2024.10.07
LangGraphでSelf RAGを構築し、RAGの回答精度をアップデートしよう。
導入
こんにちは。グループ研究開発本部 次世代システム研究室のH.Oです。今回もAIアプリケーション開発の話題をお届けしたいと思います。これまで数回にわたってLangChainを用いてLLMを組み込んだアプリケーション開発について発表してきました。今回は、RAG(検索拡張生成)の精度をさらに高める手法としてSelf RAGを取り上げ、Self RAGをLangChain ecosystemを用いて実装する方法について紹介します。グループ研究開発本部は、2024年9月26日に、「AI・LLM・ML基盤 – GMO次世代勉強会 2024秋【Online】」を開催させていただきましたが、今回の記事の内容は、私が当勉強会で発表させていただいた内容を元に、特にSelf RAGに関して、より詳しい内容を補足したものとなっています。
目次
モチベーション
LLMをアプリケーションに組み込む際に、そのLLMが、特定領域の専門知識を持っておらず、最新の情報が反映されないため、生成結果が課題解決にとって不十分なものになってしまう、という問題点にしばしば直面します。その対策としてRAG(検索拡張生成)という手法が非常にポピュラーです。
ところが、シンプルにRAGを構築しても、実際にプロンプトを投げてみると期待する精度の応答が返ってこないということがしばしば起きます。その大きな原因として考えられるのは下記の二点です。
- 質問に関係しないドキュメントを参照している。
- LLMの生成結果にハルシネーションが含まれている。
そのため、「この2点の課題を改善したい」というのが今回のモチベーションです。
結論
- RAGに一手間、二手間、工夫を施したAdvanced RAGを実装することで、応答の精度が高められる。
- 数あるAdvanced RAGのうち、最も新しく手が込んだ手法としてSelf RAGがあり、これはLangGraphというフレームワーク(LangChain ecosystemに含まれている)を用いて実装することができる。
Self RAGとは
RAGの応答精度を向上させる手法であるAdvanced RAGの中の一つで、2023年10月ごろに発表された新しい手法です。質の低い検索結果や生成結果をLLMを使用して自己修正する仕組みになっていて、回答品質の向上、ハルシネーションの減少といったメリットがあります。
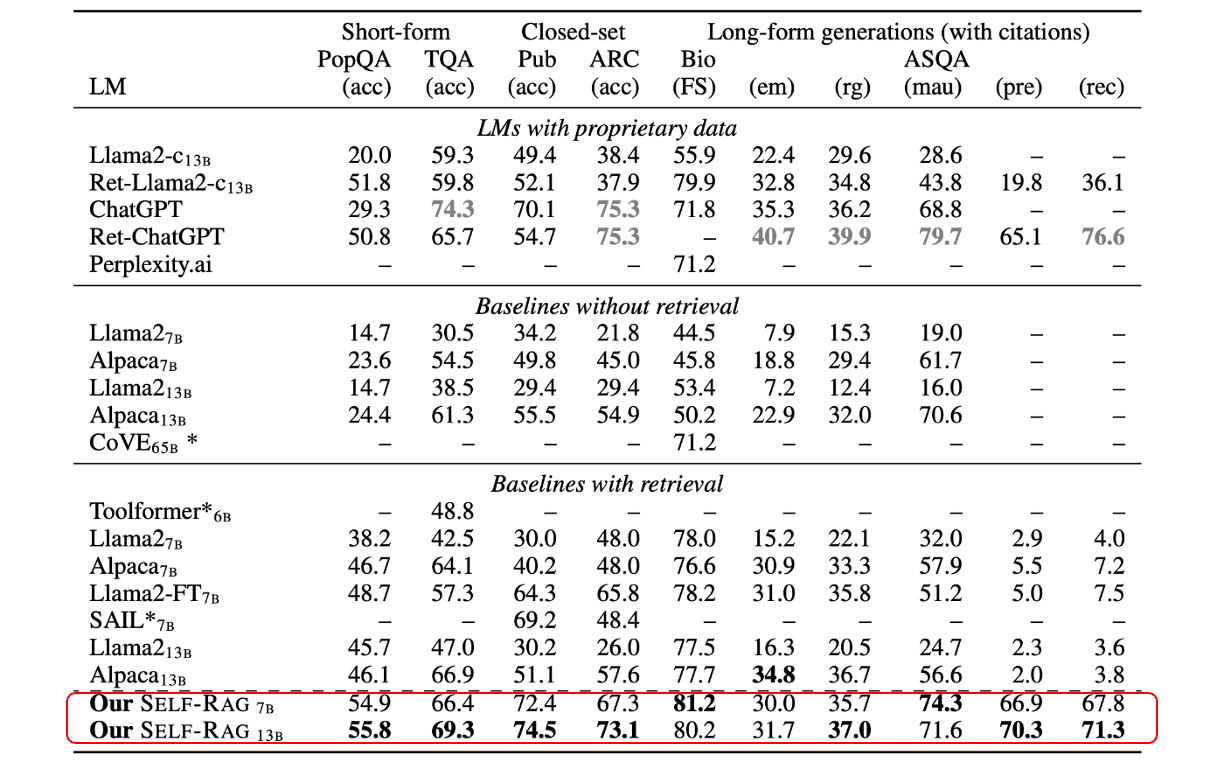
論文では下記のようなベンチマークが公表されており、応答の精度が向上していることが発表されています。
理論的背景
Self RAGの理論的な処理のフローについて解説します。
処理フロー
Self RAGは以下の4つのフェーズから出来上がっています。
- LLMをファインチューニングし文章の生成の途中でReflection tokenを混ぜ込めるようにする
- ユーザーの質問に対し、まず検索の要否を判断する。検索しない場合はそのままLLMにプロンプトを送って回答を生成する。
- 検索をする場合、検索処理で取得した複数の文書を基に、それぞれ回答を生成する。
- 3で生成された複数の回答を評価し、最も良い応答を選択
Reflection Tokenとは何か
Self RAGで最も重要な概念の一つにReflection tokenというトークンがあります。まず最初に、使用するLLMをファインチューニングし文章の生成の途中でReflection tokenを混ぜ込めるようにします。
Reflection tokenとは、推論フェーズ中に LM を制御できるようにし、さまざまなタスク要件に合わせて動作を調整するための特別なトークンです。例えば、生成中に複数回検索したり、検索を完全にスキップしたりできると言った適応的な検索を可能にします。
Self RAGでは以下の4種類のReflection Tokenを使います。

- Retrieve: 文書検索を行うかどうか判断するために使用するトークン
- ISREL: 文章検索で取得したdocumentがinputに対し関連性のある情報かどうかを示すトークン
- ISSUP: inputとdocumentから生成したoutputがdocumentの内容をどの程度正しく含んでいるか3段階評価で示すトークン
- ISUSE: outputの内容はinputの内容が適切に使用され、supportされているか、5段階評価で示すトークン
Reflection Tokenを発行するアルゴリズムは下記の通りとなっています。

Self RAGの実装
実装方針
ここからは、Self RAGを実装し、シンプルなRAGと生成結果を比較していきたいと思います。しかし、Self RAGを実装する上で、早速困る点が出てきます。
- そもそもファインチューニングした独自のLLMが必要ではないのか?
- 検索結果や生成結果を元に処理を分岐する実装は可能なのか?
結論:ファインチューニングした独自のLLMを使わずに、フレームワークを用いるだけで、Self RAGを実装できます。
これを実現してくれるのがLangChain ecosystemに含まれているLangGraphというフレームワークです。
技術選定
使用する技術コンポーネントは下記の通りです。(バージョンに要注意)
- Python 3.12
- LangChain v0.3
- LangServe 0.3.0
- LangGraph 0.3.0
基本となるフレームワークはLangChainです。2024年9月にリリースされたばかりの0.3系を使用しています。2024年2月に0.2系が出たばかりなので、わずか7ヶ月で新しい系統に切り替わってしまいました。重要な変更点として、内部で使われているpydanticのバージョンを2系にupdateするというものがあります。0.2系のLangChainはpydantic1系と2系の両方に依存しており、両者の互換性がないため、methodが動かないことが頻発していて、複雑な対応を迫られていました。
(例えば、今回の実装では、LangServeが依存しているFastAPIが使っているpydanticと、LangChainのメソッドの内部で使われているpydanticのversionが合わずに動かないという問題に悩まされました。)
0.3系を使うことによってこの問題が当面解決されます。
LangServeは、以前の記事でも紹介した、LangChain製のアプリケーションを構成するためのフレームワークです。LangServeはFast APIに依存していて、LangChain で作ったLLM Chainを、Rest API のアプリケーションとしてdeployできます。また、同時にLangServeが自動的に作成したend pointからplaygroundを開くことができて、画面からAPIを叩けるようになります。
LangGraphは、複数のAgentやChainを定義し、それら一つひとつのAgentやChainを一つの単位とした、ループ処理や分岐を実装することができるフレームワークです。AgentやChainをNode、処理の分岐などを制御する判定処理をEdgeとよび、これらをつなげたグラフ構造を用いて複数のAgentやChainが協調して動作するフローを実装していきます。今回紹介するAdvanced RAGやMulti Agent Workflowと呼ばれるような、複数のAgentをグループや階層構造に整理して、複雑なフローを構築するのに使います。
処理のフロー
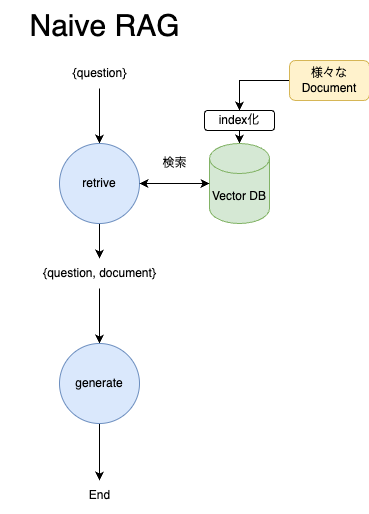
まず初めにシンプルなRAG、これからNaïve RAGと呼びますが、そのフローがこちらの図です。ユーザーの質問に対して、関連するIndexを検索して、promptに含めてからLLMの応答結果を得る。という流れです。こちらはLangGraphを使わなくても、LangChainでchainを一個作ればおしまいです。(以前の記事で紹介させていただきました。)
一方でこちらが、今回実装したSelf RAGの処理フローになっています。今回は、Self RAGのフローを通過することで回答精度が改善するところを見たいので、一番最初の「検索すべきかどうか」の判定は省略しています。
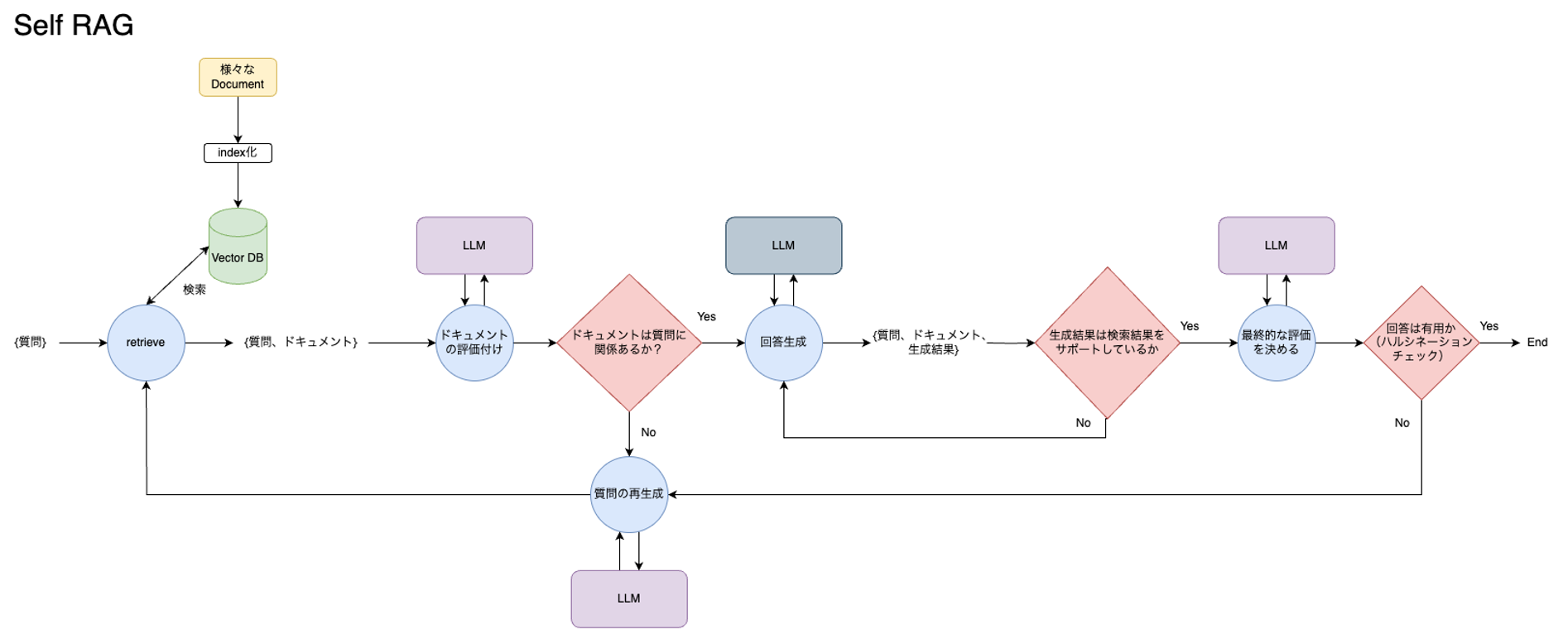
図にすると複雑です。一つひとつ処理を見ていきます。
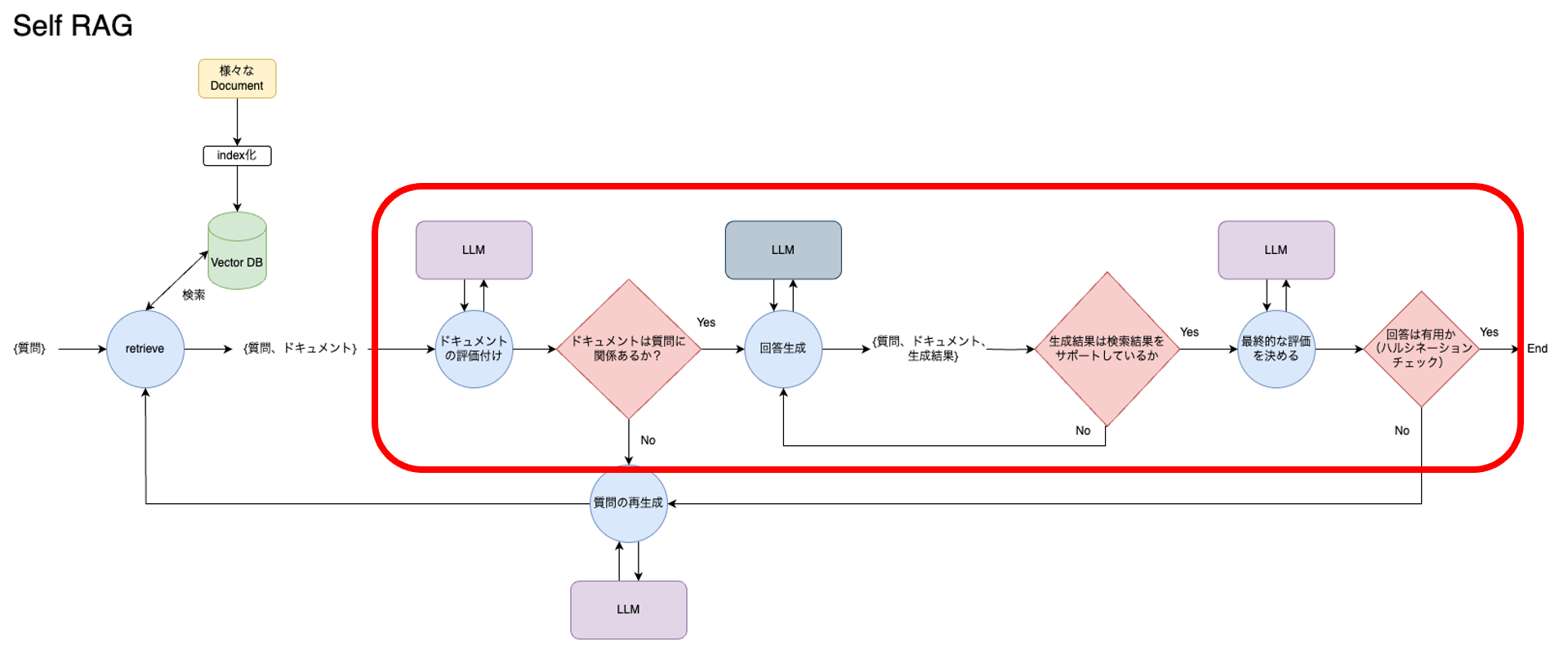
最も注目すべき点は、ドキュメントを検索した後に、その検索結果や、RAGの生成結果を評価するフローを組み込んでいることです。この赤枠で囲った部分は「ファインチューニングしたLLMが行うはずのReflection Tokenによる検索結果・生成結果の評価」に当たる処理です。Reflection Tokenを生成するようにLLMをファインチューニング代わりに、LLMにシステムプロンプトと検索結果、回答結果を渡し、その評価を返すような複数のAgentをLangGraphで連携させることで、同値な処理を作っています。
なぜ、同値な処理が実装できるのかというと、先述のReflection Token生成のアルゴリズムを、そのまま「LLMの呼び出し」-> 「評価結果に基づく次の処理の分岐」に置き換えることができるからです。これを模式的に表すと下記の図のようになります。

この図の丸に当たる部分を、そのままLangChainのAgentとして実装します。
これをLangGraphのNodeに設定し、各条件分岐をLangGraphのEdgeとして設定します。
