2019.04.02
SPARK2.3におけるCATALYSTのOptimizerを実装してみた
こんにちは、次世代システム研究室のT.D.Qです。
最近、ビッグデータ解析PRJに参加しまして、複数のシステムからデータを収集し、データ分析が可能な形に変換してデータウェアハウスへ格納する作業をやっています。今回は構築したHDP3.1を使ってSpark 2.3.2のパフォーマンスの改善を調査してみましたので、このブログで紹介したいと思います。
検証環境
今回は、GMOアプリクラウドにてサーバー8台を使ってHDP3.1を構築し、検証しました。
| ノード数 | メモリ | Cores数 |
|---|---|---|
|
8 |
24GB |
16 |
実際に色々なサービスをインストールしましたが今回の記事に関係あるサービスのみリストアップしました。
| サービス名 | バージョン | 備考 |
|---|---|---|
|
Hadoop (HDFS+YARN+MapReduce2) |
3.1.1 |
大規模データの分散処理を支えるオープンソースのソフトウェアフレームワーク |
|
Spark2 |
2.3.2 |
オープンソースのクラスタコンピューティングフレームワーク |
|
Zeppelin Notebook |
0.8.0 |
ブラウザ上でプログラムをインタラクティブに記述できるノートブック |
Whole-stage Code Generation
まずは、構築したHDP3.1クラスタのSPARK 2.3.2のパフォーマンスを計測してみました。Spark 2.3.2は「Whole-stage Code Generation」という最適化機能が搭載されているのですが、この機能でどのくらいのパフォーマンスが改善できるか検証しましょう。今回は、整数10億個を生成して合計する処理でSparkのパフォーマンスを計測します。
// Define a simple benchmark util function
def benchmark(name: String)(f: => Unit) {
val startTime = System.nanoTime
f
val endTime = System.nanoTime
println(s"Time taken in $name: " + (endTime - startTime).toDouble / 1000000000 + " seconds")
}
// この設定でwhole stage code generationが無効にする
spark.conf.set("spark.sql.codegen.wholeStage", false)
benchmark("Spark 1.6") {
spark.range(1000L * 1000 * 1000).selectExpr("sum(id)").show()
}
実行結果です。「whole stage code generation」が無効にすると22.36秒かかりました。
+------------------+ | sum(id)| +------------------+ |499999999500000000| +------------------+ Time taken in Spark 1.6: 22.36483518 seconds
spark.conf.set("spark.sql.codegen.wholeStage", true)
benchmark("Spark 2.x") {
spark.range(1000L * 1000 * 1000).selectExpr("sum(id)").show()
}
+------------------+ | sum(id)| +------------------+ |499999999500000000| +------------------+ Time taken in Spark 2.x: 0.650196664 seconds
Spark 2.3.2で「Whole-stage Code Generation」を有効にすると、単純な合計計算だとなんとパフォーマンスが22秒以上から0.65秒に改善されました。ただし、複雑な式・多数のカラムがあるプログラムには、whole-stage codegenによる最適化が適用されません。
SPARK CATALYST OPTIMIZER
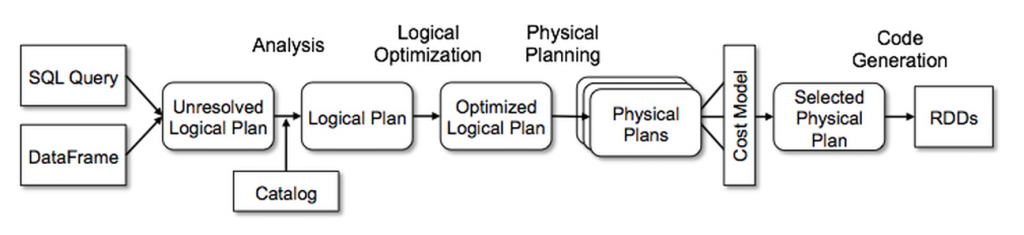
Sparkのバッチが実行してからRDDに変換されるまでは上記の画像の通り、Catalystエンジンによる複数の最適化ステップが実行されます。Apache Spark 2.3から、Catalyst optimizerという機能が搭載されて、この機能によって生成されるJavaコードが改善されました。ただし、搭載したCatalyst Optimizerだけでは、Sparkの処理(特にSpark SQL)を全て最適化できるわけではないので、場合によっては開発者が自分のCustomizerを開発して最適化する必要があります。
SPARK CATALYSTのOptimizerの実装
今回は、構築したHDP3.1のApache Zeppelinで実装し、実行結果を考察しました。シナリオとしては、連続整数の1億レコードのTBLと5,000万レコードのTBLを生成して、この2TBLにて被っている部分の件数をカウントします。この処理がどのくらい時間がかかるか計測します。
まずは、連続整数の1億レコードのTBLを生成します。これをtableAとします。
val tableA = spark.range(100000000).as('a)
tableA.count
tableA: org.apache.spark.sql.Dataset[Long] = [id: bigint]
res50: Long = 100000000
続いて、5,000万レコードのTBLを生成し、これをtableBとします。
val tableB = spark.range(50000000).as('b)
tableB.count
tableB: org.apache.spark.sql.Dataset[Long] = [id: bigint] res51: Long = 50000000
上記のテーブルを結合し、被っている部分のカウント処理を実行する前に、外部のOptimizerをクリアします。
spark.experimental.extraStrategies = Nil
spark.experimental.extraStrategies: Seq[org.apache.spark.sql.Strategy] = List()
対象テーブルを結合してカウント結果を表示します。
val result = tableA
.join(tableB, $"a.id"===$"b.id")
.groupBy()
.count()
result.show()
SPARK JOB FINISHED
+--------+ | count| +--------+ |50000000| +--------+ result: org.apache.spark.sql.DataFrame = [count: bigint] Took 1 min 14 sec. Last updated by admin at April 02 2019, 11:31:19 AM.
実行時間が1分14秒ですね。次は実行したPhysicalプランを確認しましょう。
result.explain()
== Physical Plan ==
*(6) HashAggregate(keys=[], functions=[count(1)])
+- Exchange SinglePartition
+- *(5) HashAggregate(keys=[], functions=[partial_count(1)])
+- *(5) Project
+- *(5) SortMergeJoin [id#417L], [id#426L], Inner
:- *(2) Sort [id#417L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(id#417L, 200)
: +- *(1) Range (0, 100000000, step=1, splits=2)
+- *(4) Sort [id#426L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#426L, 200)
+- *(3) Range (0, 50000000, step=1, splits=2)
ここで、注目したいのが、SortMergeJoin処理ですね。「Exchange hashpartitioning」もあって、Sparkで一番遅いと言われるShuffle処理が発生するので、この部分を排除できたらパフォーマンスの改善を期待できます。Spark 2.3.2では自分のCatalyst Optimizerを使って新しい計算ロジックを適用できるので、 今回のJoin処理をやめて、被っている部分のカウント処理を別の方法でやり直したいと思います。 具体的には下記のソースコードを参照ください。
import org.apache.spark.sql.Strategy
import org.apache.spark.sql.catalyst.expressions.{Alias, EqualTo}
import org.apache.spark.sql.catalyst.plans.logical.{LogicalPlan, Join, Range}
import org.apache.spark.sql.catalyst.plans.Inner
import org.apache.spark.sql.execution.{ProjectExec, RangeExec, SparkPlan}
case object IntervalJoin extends Strategy with Serializable
{
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case Join(
Range(start1, end1, 1, part1, Seq(o1), false), // tableAのデータ
Range(start2, end2, 1, part2, Seq(o2), false), // tableBのデータ
Inner, Some(EqualTo(e1, e2))) // Joinを行う
if ((o1 semanticEquals e1) && (o2 semanticEquals e2)) || ((o1 semanticEquals e2) && (o2 semanticEquals e1)) =>
// tableAとtableBのデータが被っている部分のみ抽出する
if ((end2 >= start1) && (end2 <= end2)) {
// 被る部分の開始点
val start = math.max(start1, start2)
// 被る部分の終了点
val end = math.min(end1, end2)
val part = math.max(part1.getOrElse(200), part2.getOrElse(200))
// 被っている部分(Range)を結果として返す
val result = RangeExec(Range(start, end, 1, Some(part), o1 :: Nil, false))
val twoColumns = ProjectExec( Alias(o1, o1.name)(exprId = o1.exprId) :: Nil, result)
twoColumns :: Nil
} else {
Nil
}
case _ => Nil } }
実装したOptimizerをSparkのextraStrategiesオプションに設定します。
spark.experimental.extraStrategies = IntervalJoin :: Nil
この形で計算処理を再実行します。
val result = tableA
.join(tableB, $"a.id"===$"b.id")
.groupBy()
.count()
result.show()
SPARK JOB FINISHED +--------+ | count| +--------+ |50000000| +--------+ result: org.apache.spark.sql.DataFrame = [count: bigint] Took 0 sec. Last updated by admin at April 02 2019, 11:32:59 AM.
計算結果が同じですが、処理時間が1秒未満で計算終わりました!処理の詳細を確認しましょう。
result.explain()
== Physical Plan ==
*(2) HashAggregate(keys=[], functions=[count(1)])
+- Exchange SinglePartition
+- *(1) HashAggregate(keys=[], functions=[partial_count(1)])
+- *(1) Project
+- *(1) Project [id#417L AS id#417L]
+- *(1) Range (0, 50000000, step=1, splits=2)
SortMergeJoin処理がなくなり、参照(Project)とカウント(Aggregate)のみ実行されたので、 処理時間が大幅に短縮されました。素晴らしい結果を得ることができました。
いかがでしょうか?「Whole-stage Code Generation」及び「Catalyst Optimizer」によるSpark 2.3.2のパフォーマンスを紹介しました。検証結果が示すように、これら二つの機能を適用することで処理時間を大幅に改善することができました。 ビッグデータ解析への活用・応用には検討する価値が十分ありそうですね。それでは、また。
最後に
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD


