2026.04.01
RAGはSpannerのハイブリッド検索がおすすめ&ベクトル検索に「答え」を投げると精度が上がる話 — ベクトル検索×フルテキスト検索×RRF融合
はじめに
こんにちは。次世代システム研究室のM.K.です。
大量の社内ドキュメントを集めて、検索したり、ナレッジを問い合わせられるシステムを作るとなったら、皆さんはどのようなシステムを考えますか?
今の世の中、生成AIのLLM (Large Language Model) を使うのは間違いないですね。そのLLMをベースに、RAG (Retrieval-Augmented Generation) か ファインチューニング (事前学習済みLLMにデータを追加学習させ特定のタスクに最適化) を考えるのではないでしょうか。
ただ、どちらも課題を抱えています。従来のRAG (原文をチャンク分割してベクトル空間にEmbedding (埋め込み表現)、ユーザーの問い合わせに近いチャンク文章を検索しそれをLLMに送って回答を生成) では問い合わせに類似した一部しか回答されず社内ナレッジを引き出しているとは言い難く、また、ファインチューニングは進化が劇的なプロプライエタリなLLM (ChatGPT, Claude, Geminiなど) でできず質の高い学習データをたくさん揃えるのが困難、といった大きな課題があります。
上記のようなプロプライエタリなLLMを使わないのは現状考えにくく、RAGをさらに発展させた高度な手法が第一候補になってくると思います。最近ではLLMに検索のループを判断させるAgentic RAG、Agentic Searchのような新しい手法も出てきました。
Agentic RAG、Agentic Searchをするにしても対象ドキュメントが大量にある場合は簡単ではありません。問い合わせに答えるために必要なドキュメントを探し漏れると適切な回答ができないため、大量にある場合は検索自体を工夫して網羅性を上げなくてはならないからです。
そこで今回はこのRAGの検索まわりで特に効果が大きかった3つの最適化について、検証データとともに紹介します。
目次
1. Spannerでハイブリッド検索をSQL一発に(RRF融合)
なぜベクトル検索だけでは足りなかったか
RAGの検索といえばベクトル検索(文章をベクトル化しそのコサイン類似度をもとに意味の近い情報を検索)が定番ですが、実際に試してみると固有名詞に弱いことがわかります。
たとえば人名「山田太郎」や案件番号「CR-001-006」で検索しても、Embedding空間ではこうした文字列はノイズになりがちで、思うようにヒットしません。一方でフルテキスト検索(ファイル本文の全てのテキストを対象にキーワードを検索)は固有名詞に強いですが、「プロジェクト管理」で検索しても「PM手法」はヒットしないという弱点があります。
実測してみたところ、ベクトル検索だけだと全体ヒット率が73.0%、固有名詞系クエリのヒット率が81.2%でした。
ヒット率の算出方法: テストクエリごとに「正解ドキュメント」を人手で定義しておき、検索結果の上位30件に正解が1件以上含まれていれば「ヒット」とカウントします。全テストクエリに占めるヒットの割合がヒット率です。固有名詞系クエリ(人名・社名・案件番号などを含む質問)で2割近く取りこぼしているのは痛いです。
ベクトル検索とフルテキスト検索を組み合わせたハイブリッド検索ができないか — というのが出発点です。
典型的なアプローチとその問題
RAGでハイブリッド検索を実装する場合、「ベクトル検索とフルテキスト検索をできるようにシステム構築して、Python側で別々に実行、結果をマージ」というアプローチがまず考えられます。
ただ、やろうとすると構築も考え事も多くて厄介です。
- ベクトル検索システムとフルテキスト検索システムの2つが必要(両方の構築・運用はとても大変…)
- スコアの正規化が必要(コサイン距離は0〜2、BM25スコアは0〜∞でスケールがまったく違う)
- マージロジックが複雑になる(重複排除、重み付け、ソート…)
- 中間結果を全部メモリに載せる(両検索の全結果をPython側で保持しないといけない)
最初はシステム設計を工夫してこのようなやり方のアプローチを検討して実装しましたが、筋が良いと思えず、悩んでいました。
Cloud Spannerという選択肢
何かよいソリューションはないかといろいろ探したら、なんとありました!それがGoogleのCloud Spannerです。Spanner といえば、結果整合性でなく強整合性 (ACID トランザクション) を保ちながら超大規模まで水平スケーリングできる高性能そして高価格なフルマネージドなデータベース、というイメージがあります。そして、Spanner を使う目的はトランザクション処理 (OLTP) とデータ分析 (OLAP) の両方を一度にできる HTAP (Hybrid Transactional/Analytical Processing) の DB 構築だと思ってました。
そんなイメージのSpannerですが、今やベクトル検索やフルテキスト検索に対応した強力な検索データベースとしても進化していました。
Google Cloudには、Vertex AI RAG Engineという、パース処理・チャンク分割・Embeddingを簡単にできる強力で便利なマネージドのRAG構築サービスがあるのですが、実はデフォルトで選択されるバックエンドのベクトル DB は Spanner となっています。ただし、RAG Engine の裏側の Spanner は現状ベクトル検索以外の機能が使えず、組み合わせて使うことができません。
Googleの様々なベクトル検索サービス: ちょっとややこしいのですが、Vertex AI RAG Engine、Vertex AI Vector Search、Vertex AI Searchと3つあり、すべて違うサービスです。生成 AI サービスで調査させる場合、Vertex AI Search ではなく Vector Search について回答しがちなので注意してください。
Spannerを自前で構築すると、Googleが開発したScaNN (Scalable Nearest Neighbors) と呼ばれる高速かつスケーラブルな近似最近傍 (ANN) ベクトル検索のインデックスと、フルテキスト検索のインデックスを同一テーブルに共存でき、ハイブリッド検索を行えることがわかりました。
ベクトル検索のpre-filterとベクトル検索の強制
Spanner の ScaNN ベクトル検索では pre-filter という強力な機能も使えます。使い方はベクトル検索を行うSQLクエリのWHERE句に書くだけで、裏側でベクトル検索をする前にWHERE句に書いた条件で絞り込んでくれるので、その条件下での結果を返してくれるようになるのと、応答速度が速くなる利点があります。
また、Spannerはクエリオプティマイザがいろいろ考えて、ベクトル検索よりフルスキャンを選ぶこともあるので、データが多いときなどはベクトル検索インデックスを必ず使うように強制するヒント句を書くことができます (@{force_index=DocEmbeddingIndex}) 。
ベクトル検索インデックスのSTORING句
ベクトル検索インデックスの作成時にSTORING句を付けることができます。STORING句にpre-filterで使う列を含めることで、CTE内のWHERE句でpre-filterを評価するときにベーステーブルへのlookupが発生しないので、インデックスだけで検索とフィルタリングが完結します。
DB側で完結させる設計
Spannerのハイブリッド検索を使えば、1つのSQLクエリのCTE (WITH句) で両方の検索を並列実行してランキングまでできないかを調べてみました。ランキングにはRRF (Reciprocal Rank Fusion – 各検索結果の順位 (rank) だけを使ってスコアを計算する融合手法) を検討しています。RRFのスコア式は 1/(K + rank) というシンプルなもので、K=60が標準的な定数です。ベクトル距離とBM25スコアのスケールが違っても、順位しか見ないので正規化なしで異種検索を融合できるのが最大の利点です。
サンプルSQL
1つで完結させるSQLクエリのサンプルがこちらです。
WITH
-- (1) フルテキスト検索: SEARCH INDEXでトークン一致
fts_results AS (
SELECT offset + 1 AS rank, doc_id
FROM UNNEST(ARRAY(
SELECT AS STRUCT doc_id
FROM documents
WHERE SEARCH(search_tokens, @fulltext_query)
ORDER BY SCORE(search_tokens, @fulltext_query) DESC
LIMIT @fetch_k
)) WITH OFFSET
),
-- (2) ベクトル検索: ScaNNで近似最近傍(pre-filter付き)
vec_results AS (
SELECT offset + 1 AS rank, doc_id
FROM UNNEST(ARRAY(
SELECT AS STRUCT doc_id
FROM documents @{force_index=DocEmbeddingIndex}
WHERE embedding IS NOT NULL
AND category = @category -- pre-filter: カテゴリで絞り込み
ORDER BY APPROX_COSINE_DISTANCE(
embedding, @query_vector,
options => JSON '{"num_leaves_to_search": 50}')
LIMIT @fetch_k
)) WITH OFFSET
),
-- (3) RRF融合: 順位ベースでスコア統合
rrf_scored AS (
SELECT
COALESCE(f.doc_id, v.doc_id) AS doc_id,
(COALESCE(1.0 / (60 + f.rank), 0.0)
+ COALESCE(1.0 / (60 + v.rank), 0.0)) AS rrf_score,
CASE
WHEN f.rank IS NOT NULL AND v.rank IS NOT NULL THEN 'both'
WHEN v.rank IS NOT NULL THEN 'semantic'
ELSE 'keyword'
END AS match_type
FROM fts_results f
FULL OUTER JOIN vec_results v ON f.doc_id = v.doc_id
ORDER BY rrf_score DESC
LIMIT @top_k
)
-- (4) Late Materialization: top_k確定後に実データ取得
SELECT r.doc_id, d.content, r.rrf_score, r.match_type
FROM rrf_scored r
JOIN documents d ON r.doc_id = d.doc_id
ORDER BY r.rrf_score DESC
参考:
UNNEST(ARRAY(...)) WITH OFFSETによるランク付けパターンは、Spannerの公式ドキュメント: Hybrid full-text and vector search patterns でも紹介されている手法です。公式サンプルではUNION ALL+GROUP BY+SUMで融合していますが、本記事ではFULL OUTER JOIN+COALESCE方式を採用しています。以下でこの2つが同じ結果を生む理由を補足します。
公式方式(UNION ALL + GROUP BY + SUM) は、2つの検索結果を UNION ALL で縦に積み、GROUP BY key でドキュメント単位にまとめてから SUM(1/(60+rank)) します。あるドキュメントが両方の検索にヒットしていれば2行あるので SUM は2項の合計になり、片方だけなら1行なので SUM はその1項だけを返します。
本記事の方式(FULL OUTER JOIN + COALESCE) は、2つの検索結果を doc_id で FULL OUTER JOIN し、1行の中で COALESCE(1.0/(60+f.rank), 0.0) + COALESCE(1.0/(60+v.rank), 0.0) を計算します。両方にヒットしていれば両項とも値が入り合計は同じ。片方だけなら、もう片方の rank は NULL になるので COALESCE(..., 0.0) が 0 を返し、結果的にヒットした側の1項だけが残ります。
つまり、どちらの方式でも「ドキュメントごとに、ヒットした検索のRRFスコアを合算する」という計算は同じです。違いは行の持ち方で、UNION ALL 方式では1ドキュメントが最大2行になるのに対し、FULL OUTER JOIN 方式では常に1行です。
どちらでヒットしたかの分類 (例:match_type) を取得するため、1行に両方の rank が揃っており、CASE WHEN f.rank IS NOT NULL AND v.rank IS NOT NULL で match_type (both / semantic / keyword) を同じクエリ内で判定できる FULL OUTER JOIN 方式を試しました。UNION ALL 方式で同じことをやろうとすると、GROUP BY の後にさらに自己結合が必要になり、かえって複雑になるためです。
データフローを図にするとこのようになります。
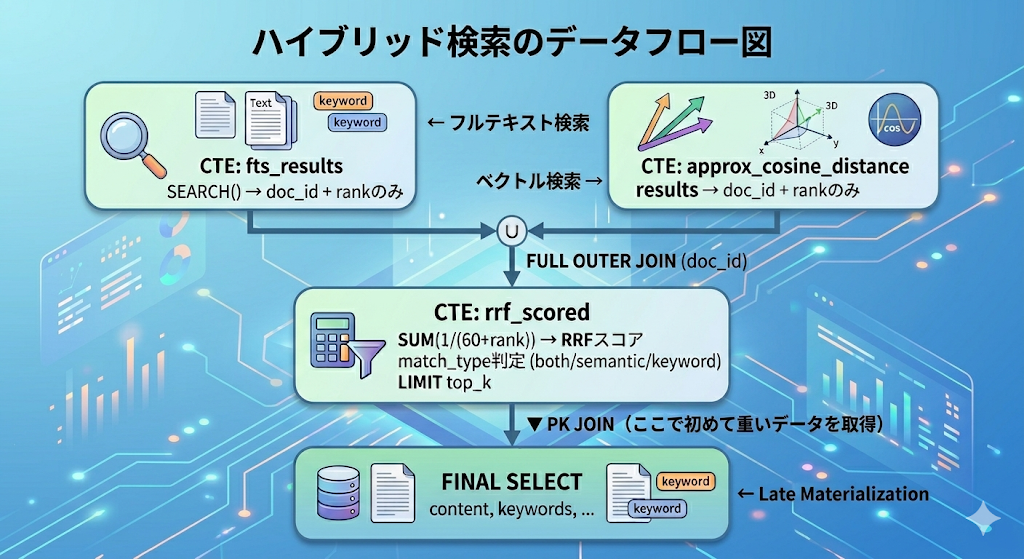
Spannerハイブリッド検索のデータフロー図
設計のポイント
このSQLには4つのポイントがあります。
(1) UNNEST(ARRAY(…)) WITH OFFSET — Spannerの制約への対処
RRFは順位を使うので、各検索結果に「何番目にヒットしたか」のランク番号を振る必要があります。普通ならROW_NUMBER() OVERを使いたいところですが、SpannerではSEARCH()関数を含むクエリ内でROW_NUMBER()が使えないという制約があります。
それで色々試した結果、サブクエリの結果を一度ARRAYに変換してからUNNEST ... WITH OFFSETで展開するパターンに落ち着きました。offset + 1でランク(1始まり)を付与しています。ベクトル検索側も同じパターンで統一したので、SQL全体が対称的な構造になっています。
このパターンは、先述のSpannerの公式ドキュメントでも採用されているアプローチです。
(2) FULL OUTER JOINによるRRF融合
フルテキスト検索にだけヒットしたもの、ベクトル検索にだけヒットしたもの、両方にヒットしたものを漏れなく拾うためにFULL OUTER JOINを使っています。
RRFスコアはSUM(1/(60+rank))で計算します。片方にしかヒットしなかった場合はCOALESCEで0を入れるだけなので、スコア計算もシンプルです。両方にヒットした文書はスコアが自然に高くなります。
(3) Late Materialization — 重いデータの遅延取得
これがレイテンシに一番効いたポイントです。
CTEの段階ではdoc_idとrankだけを扱っています。1行あたり数十バイトの軽いデータです。content(数KB)やembedding(768次元 × 4バイト ≒ 3KB)といった重いデータは、RRFスコアの計算とtop_kの選定が終わった最終段階のPK JOINで初めて取得しています。
中間段階でのデータ転送量を最小化できるので、SpannerのクエリオプティマイザとしてもCTE内の処理を効率よく実行できます。
(4) match_type — 検索経路の可視化
CASE式でboth/semantic/keywordの3種類を判定して返しています。
これがRAG側で意外と便利で、both(ベクトルとフルテキスト両方でヒット)は信頼度が高いので回答の主要根拠に使い、keyword(フルテキストのみ)は固有名詞が一致しただけの可能性があるので内容を精読してから使う、といった判断に活用できます。
検証したサンプルデータでの分布は、both: 17.6%、semantic: 72.9%、keyword: 9.5%となっていましたが、keywordだけでしかヒットしないドキュメントが約1割あるということは、ベクトル検索だけでは確実に取りこぼしていたと考えることができます。
サンプルデータでの検証結果
サンプルデータ(574件のドキュメント)での検証結果です。
検索精度:
| 指標 | 結果 | 目標 |
| recall@30 | 100%(20/20クエリ) | ≥90% |
| precision@10 | 95%(19/20クエリ) | ≥80% |
指標の説明:
- recall@30(再現率@30): 各テストクエリに対して事前に「正解ドキュメント」を人手で定義しておき、検索結果の上位30件以内に正解が含まれているかを測定します。20問すべてで上位30件に正解が含まれていたので100%です。「取りこぼしていないか」を測る指標です。
- precision@10(適合率@10): 検索結果の上位10件のうち、質問に実際に関連するドキュメントの割合です。20問中19問で上位10件がすべて関連ドキュメントだったので95%。「ノイズが混じっていないか」を測る指標です。
目標を大幅に上回りました。フルテキスト検索を足したことで固有名詞系のクエリが全件ヒットするようになったのが大きいです。
段階的な改善の推移 (Spanner 移行前の検証結果):
| ステップ | 全体ヒット率 | 固有名詞系クエリ | 施策 |
| ベクトル検索のみ | 73.0% | 81.2% | semantic only |
| + フルテキスト検索(RRF融合) | 83.3% | 100.0% | + keyword search |
※ ハイブリッド検索の効果を段階的に確認するため、Spanner 移行前に実施した検証です。Spanner 移行後も同等以上の精度 (recall@30=100%, precision@10=95%) を確認しています。
固有名詞系クエリのヒット率が81.2%→100.0%になったのは、はっきり体感できるレベルの改善でした。
レイテンシ:
| パターン | レイテンシ |
| 単一クエリ(Embedding API + Spanner RRF) | ~395ms |
| 複数クエリ並列 | ~542ms |
Embedding APIの呼び出しも含めて400ms以下なので、体感としては十分速いです。DB往復が1回で済むのが効いています。
スケール耐性:
ノイズデータを注入して87倍密度(5K件相当)までスケールさせても、recall@30=100%、precision@10=95%を維持しました。ScaNNのnum_leaves_to_search=50(全632リーフの約8%探索)という設定で、データ量を5000件に増やしてもrecallを保てることが確認できています。
スケールテストの方法: 検証環境の574件に対してランダムなEmbedding (意味を持たないベクトル) を持つノイズドキュメントを注入し、総件数を5,000件まで増加させました。正解ドキュメントがノイズに埋もれずにヒットし続けるかを確認しています。
Python側マージとの比較
最終的にPython側でのマージをやめてSQL一発にしたことで、こうなりました。
| 観点 | Python側マージ | SQL一発(本手法) |
| DB往復 | 2回 | 1回 |
| スコア正規化 | 必要 | 不要(RRFは順位のみ) |
| マージコード | 数十行 | 0行 |
| 中間データ | 全結果をメモリ保持 | DB内で完結 |
| 検索経路の可視化 | 自前で実装 | match_typeで自動分類 |
Python側のマージコードがゼロになったのが個人的に一番うれしいポイントです。マージロジックはバグの温床になりがちなので、DBに押し込めたことでテストも格段にシンプルになりました。
Spannerのコスト
ハイブリッド検索をするにはSpannerのEnterpriseエディションを選択する必要があります。「Spannerは高い」というイメージを持ってましたが、最小構成の Enterprise エディション 100 Processing Units(PU) であれば月額$140 くらいです。100 PU でも ScaNN ベクトル検索とフルテキスト検索の両方のインデックスを同一テーブルに作成でき、データサイズやリクエスト数にもよりますが数十万~数百万件規模のドキュメントでも対応できると思います。
ただ、停止してコストを抑えることができないので、検証やデモ用途であれば、用が済んだらインスタンスを削除するのをお勧めします。
2. 「質問文」より「回答文」でベクトル検索すると精度が上がる
HyDEの着想 — 「質問文」ではなく「回答文」で検索する
ハイブリッド検索でヒット率を83%まで上げた後、次はベクトル検索自体の精度を上げたいと考えました。
そこで参考にしたのが、HyDE(Hypothetical Document Embeddings, Gao+ 2022)という手法です。HyDEの核心は「質問文をそのままベクトル検索に投げるのではなく、LLMで仮想的な回答文書を生成し、その回答文のEmbeddingで検索する」というもので、質問文と文書の間には文体のギャップがあり、回答文の方が文書に近いベクトルになる、という考え方です。
例えば対象のドキュメントが「ヒアリングでは要件の優先順位確認が重要である」のような断定文が多いとした場合、ユーザーの質問は「ヒアリングで気をつけることは何ですか?」のような疑問文であることが多いと思われます。そうすると意味的には同じことを言っているのに、実際にコサイン距離を測ってみると離れていたりする。まさにHyDEが指摘している文体ギャップの問題があるわけです。
擬似回答クエリ
HyDEの着想を取り入れ、通常の質問文に加えて「擬似回答」をベクトル検索のクエリとして追加するようにしました。
具体的にはこのような感じです。
| クエリ種別 | 例(「ヒアリングの注意点」の場合) |
| 通常の質問文 | 「新規案件のヒアリングで気をつけるべきことは?」 |
| 擬似回答 | 「ヒアリングでは要件の優先順位、予算規模、納期、意思決定者の確認が重要であり…」 |
擬似回答はオリジナルのHyDEのように検索のたびにLLMで生成するのではなく、検索エージェントがテンプレート的に生成することを考えました。
通常の質問文と擬似回答を並列でベクトル検索し、結果を重複排除して統合します。
検証結果
10問のテストクエリで、通常の質問文によるベクトル検索と擬似回答によるベクトル検索を比較しました。
| 指標 | 通常の質問文 | 擬似回答 |
| 平均コサイン距離 | 0.3626 | 0.3299(9%短縮) |
| 独自発見ドキュメント数 | 4.9件/質問 | 6.1件/質問 (+24%) |
指標の説明:
- 平均コサイン距離: クエリベクトルと検索結果上位30件のドキュメントベクトル間の距離の平均。0に近いほど意味的に類似していることを示します。擬似回答(断定文)は検索対象と同じ文体なので、ベクトル空間上でより近い位置にマッピングされています
- 独自発見ドキュメント数: その方式でのみ発見され、もう一方の方式では上位30件に含まれなかったドキュメントの平均件数。擬似回答は通常の質問文では見つからないドキュメントを+24%多く発見しています
擬似回答を追加しても既存の検索結果が消失することはなく(消失0件)、純粋に発見の上乗せとなりました。
なぜ効くのか
HyDEの論文が指摘しているとおり、文体を揃えるとベクトル空間上で近くなるというのが根本の原理です。
検索対象テキストは「〜は〜である」という断定文。擬似回答も「〜は〜である」という断定文。Embeddingモデルは文の意味だけでなく文体(疑問文か、断定文か、箇条書きか…)にも影響を受けるので、同じ文体にすることで距離が縮まります。
ただ、上記の検証結果はサンプルデータにオーバーフィットしていないとは言えず、対象ドキュメントが雑多なスタイル(メール、議事録、マニュアルが混在など)だと文体一致が保証されずあまり効果が見られない可能性があります。対象ドキュメントをパースしてノイズ除去を行って特定の文体で出力するような処理を挟んでいれば有効な手段になりえると思います。
3. Batch Prediction統一でLLM APIコスト50%削減
最後に検索精度ではなくコストの話を少しだけ。
大量のドキュメントを集めたナレッジシステムを作るとすると、様々なドキュメントがあるのでパースしたりノイズ除去をうまく行う前処理が重要になってきます。LLMで前処理させるのが精度高くできてよいですが、LLMをOnline API(1件ずつリアルタイムでAPI呼び出し)で使うと、RPM (Requests Per Minute) やTPM (Tokens Per Minute) の制限に引っかからないように、状況によってはセマフォ制御やバックオフを実装しなくてはいけなくなり、大変になってきます。
並列処理のバッチを想定していたので、前処理も後続処理も同じ並列単位でやるためにOnline APIを使うことを当初は考えていましたが、RPMやTPMの制限を気にせず低コストでできるVertex AI Batch Prediction (Gemini 2.5 Flash) があることがわかり、全面移行しました。
| 項目 | Online API | Batch Prediction |
| コスト(20万件) | ~$1,465 | ~$733(50%削減) |
| RPM/TPM管理 | Rate Limitリスクあり | 不要 |
| 実装 | バックオフ・セマフォ | JSONLをGCSに置いてAPI 1回 |
コスト算出の根拠: 20万件 × 平均入力トークン数 × Gemini 2.5 Flashの単価で算出。Batch PredictionはVertex AIの公式料金表でOnline APIの50%割引が適用されるため、同一モデル・同一トークン数でコストが半額になります。
コストが半額になったのもうれしいですが、実装の簡素化が一番大きいです。Rate Limit対応のコードを全部捨てられました。JSONLファイルをGCSに置いてAPI 1回叩くだけなので、パイプラインもシンプルになります。
注意点として、SLAが最大24時間ですが、実績では大半が数時間以内に返ってきます。
追加の最適化として、Gemini 2.5 Flashのthinking_budgetを1024トークンに制限しています。今回の前処理で深い推論は不要だったので、thinkingを制限することでトークン消費が予測可能になり、コスト見積もりが安定しました。
4. まとめ
今回紹介した3つの最適化の効果をまとめます。
| 最適化 | Before | After | 改善 | 備考 |
| RRFハイブリッド検索@Spanner | recall@30=100% precision@10=95% |
+10.3pt以上 | Spanner 移行前でヒット率 73.0%→83.3%を確認後、移行後さらに改善。サンプルデータ 574件での検証 | |
| 擬似回答クエリ(固有発見) | 4.9件/質問 | 6.1件/質問 | +24% | サンプルデータ 574件・10問での検証 |
| Batch Prediction(20万件見積り) | ~$1,465 | ~$733 | -50% | 件数 × 平均トークン数による推定。BatchはオンラインAPIの半額 (Gemini 2.5 Flash) |
所感
- Spannerはもう進化したRAG検索用データベース
- Spannerのハイブリッド検索を駆使することで、簡単に高性能なベクトル検索とフルテキスト検索ができて、コードがシンプルになり、レイテンシも下がり、メリットが大きかったです。フルマネージドでないことと、停止ができず最小構成でも月額2万円程度かかるのが難点ですが、生成 AI 開発時代の検索基盤としては非常に強力な選択肢です。
- Spannerでベクトル検索 (ScaNN) とフルテキスト検索を同居させてCTEで一発融合するパターンは、RAG 検索を実装する際のベストプラクティスの一つかもしれないと思っています。
- 擬似回答クエリはうまく使えば有効
- 擬似回答クエリへの書き換えは HyDE の着想をベースに、LLM呼び出し不要にアレンジしたアプローチです。文体が統一されたデータとの相性が特に良く、「質問文より回答文の方がヒットする」というのは直感に反しますが、Embeddingモデルが文体に影響を受けることを考えれば理にかなっています。
- Batch Predictionは積極的に使おう
- JSONLを準備しないといけないという癖がちょっとありますが、大量にLLM処理する場合はBatch Predictionは有効と思います。
3つの最適化はそれぞれ独立しているので、RAGの検索精度やコストに課題を感じている方は、自分の環境に合うものから試してみるとよいかもしれません。
最後に
AI研究開発室では、データサイエンティスト/AIエンジニアを募集しています。AI/LLMを活用したシステム開発、AI×ロボットなどにご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD