Planner 24分 → Generator 20分 → Healer 1時間… 合計3時間で回帰テストを構築(従来比 約2.7倍の時間短縮)
※ 初回実行時の成功率は約26%。Healer修復後に大幅に向上 - SPEC.md生成が高精度テストの鍵 ─「現状の振る舞いを正」としてしまうリスクの回避方法
- 6つの現場課題(コンテキスト、非決定性、リアクティブ修復…)と安全な導入方針
目次
1. Playwright Test Agentsとは:E2E回帰テストをAIが自律実行する時代へ
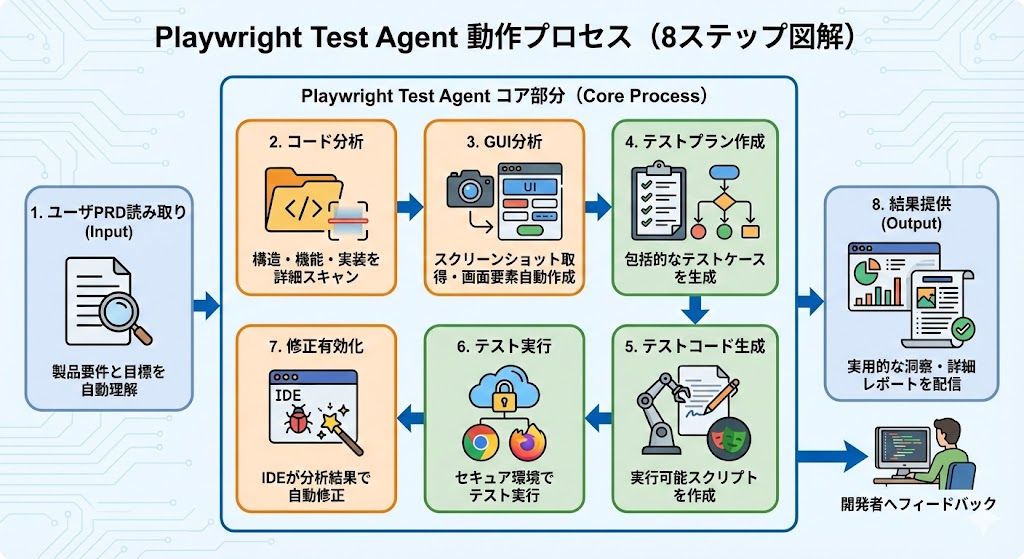
Playwright Test Agents は、Playwright 1.56 で導入されたAI駆動のE2E回帰テスト自動化ツールです。
従来の回帰テスト自動化では、私たちが手動でテストケースを設計し、コードを記述し、失敗したテストをCIのログと睨めっこしながらデバッグする必要がありました。Playwright Test Agents は、これらのプロセスをAIエージェントが自律的に実行することで、E2E回帰テストの自動化における生産性を大幅に向上させます。
また、Model Context Protocol(MCP)を活用しており、VS Code Copilot、Claude Code、OpenAI GPT-5.2 などの様々なAIプラットフォームとシームレスに連携可能です。これにより、開発者は「自然言語で回帰テストの要件を伝えるだけ」で、AIエージェントが包括的なE2E回帰テストスイートを自動構築してくれます。
2. 3つのメリットと「マルチエージェント」の深層
2-1. E2E回帰テスト構築を劇的に早める3つのメリット
Playwright Test Agentsを導入することで、E2E回帰テストの作成・実行がより迅速かつ簡素化され、以下の恩恵を受けられます。
- AIが実装を調査してテスト計画書を作ってくれる: 手動でのテスト計画書作成時間を大幅に短縮できます。
- 計画書をもとにテストコードを作ってくれる: 実装時間を削りつつ、テストカバレッジの向上を短期間で実現できます。
- 失敗したテストは自動で修復してくれる(自己修復機能): テストコードの保守工数を減らします。不安定なテスト(Flaky tests)のメンテナンスに苦慮している開発者にとって、大きな改善となります。
2-2. 役割分担する3つのエージェント
Playwright Test Agentsは、単一のAIではなく、役割を特化させた3つのカスタムエージェントが協調動作するマルチエージェントシステムとして設計されています。これらが「エージェント・ループ(Agentic Loop)」と呼ばれる一連のライフサイクルを形成し、テストの計画、生成、修復を自動的に完結させます。
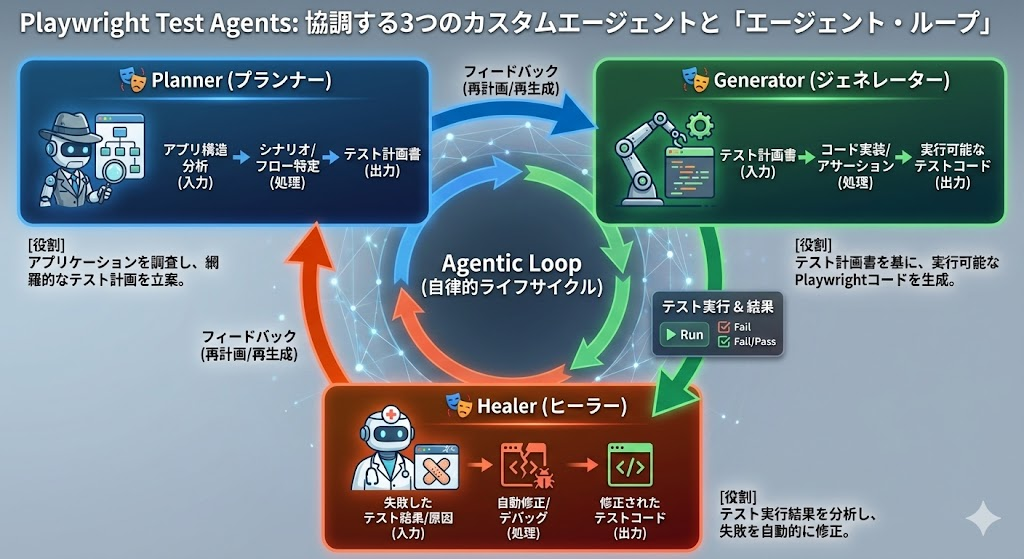
- 🎭 Planner (プランナー)
役割: アプリケーションを調査し、テスト計画書を作成します。
アプリの構造を分析し、テストすべきシナリオやユーザーフローを特定します。正常系、異常系、エッジケース、セキュリティテストなど、様々な観点から網羅的なテスト計画を立案してくれます。
- 🎭 Generator (ジェネレーター)
役割: テスト計画書を基に、実行可能な Playwright テストコードを生成します。
Planner が作成したテスト計画をもとに、実際に動作するテストコードを自動生成します。セレクタの検証やアサーションの確認を行いながら、テストを実装してくれます。
- 🎭 Healer (ヒーラー)
役割: テストを実行し、失敗したテストケースを自動的に修正します。
テストの実行結果を分析し、失敗の原因(UIの変更など)を特定して自動的に修正を行います。デバッグ時間の削減に貢献します。
3. インストールとステップバイステップガイド
3-1. 検証環境とテスト対象システム
今回、Playwright Test Agentsを実際に稼働させた環境と、テスト対象のWebアプリケーションは以下の通りです。
【稼働環境】
- マシン: Macbook Pro M2, 32 GB Memory
- OS: macOS Tahoe 26.1
- エディタ: VS Code
- AIアシスタント: Claude Code (CLI)
【テスト対象Webアプリケーション】
テスト対象として、RefineとAnt Designを用いて構築された「PDF Invoice Generator」のサンプルプロジェクトを使用しました。
- プロジェクト詳細: Refine Invoicer Example (GitHub)
- ライブデモ: PDF Invoice Generator Live Demo
- ローカル環境構築コマンド:
npm create refine-app@latest -- --example invoicer
3-2. 導入ステップ(Claude Code連携)
Playwright Test Agentsは、Model Context Protocol(MCP)を通じてAIツールと連携できます。今回は、設定が容易で強力な自律実行能力を持つ「Claude Code」を利用したセットアップと実行手順を紹介します。
- Playwright Agentsの初期化(Claude用):
対象プロジェクトのディレクトリで、Claude Code向けのエージェント定義ファイルやMCP設定ファイル(.mcp.json)を自動生成するコマンドを実行します。このコマンド一つで、必要なPlaywrightパッケージのインストールからAgentの初期化までが完了します。$ npx playwright init-agents --loop=claude Need to install the following packages: [email protected] Ok to proceed? (y) y 🎭 Using project "" as a primary project 📝 specs/README.md - directory for test plans 🌱 seed.spec.ts - default environment seed file 🤖 .claude/agents/playwright-test-generator.md - agent definition 🤖 .claude/agents/playwright-test-healer.md - agent definition 🤖 .claude/agents/playwright-test-planner.md - agent definition 🔧 .mcp.json - mcp configuration ✅ Done.手動設定の煩わしさなく、すぐにClaude Codeが各エージェントを認識できるようになります。
- Claude Codeからの実行(実践ワークフロー):
ターミナルでclaudeコマンドを実行してClaude Codeを起動し、自然言語でエージェントに指示を出します。ここでは、仕様書をもとにテストを自動構築・修復する一連の流れを紹介します。⓪ 仕様書(SPEC.md)の生成【重要な事前準備】
Playwright Test Agents が高精度なテスト計画を生成するには、「テストベース」となる仕様書をあらかじめ用意することがベストプラクティスです。仕様書なしにテストを生成すると、エージェントはシステムの現状の挙動のみを「正」として学習してしまいます。既存バグがあればそれもテストケースに組み込まれてしまうため、Plannerエージェントへの参照ファイルとしてSPEC.mdを先に作成しておくことを強く推奨します。Claude Codeに以下のPromptを指示するだけで、ソースコードを自動解析した詳細な仕様書を
SPEC.mdとして出力してくれます。📋 Prompt(SPEC.md生成用):@invoicer/src を調査して、SPEC.mdファイルにシステム全体の仕様書を書いてください。
このPromptを実行すると、Claude Codeがソースコードを自動解析し、
SPEC.mdをプロジェクトルートに生成します。実際に生成された仕様書には、以下のセクションが構造化された形で記述されます。📄 生成された SPEC.md の主要セクション:- 概要・技術スタック: React 19 + Refine + Ant Design v5 + Strapi v4 バックエンド
- 認証: JWT 認証フロー・localStorage 保存・自動ログアウト
- データモデル: Account / Client / Invoice / Service / User / Media の型定義と説明
- ルーティング: 全 URL パスとコンポーネントの対応表
- 画面仕様: 各ページのテーブルカラム・フィルタ・ソート・フォームフィールド・バリデーション
- 請求書計算ロジック: 行合計 = unitPrice × quantity × (100 − discount) / 100、合計 = 小計 × (1 + tax / 100)
- コンポーネント: フォーム部品・ヘッダー部品の機能説明
- プロバイダー: authProvider / dataProvider / axiosInstance / ConfigProvider の仕様
- ユーティリティ: ランダム色生成関数
- テーマ: Purple ベース・ダーク/ライト切替・レスポンシブ
- API エンドポイント・populate パターン
- 開発コマンド
この仕様書が、以降のステップでPlannerエージェントが参照する「唯一の真実(Single Source of Truth)」となります。
① テスト計画の立案 (Planner)
仕様書であるSPEC.mdをコンテキストとして指定し、Plannerエージェントにテスト計画を作成させます。🖱️ エージェントの選択: Claude Code の入力欄で @playwright と入力し、表示されるエージェント一覧からplaywright-test-plannerを選択します。💬 Prompt:SPEC.mdの仕様に基づいた網羅的なE2Eテスト計画を作成してください。実際に実行した結果、約24分で以下のテスト計画が自動生成されました。
❯ @playwright-test-planner SPEC.mdの仕様に基づいた網羅的なE2Eテスト計画を作成してください。 ⏺ playwright-test-planner(Create E2E test plan from SPEC.md) ⎿ Done (33 tool uses · 168.4k tokens · 23m 56s) ⏺ テスト計画が作成されました。invoicer/test.plan.md に保存されています。 テスト計画の概要 9 スイート・42 テストケースで構成されています: ┌ テスト計画 ─────────────────────────────────────────┐
# スイート 件数 1 認証フロー 6 2 アカウント管理(一覧・フィルタ・ソート) 8 3 アカウント管理(作成・編集・削除) 8 4 クライアント管理(一覧・フィルタ・ソート) 6 5 クライアント管理(作成・編集・削除) 6 6 請求書管理(一覧・フィルタ・ソート) 6 7 請求書管理(作成・詳細・削除) 6 8 グローバル検索 4 9 テーマ切替・ナビゲーション 8 └─────────────────────────────────────────────────────┘ 主な検証ポイント: - JWT 認証フロー(localStorage 保存・自動ログアウト) - 各リソースの CRUD 操作(モーダル・インライン編集含む) - テーブルのフィルタ・ソート(複数選択・部分一致など) - 請求書の自動計算ロジック(unitPrice × quantity × (1 - discount%) → tax 適用) - PDF エクスポート(window.print() 呼び出し・ヘッダー非表示) - グローバル検索のアカウント/クライアント混合結果 - テーマ永続化(localStorage colorMode)
② テストコードの生成 (Generator)
Plannerが生成したテスト計画書を確認したうえで、Generatorエージェントに実際のテストケースを実装させます。🖱️ エージェントの選択: Claude Code の入力欄で @playwright と入力し、エージェント一覧からplaywright-test-generatorを選択します。💬 Prompt:先ほど作成したテスト計画に基づくPlaywrightのテストケース(TypeScript)を実装してください。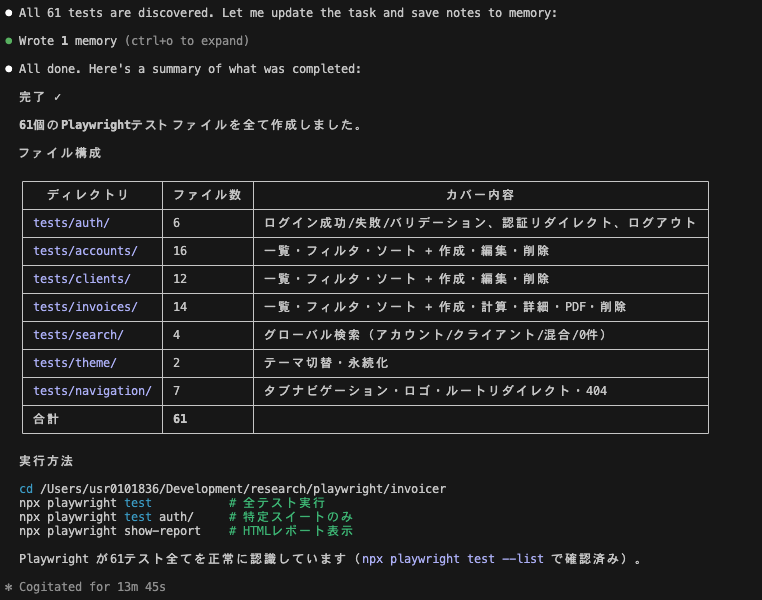
以下のようにテスト計画書に記載した内容から回帰テストが生成されました。
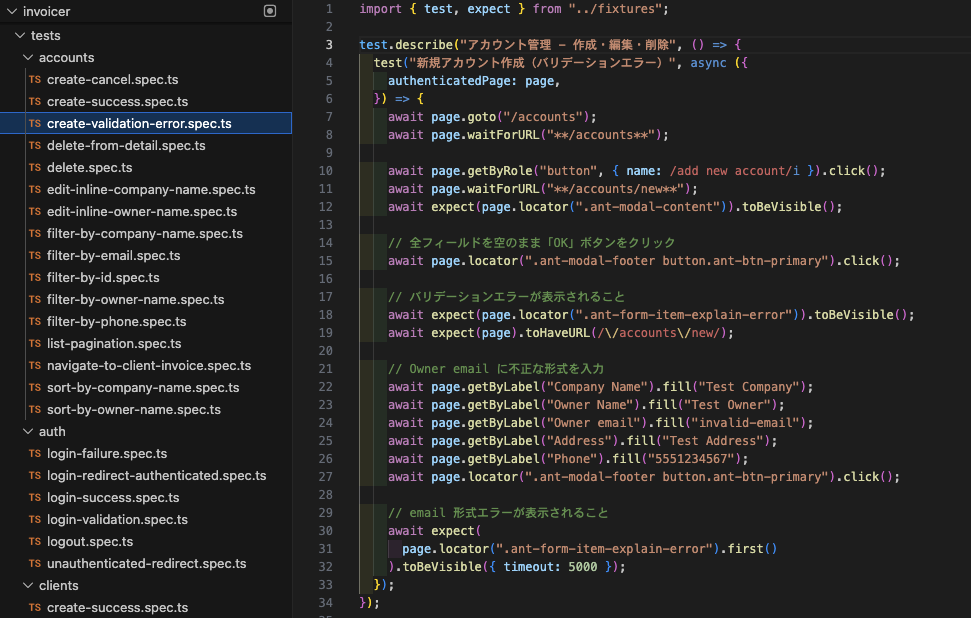
③ テストの実行と失敗の確認
生成されたテストを実行します。AIが書いたコードは一発で全て通るとは限らず、実環境との差異でいくつかFailedになることがあります。$ npx playwright test実際の実行結果です。61テスト中、16 passed / 45 failedとなりました。
Running 61 tests using 1 worker 45 failed 16 passed (10.2m) Serving HTML report at http://localhost:9323. Press Ctrl+C to quit.
④ 失敗したテストの自己修復 (Healer)
エラーが発生したテストケースをHealerエージェントに渡し、原因特定とコード修正を依頼します。🖱️ エージェントの選択: Claude Code の入力欄で @playwright と入力し、エージェント一覧からplaywright-test-healerを選択します。💬 Prompt:先ほどのテスト実行で失敗したテストケースを確認し、エラー原因(セレクタの不一致など)を特定してコードを自動修正してください。モーダル・タブ・テーマのセレクタなど、実環境固有の複数の失敗パターンを自律的に解析・修復します。
⧺ playwright-test-healer(Investigate modal, tabs, and theme selectors) ⎿ Done (167 tool uses · 1h 0m 4s)⑤ 修正後の再テストとカバレッジ確認
Healerによる修正後、カバレッジ取得オプションを付けて再度テストを実行します。今度は無事にすべてのテストケースがPass(成功)するはずです。$ npx playwright test –coverage⑥ カバレッジレポートの確認
最後に、出力されたカバレッジレポートにアクセスし、仕様に対するテストの網羅率をビジュアルで確認します。$ npx playwright show-report以下のように実行した回帰テストの状況を確認できましたね。
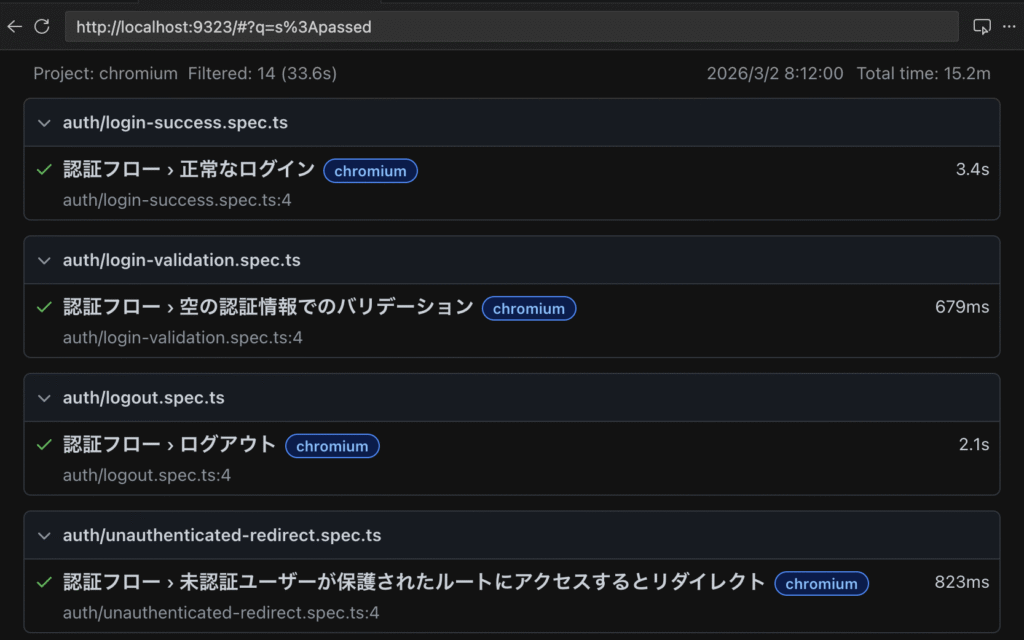
3-3. 導入効果(実証データ)
実際に上記の環境で、既存のWebアプリケーションに対する回帰テストの作成業務を行いました。通常1日(約8時間)かかる作業が、約3時間で完了(業務効率化約2.7倍)という結果が出ました。主に、自動生成されたテストの修正・検証フェーズに時間を要した点が実態の試算に反映されています。
- テスト環境構築: 約15分(MCP設定含む)
- テストプラン作成: 約25分(Plannerエージェント実測 23m 56s)
- テストコード作成: 約20分(Generatorエージェントが実装)
- テストコード修正: 約2時間(Healerエージェントによる自己修復 約1時間 + 手動レビュー・微調整)
- Healer修復前の初回実行時成功率: 約26%(16 passed / 61 tests) ← この数値は「最初の1回目」の結果です
- Healer修復後の最終成功率: Healerが失敗テストを自律的に解析・修正するため、修復後は大幅に向上します(⑤ステップで確認)
初回26%という数値は「AIが一発で書いたコードの精度」として捉えると自然です。Healerによる1時間の自律修復を経ることで成功率は大幅に向上し、その後の手動レビュー・微調整を経て最終的なテストスイートが完成します。ゼロから手書きするのに比べれば、全体のスピード感は大幅に向上します。
4. Playwright技術進化の比較
従来のPlaywrightから、今回のAgents、そして未来(2026年〜)のインテントベーステストへの進化をまとめました。
| 機能・特性 | 従来の Playwright (Traditional) |
Playwright Agents (2025) |
Intent-Based Testing (2026〜) |
|---|---|---|---|
| メンテナンス | 手動(高工数) | 半自動(自己修復機能) | ゼロ(自律型+人間確認) |
| 導入・構築時間 | 数週間単位 | 数時間単位 | 数分単位 |
| 信頼性 | 決定論的(高精度) | 変動あり(LLMに依存) | 高い(Human-in-the-loop) |
| UI変更への耐性 | 変更で即座に失敗 | 軽微な変更に対応可能 | 大幅な変更にも適応可能 |
| トークンコスト | なし | 中〜高 | 最適化済み(選択的利用) |
| 最適な用途 | 安定したクリティカルパス | 拡大中のテストスイート | 変化の激しいプロダクト |
5. 競合ツール「TestSprite」との比較
Playwright Test Agentsは強力ですが、市場には他にもAIを活用した自動化ツールが存在します。特に「TestSprite」は、2026年時点での強力な対抗馬として注目されています。
TestSpriteは「AIがAIをテストする(AI tests AI)」という哲学に基づいた自律型プラットフォームです。Playwrightが開発者のローカル環境における「強力なアシスタント」であるのに対し、TestSpriteはテストの計画からデバッグ、レポートまでをクラウド上で完結させる「マネージドなQAエージェント」です。
| 比較軸 | Playwright Test Agent | TestSprite | Mabl / Autify |
|---|---|---|---|
| 技術的アプローチ | オープンソース / MCP / コード主導 | 自律型AIエージェント / クラウド | ローコード / GUIベース |
| 自動化の深さ | ◯ 計画、生成、修復を個別に支援 | ◎ 計画から修正案提示まで全自動 | ◎ 実行時の自己修復に特化 |
| 開発者体験(DX) | ◎ Claude Code等との統合で制御性が高い | ◎ 最小限の指示で全自動実行 | 非エンジニア向け |
| ロックインリスク | ◎ ゼロ(生成物は標準コード) | 低(Playwright互換) | 高(独自プラットフォーム依存) |
| 拡張性 | ◎ MCPによる自由なツール拡張 | ◯ プラットフォーム機能に依存 | ▲ 限定的 |
| 費用 | ◎ Claude等のToken代のみ | ◯(やや高い) | ◯ プラットフォーム依存 |
| 環境構築 | ◯ Node.js等の環境が必要 | ◎ SaaSのため不要 | ◎ SaaSのため不要 |
TestSpriteの特筆すべき点として、同社Webサイト上の情報によるとAI生成コードの合格率をわずか1回の反復で42%から93%に向上させたと報告されています(※公開ベンチマークレポートでの第三者検証は未確認)。一方で、Playwright Test AgentsはMicrosoftによる公式サポート、広大なコミュニティ、そして「コードを所有し続けられる」というオープンソースの強みを持ち、長期的な技術的コントロールを重視する企業にとって魅力的な選択肢となっています。
6. 現時点における限界と課題(2026年現在)
Playwright Test Agents は非常に強力ですが、万能ではありません。現場で使う上で、主に「ロケーター」ではなく「ステート(状態)」の管理に関する課題を理解しておく必要があります。
- エージェント・ワークフローのステート管理: エージェントはボタンの操作は可能ですが、「過去24時間以内に3回決済に失敗したユーザー」といった複雑な条件(データベースの状態)のセットアップは困難です。テストデータの管理や環境の初期化には、依然として手動のオーケストレーション(調整)が必要です。
- コンテキストウィンドウの制限: LLMが一度に保持できる情報量には限界があります。動的な価格設定やクーポン適用を含む50ステップに及ぶ複雑な購入フローでは、ステップ40に達する頃にはステップ12の内容を「忘れて」しまうことがあります。
- リアクティブ(反応型)な自動修復: 自動修復は失敗した「後」に機能するものであり、プロアクティブ(予防的)ではありません。次回のリリースでどのセレクターが壊れるかを事前に予測することは不可能です。
- 生成結果のばらつき(非決定性): 同じ要求に対しても、実行ごとに生成されるコードが微妙に異なる場合があります。アサーションのスタイルや変数名、フローの構造に一貫性が欠けるリスクがあります。
- 「構造」の理解と「意味」の欠如: エージェントはUIの構造やスナップショット時点の挙動は理解しますが、アプリケーションが持つビジネス上の真の意味や背景までは理解していません。
7. 実運用に向けた利用方針
重要な点として、Playwright Test Agentsは実際のWebシステムを操作して情報を取得するため、対象システムにバグがある場合、その誤った挙動を正しいものとしてテスト計画やテストコードを生成してしまうリスクがあります。そのため、以下の3点を軸に利用方針を明確にすることが現場への安全な導入につながります。
- リグレッションテストへの適用は「現状動作の保護」と割り切る。
既存システムの挙動をそのまま「正」として扱い、リリースによるデグレを検知する用途に限定します。この目的であれば仕様書がなくても高い精度でテストを自動生成できます。 - 新機能テストや品質向上が目的の場合は、必ず仕様書(SPEC.md等)をPlannerエージェントに渡す。
エージェントに「正しい仕様」を明示することで、バグを含む実装に引きずられることなく、本来あるべき挙動に基づいたテストを生成させることができます。セクション3-2の⓪で紹介したSPEC.md生成プロンプトが、この準備として有効です。 - 生成結果(テスト計画書・テストコード)は必ず人間がレビューする。
AI生成物は完璧ではありません。ビジネスロジックの正確性や境界値のカバレッジについて、エンジニアの目で確認・補完することが、高品質なテストスイートの維持につながります。
8. まとめ
Playwright Test Agentsを検証した結果、網羅的なテスト計画の自動立案から、テストコードの生成・自動修正まで、一連のQAサイクルをAIが担えることを実証できました。
生成されたテスト計画書やコードには一部曖昧さや修正が必要な箇所もありましたが、全体として十分に実用的なレベルです。Human-in-the-loopで人間がレビュー・補完することで、ゼロから手書きするよりも大幅に効率的に自動テストを構築できます。社内のフレームセットを含むレガシーなWebシステムへの適用でも、同様の効果が得られることを検証済みです。
AIにE2E回帰テストを書かせ、直させる時代はもう始まっています。ぜひ、皆さんのプロジェクトの回帰テスト自動化にPlaywright Test Agentsを取り入れてみてください!
採用情報
次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットのさまざまなアプリケーション開発を行うアーキテクトを募集しています。募集職種一覧からご応募をお待ちしています。