それでは、各Agentの実装内容を見てきます。
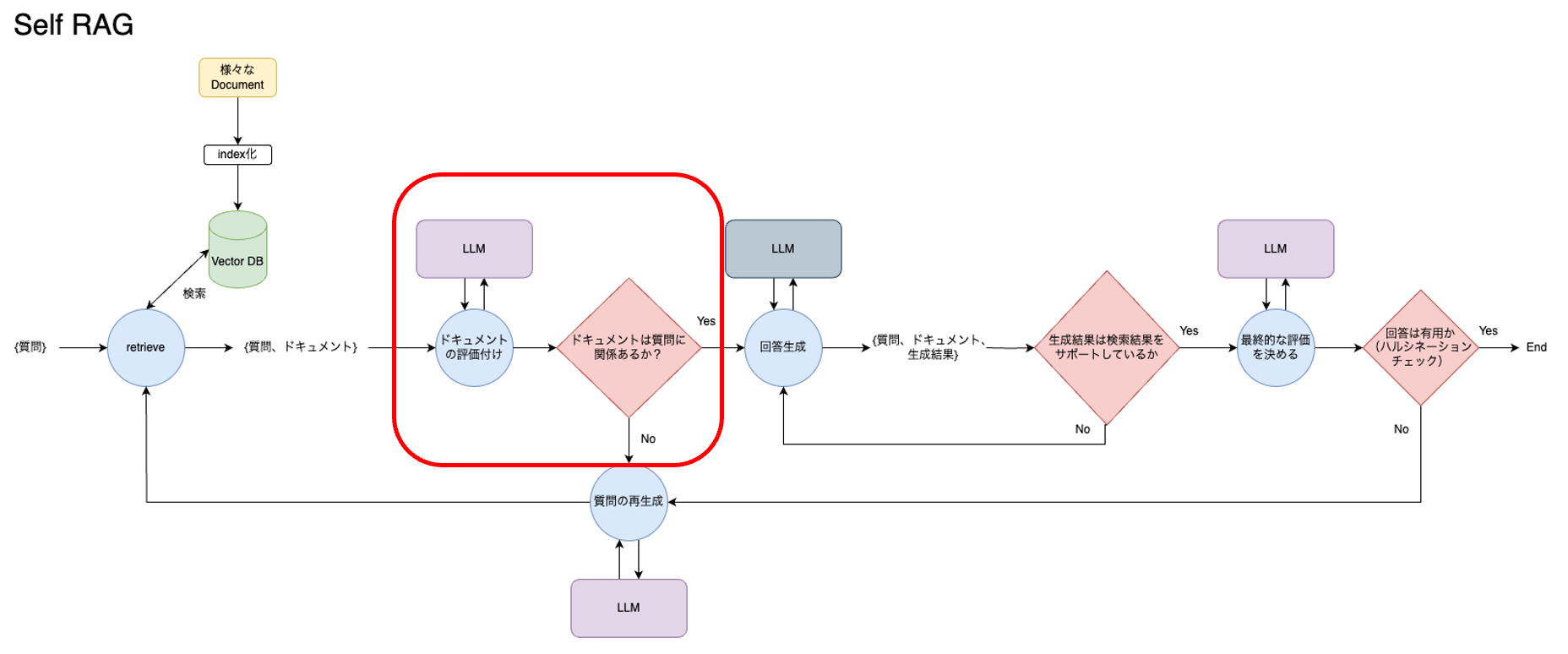
まず1つ目、ドキュメントを検索した直後に、ドキュメントチャンクのパッセージが質問に関連しているかどうかという観点でドキュメントの質を評価しています。質の高いドキュメントがあれば、それを基にして回答を生成し、そうでなければ、質問を再生成します。
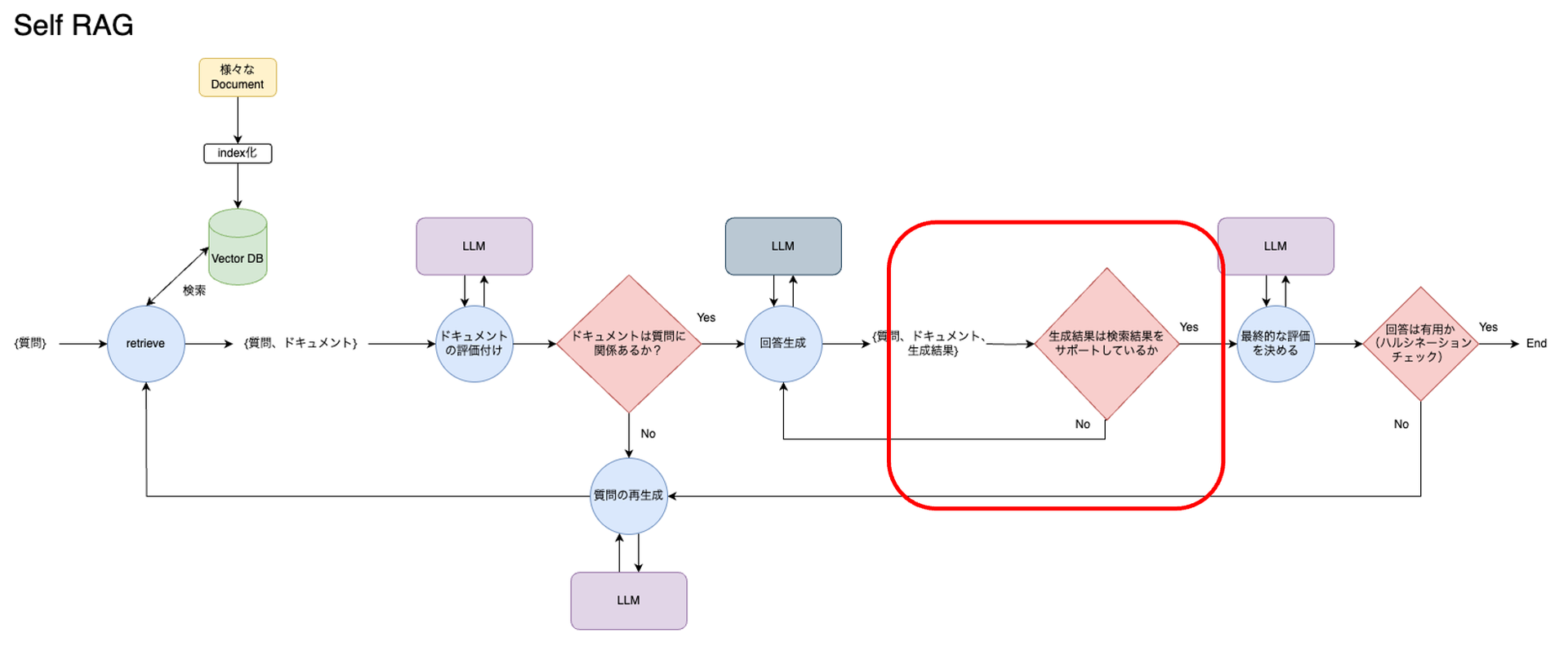
2つ目、各チャンクをもとに回答を生成した直後に、その回答がドキュメントに関連しているのか、サポートしているのかを評価します。Noであれば、再度回答生成に戻ります。
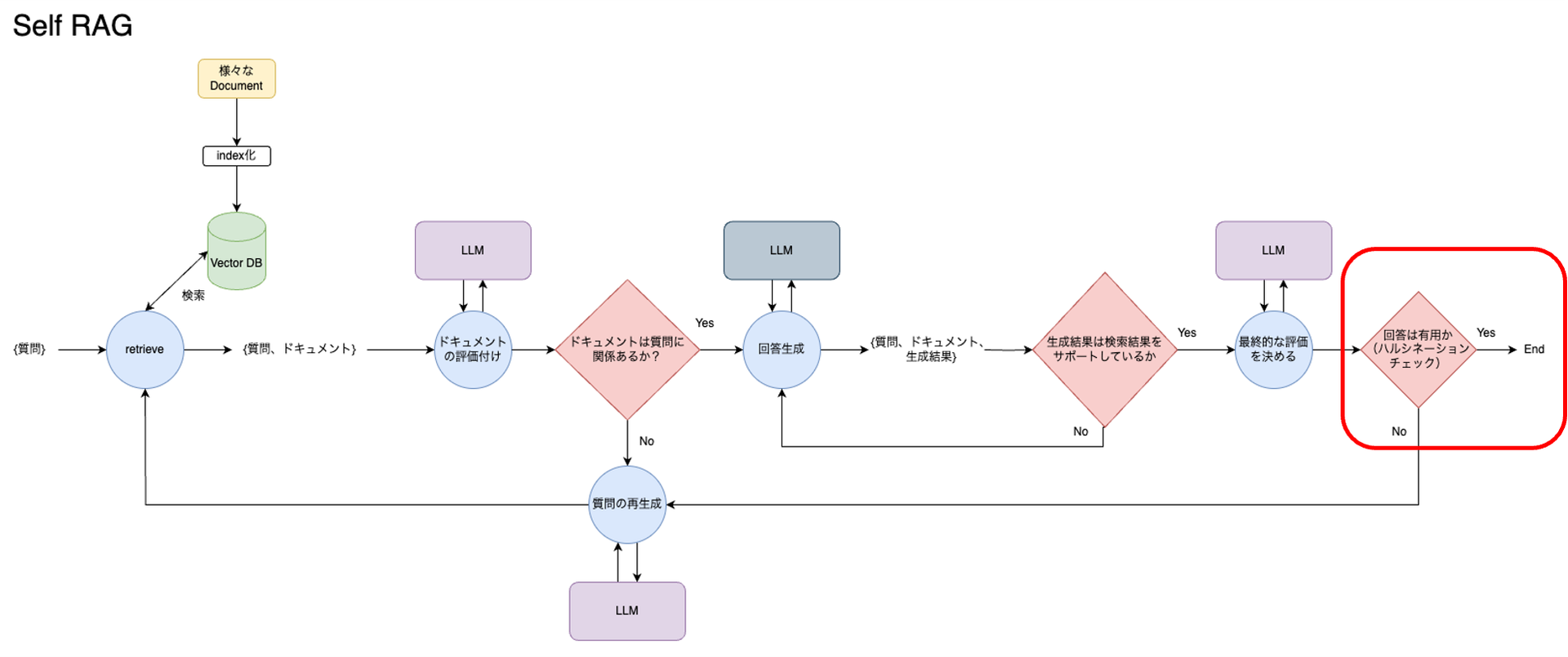
さらに3つ目、先ほどの結果がyesであれば、生成された回答が質問に対して有用かどうかを最終的に評価し、有用であれば終了します。有用でなければ質問を再生成してプロセスを繰り返します。各ステップはこのような条件付きで進んでいって、この流れで最終的な回答が決定されます。
コード
今回、回答の生成・各種評価に用いるLLMはGPT4o-miniを用いています。他のモデルを用いたい場合はLangChainが用意している別のメソッドを使用するよう置き換えることで、簡単に変更できます。
なお、Self RAGの実装はLangGraphのtutorial をに依拠していますが、アプリケーションとしてデプロイするのに工夫を加えています。
ディレクトリ構成
.
├── Dockerfile
├── README.md
├── app
│ ├── __init__.py
│ ├── graph.py
│ ├── server.py
│ └── shared.py
├── packages
│ └── README.md
└── pyproject.toml
graph.py
LangGraphでSelf RAGのflowを実装していきます。
依存関係のimport
from langgraph.graph import END, StateGraph, START from pprint import pprint from typing import List from typing_extensions import TypedDict from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader from langchain_openai import OpenAIEmbeddings from langchain_community.vectorstores import Chroma from bs4 import BeautifulSoup as Soup from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from pydantic import BaseModel, Field import app.shared as shared from langchain_core.output_parsers import StrOutputParser from langchain import hub load_dotenv()
GraphState
LangGraphでは、GraphStateというクラスで、question(質問)、generation(生成結果)、documents(検索結果)を状態管理します。各Node・Edgeの処理を通過することで、これらの状態が更新されていき、条件分岐の判定に用いられます。
class GraphState(TypedDict):
"""
Represents the state of out graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]
Node
retrieve (Indexの検索をするNode)
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
retriever = create_retriever()
documents = retriever.invoke(question)
print({"documents": documents, "question": question})
return {"documents": documents, "question": question}
def create_retriever():
urls = ["https://tenbin.ai/media/chatgpt/chatgpt-introduction"]
docs = []
for url in urls:
loader = RecursiveUrlLoader(
url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text
)
doc_list = loader.load()
docs.extend(doc_list) # 各Documentをdocsリストに追加
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=4500, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(
documents=splits, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
return retriever
generate(LLMにquestion, documentを送信し、生成結果を得るNode)
def generate(state):
"""
Generate an answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains the LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
print(question)
print(documents)
rag_chain = execute_rag_chain()
generation = rag_chain.invoke({"context": documents, "question": question})
print({"generation": generation})
return {"documents": documents, "question": question, "generation": generation}
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
def execute_rag_chain():
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
rag_chain = prompt | llm | StrOutputParser()
return rag_chain
gradeDocuments (検索結果を評価するNode)
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documentは質問と関係がありますか。Yes or No"
)
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = []
retrieval_grader = execute_retrieval_grader()
for d in documents:
score = retrieval_grader.invoke({"question": question, "document": d.page_content})
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
print({"documents": filtered_docs, "question": question})
return {"documents": filtered_docs, "question": question}
def execute_retrieval_grader():
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Retrieved document: \n\n {document} \n\n User question: {question}",
),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
retriever = create_retriever()
shared.docs = retriever.get_relevant_documents(shared.question)
doc_txt = shared.docs[1].page_content
print(retrieval_grader.invoke({"question": shared.question, "document": doc_txt}))
return retrieval_grader
transform_query (Userが入力した質問をより良いものに書き直すNode)
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("""---TRANSFORM QUERY---""")
question = state["question"]
documents = state["documents"]
question_rewriter = execute_question_rewriter()
better_question = question_rewriter.invoke({"question": question})
print({"documents": documents, "question": better_question})
return {"documents": documents, "question": better_question}
def execute_question_rewriter():
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
system = """You a question re-writer that converts an input question to a better version that is optimized \n
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Here is the initial question: \n\n {question} \n Formulate an imporved question."),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
# question_rewriter.invoke({"question": shared.question})
return question_rewriter
Edge
回答を生成するか質問を再生成するか判断する
def decide_to_generate(state):
"""
回答を生成するか、質問を再生成するかを決定します。
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---")
return "transform_query"
else:
print("---DECISION: GENERATE---")
return "generate"
生成結果の最終チェックを行う
def grade_generation_v_documents_and_question(state):
"""
生成された回答が文書に基づいているか、質問に答えているかを判断します。
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
hallucination_grader = execute_hallucination_grader()
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
grade = score.binary_score
answer_grader = execute_a_grader()
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADRESSES QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answerは事実に基づいていますか。Yes or No"
)
def execute_hallucination_grader():
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
# hallucination_grader.invoke({"documents": shared.docs, "generation": shared.generation})
return hallucination_grader
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answerが質問に対応していますか。Yes or No"
)
def execute_a_grader():
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Question: {question} \n\n LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
# answer_grader.invoke({"question": shared.question, "generation": shared.generation})
return answer_grader
最後に定義したNodeとEdgeをSelf RAGのフローに合わせて並べます。
def self_rag():
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()
return app
server.py
APIのendpointを定義します。
注意点は、実装したLangGraphをそのまま、LangServeのadd_routes()の第2引数には入れられない点です。LangServeの第2引数はRunnable型を継承したものでなければならないため、内部的に作成したgraphを実行する(graph.stream())カスタムのChainを作成する必要があります。
また、input/output typeを指定することで、/selfrag/playgroundに用意されているプレイグラウンド画面からプロンプトを送信することができるようになります。
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
from langserve import add_routes
from langchain_core.runnables.base import Runnable
from pprint import pprint
from app.graph import self_rag
from langchain_core.messages.human import HumanMessage
from typing import Dict
from langchain_core.runnables import chain
app = FastAPI(
title="Self RAG Test Application",
version="0.1",
description="This is a test self rag application for the langgraph project.",
)
graph = self_rag()
# カスタムチェーンの実装
class CustomChain(Runnable):
def invoke(self, input: str, config: Dict) -> str:
inputs = {"question": input}
output_str = ""
for output in graph.stream(inputs, config):
print(output.items())
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
return output_str
custom_chain = CustomChain()
add_routes(
app,
custom_chain.with_types(input_type=str, output_type=str),
path="/selfrag"
)
@app.get("/")
async def redirect_root_to_docs():
return RedirectResponse("/docs")
# Edit this to add the chain you want to add
# add_routes(app, NotImplemented)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
これで実装は終わりです。
langchain serve でLangServeが起動できたら成功です。(事前にlangchain cliをinstallしてください。)
デモ
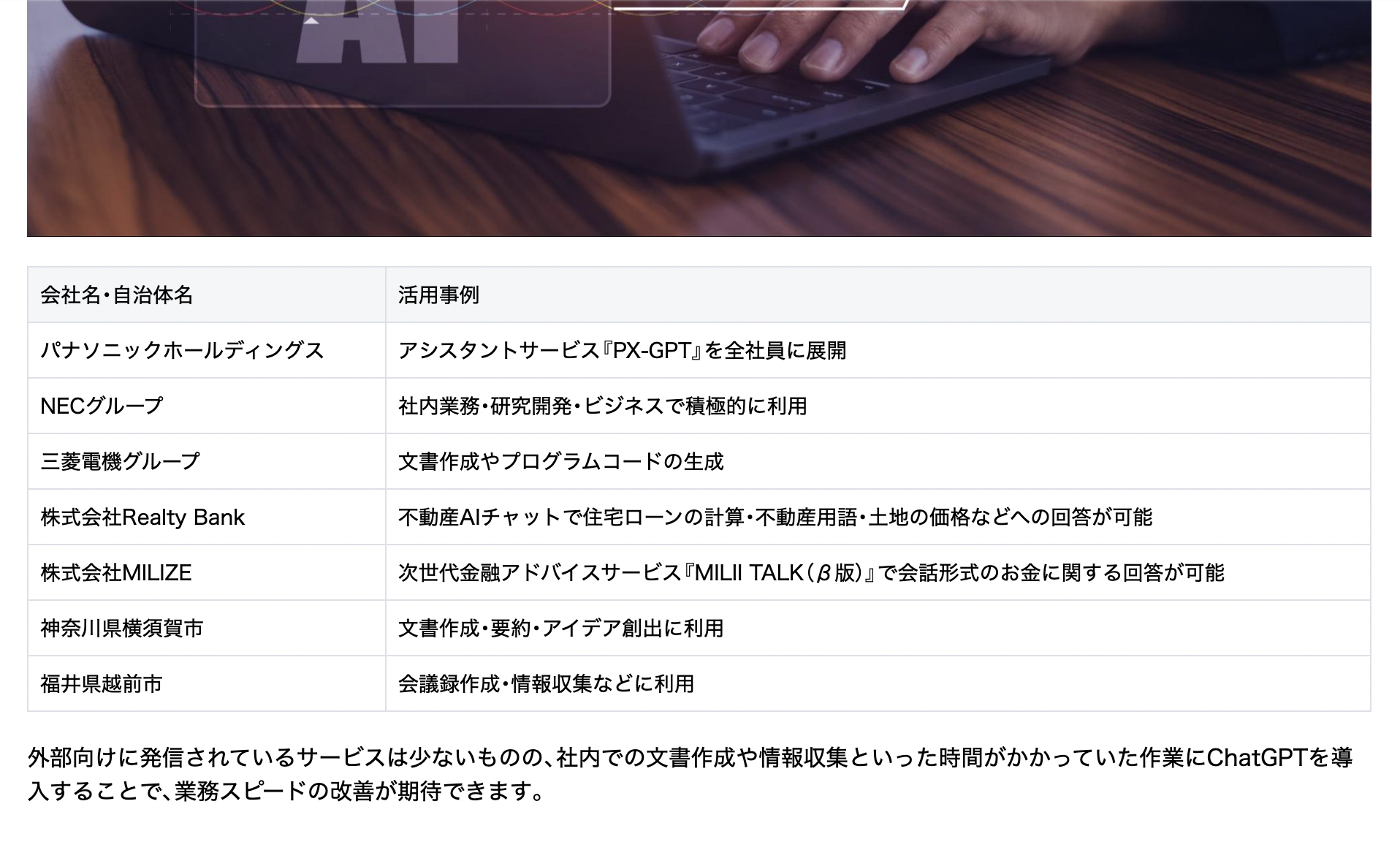
今回はIndexとして、天秤AI mediaで公開されているこちらの記事を使いました。
質問は「ChatGPTの企業・自治体の活用事例を天秤AI mediaの記事を参考にして教えてください」というものです。
期待する回答
記事には、企業・自治体の活用事例が、具体的な団体名とともに、表形式で書かれています。固有名詞レベルで具体的な回答が得られることをゴールとすることで、回答精度の向上がわかりやすく評価できると考えました。
Naive RAGの回答結果
Naive RAGに投げてみると、こちらのような回答が返りました。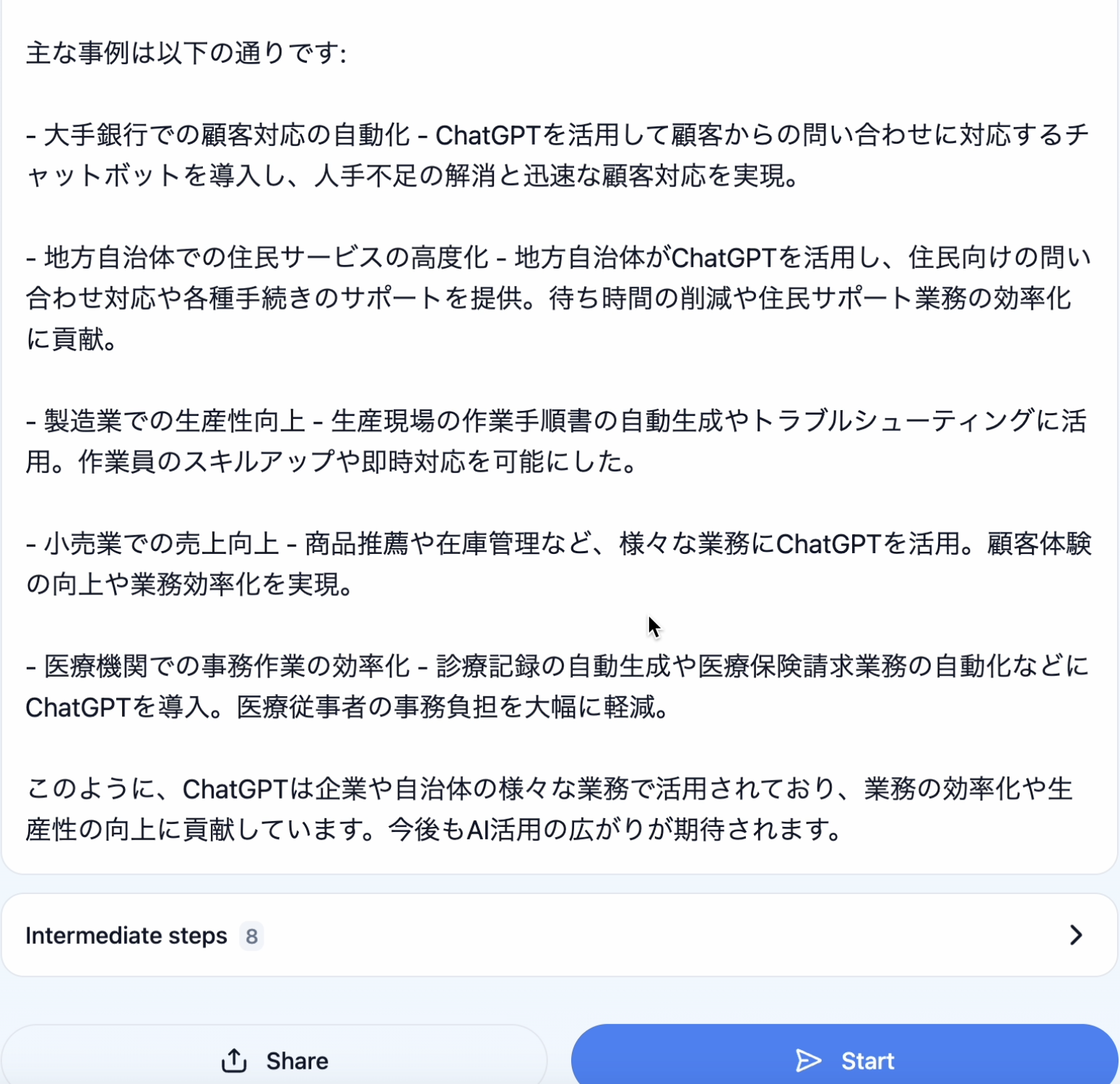
言っていることは間違っていないですが、期待する回答のような具体性はなく、一般論に終始しています。
Self RAGの回答結果
Self RAGに投げてみると、こちらのような回答が返りました。
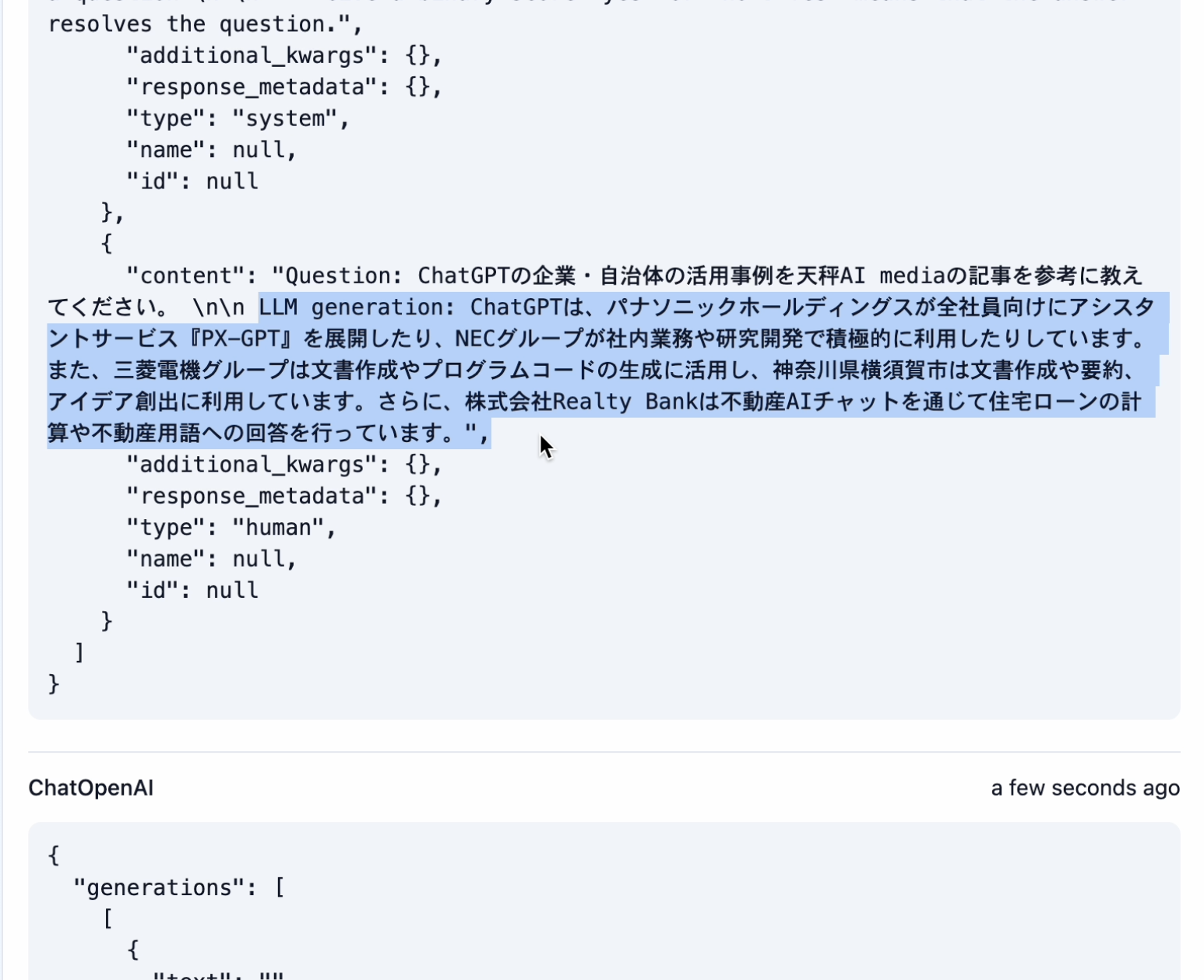
Self RAGが出力した回答は、期待する回答と内容が完全に一致しています。回答の精度が向上したことがはっきりとわかると思います。
Self RAGの課題
回答精度は明らかに向上したSelf RAGですが、問題点もあります。
Self RAGは、回答が生成されるのに10秒弱かかっていました。内部的にLLMの呼び出しを何回も行うため、レイテンシーが犠牲になってしまう点が課題です。そのため、多くのUserが利用するWeb Applicationに組み込むことは残念ながら現実的ではないと言わざるを得ません。一方でレイテンシーを犠牲にしてでも、正確な情報を取得したい業務改善系の用途であれば、効果が期待できると感じました。
まとめ
- RAGに一手間、二手間、工夫を施したAdvanced RAGを実装することで、応答の精度が高められる。
- Self RAGは、数あるAdvanced RAGのうち、最も新しく手が込んだ手法で、LangChain ecosystemの中にあるLangGraphというフレームワークを用いて実装することができる。
参考資料
- https://blog.langchain.dev/agentic-rag-with-langgraph/ (LangGraphを使ってSelf RAGが実装できる理論的根拠)
- https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_self_rag/(実装内容)
- https://arxiv.org/pdf/2310.11511 (Self RAG 論文)
- https://tenbin.ai/media/chatgpt/chatgpt-introduction (indexとして使用)
- https://zenn.dev/knowledgesense/articles/67dd2a41fc4d0b (Self RAGの解説)
- https://zenn.dev/mizunny/articles/a92d95a26da32e (Advanced RAGの解説)
最後に
グループ研究開発本部 次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネット上の高度なアプリケーション開発を行うエンジニア・アーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD