2026.02.02
LLM推論エンジンSGLangの話
こんにちは、グループ研究開発本部・AI研究開発室のA.Zです。
大規模言語モデル(LLM)の急速な進化に伴い、効率的な推論エンジンの重要性がますます高まっています。ChatGPTやClaude、Geminiなどの大規模言語モデルが日常的に使用されるようになった今、これらのモデルをいかに高速に、そして効率的に動作させるかは、サービス提供者にとって重要な課題となっています。
本記事では、高性能なLLM推論エンジンである SGLang について詳しく解説します。特に、SGLangのコア技術である Radix Attention の仕組みに焦点を当て、なぜこの技術がKVキャッシュを効率的に処理できるのかを深く掘り下げて説明します。また、他の推論エンジンとの比較、そして実際の構築例も紹介します。
1. SGLangとは
1.1 SGLangの概要
SGLang は、UC Berkeleyの研究チームが開発した、大規模言語モデル(LLM)およびマルチモーダルモデル向けの高性能推論フレームワークです。2023年末に公開されて以来、急速に発展を遂げ、現在では多くの企業や研究機関で採用されています。
SGLangが従来の推論エンジンと大きく異なる点は、プログラミング言語とランタイムシステムを共同設計(co-design) したアーキテクチャを採用していることです。これにより、単なる推論エンジンとしてだけでなく、複雑なLLMアプリケーションを効率的に記述・実行するためのプラットフォームとしても応用できます。
1.2 なぜSGLangが必要なのか
現代のLLMアプリケーションは、単純な一問一答の形式から、より複雑なワークフローへと進化しています。例えば:
- マルチターン会話:ユーザーとの継続的な対話
- RAG(Retrieval-Augmented Generation):外部知識を検索して回答を生成
- エージェント:複数のツールを呼び出しながらタスクを遂行
- 構造化出力:JSONやXMLなど特定のフォーマットでの出力
これらのアプリケーションでは、同じプレフィックス(システムプロンプトや会話履歴など)が繰り返し使用されることが多く、従来の推論エンジンではこれらを毎回再計算していました。SGLangは、このような非効率を解消するために設計されています。
1.3 SGLangの主な特徴
SGLangには以下のような特徴があります:
- Radix Attention
- KVキャッシュをRadix Tree(基数木)で管理し、共通プレフィックスを自動的に検出・再利用する技術。詳細は次章で説明します。
- 構造化生成
- JSON Schema、正規表現、文脈自由文法(CFG)に基づいた制約付き生成をサポート。無効な出力を防ぎ、後処理の手間を削減します。
- マルチモーダル対応
- テキストだけでなく、画像や動画を含むマルチモーダルモデル(LLaVA、Qwen-VLなど)にも対応しています。
- スケーラビリティ
- Tensor Parallelism(TP)、Data Parallelism(DP)、Pipeline Parallelismによるマルチ GPU・マルチノード推論をサポート。
- OpenAI互換API
- 既存のOpenAI SDKやLangChainなどのフレームワークとシームレスに統合可能です。
- ゼロオーバーヘッドスケジューラ
- 効率的なバッチスケジューラにより、スケジューリングのオーバーヘッドを最小化しています。
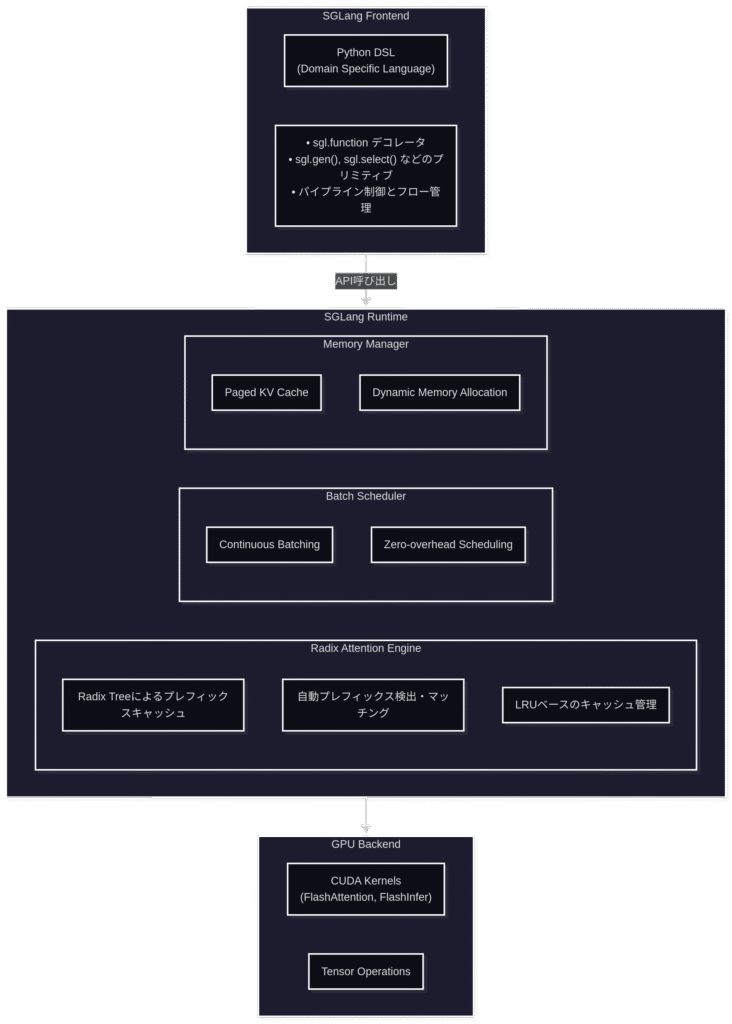
1.4 SGLangのアーキテクチャ
SGLangは大きく分けて2つのコンポーネントで構成されています:
- SGLang Frontend
- SGLang Runtime
詳細的なコンポネント内容の構成は以下のグラフになります
2. Radix Attention:効率的ななKVキャッシュ再利用技術
Radix Attentionは、SGLangの核心となる技術であり、LLM推論のパフォーマンスを劇的に向上させる革新的なアプローチです。この章では、Radix Attentionがなぜ効率的なのかを、基礎から詳しく解説します。
2.1 前提知識:Transformerの推論とKVキャッシュ
2.1.1 Transformerの自己回帰生成
Transformerベースの言語モデル(GPT、LLaMA、GLMなど)は、自己回帰(autoregressive) 方式でテキストを生成します。これは、1トークンずつ順番に生成していく方式で、各トークンの生成時には、それまでに生成された全てのトークンを参照する必要があります。
入力: "今日の天気は" 生成プロセス: Step 1: "今日の天気は" → "晴れ" Step 2: "今日の天気は晴れ" → "です" Step 3: "今日の天気は晴れです" → "。" ...
2.1.2 Attention計算の仕組み
Transformerの各層では、Self-Attention(自己注意機構) が計算されます。この計算には、以下の3つのベクトルが使用されます:
- Query (Q):現在生成しようとしているトークンの「質問」ベクトル
- Key (K):各トークンの「識別」ベクトル
- Value (V):各トークンの「内容」ベクトル
Attention計算の数式は以下の通りです:
Attention(Q, K, V) = softmax(Q × K^T / √d_k) × V
ここで重要なのは、新しいトークンを生成する際、現在のトークンのQueryと、全ての過去のトークンのKey・Value を使って計算を行う必要があるということです。
2.1.3 KVキャッシュの必要性
もしKVキャッシュがなければ、新しいトークンを生成するたびに、全ての過去のトークンについてKey・Valueを再計算する必要があります。これは計算量が膨大になり、非常に非効率です。
KVキャッシュなしの場合(非効率): Step 1: "今日" のK,Vを計算 Step 2: "今日の" → "今日"と"の"のK,Vを再計算 Step 3: "今日の天気" → "今日"と"の"と"天気"のK,Vを再計算 Step 4: "今日の天気は" → 全てのK,Vを再計算 ... → O(n²)の計算量が必要!
KVキャッシュ を使用すると、一度計算したKey・Valueを保存しておき、次のトークン生成時に再利用できます:
KVキャッシュありの場合(効率的): Step 1: "今日" のK,Vを計算 → キャッシュに保存 Step 2: "の" のK,Vのみ計算 → キャッシュに追加 Step 3: "天気" のK,Vのみ計算 → キャッシュに追加 Step 4: "は" のK,Vのみ計算 → キャッシュに追加 ... 新トークンのK,Vのみ計算すればOK → O(n)の計算量で済む!
2.2 従来のKVキャッシュ管理の問題点
KVキャッシュは推論効率化に不可欠ですが、従来の管理方式にはいくつかの重大な問題がありました。
2.2.1 メモリの非効率な使用
従来の方式では、各リクエストに対して独立したKVキャッシュ領域が割り当てられます。しかし、多くのリクエストは同じシステムプロンプトを共有していることが多いです。
従来方式の問題: リクエスト1: [システムプロンプト] + [ユーザー質問A] リクエスト2: [システムプロンプト] + [ユーザー質問B] リクエスト3: [システムプロンプト] + [ユーザー質問C] 各リクエストで同じシステムプロンプトのKVキャッシュを 別々に保持 → メモリの無駄! 例:システムプロンプトが1000トークン、同時に100リクエスト処理 → 同一データが100回重複してメモリに存在
2.2.2 計算の重複
同じプレフィックスを持つリクエストでも、それぞれ独立にKVキャッシュを計算していました:
従来方式での計算:
リクエスト1: システムプロンプト(1000トークン)のK,V計算 → 10ms リクエスト2: システムプロンプト(1000トークン)のK,V計算 → 10ms(同じ計算の繰り返し!) リクエスト3: システムプロンプト(1000トークン)のK,V計算 → 10ms(同じ計算の繰り返し!)
2.2.3 マルチターン会話での非効率
チャットアプリケーションでは、会話が進むにつれて履歴が蓄積されます。従来方式では、新しいメッセージを送るたびに会話履歴全体のKVキャッシュを再計算していました:
マルチターン会話の例:
Turn 1: [System] + [User1] + [Assist1] Turn 2: [System] + [User1] + [Assist1] + [User2] + [Assist2] Turn 3: [System] + [User1] + [Assist1] + [User2] + [Assist2] + [User3] + [Assist3] 従来方式: 毎回、全履歴のKVキャッシュを再計算 → 会話が長くなるほど遅延が増大
2.3 Radix Tree(基数木)とは
Radix Attentionを理解するためには、まずRadix Tree(基数木) というデータ構造を理解する必要があります。
2.3.1 Radix Treeの基本概念
Radix Treeは、文字列を効率的に格納・検索するためのツリー構造です。通常の木構造と異なり、単一の子ノードしか持たないノードを圧縮することで、メモリ効率と検索効率を向上させています。
通常の木構造:
root
|
t
|
e
/ \
a s
| |
m t
|
(end)
格納文字列: "team", "test"
Radix Tree(圧縮あり):
root
|
te
/ \
am st
格納文字列: "team", "test"
→ 共通部分"te"を1つのノードに圧縮!
2.3.2 Radix Treeの特性
| 特性 | 説明 |
|---|---|
| プレフィックス共有 | 共通の接頭辞を持つ文字列は、同じノードを共有します |
| 空間効率 | 単一子ノードの圧縮により、メモリ使用量を削減 |
| 高速検索 | プレフィックスマッチングがO(m)(mは検索文字列長)で可能 |
| 動的更新 | 新しい文字列の挿入・削除が効率的 |
2.4 Radix AttentionによるKVキャッシュ管理
2.4.1 トークンシーケンスのツリー構造化
Radix Attentionでは、トークンシーケンスをRadix Treeに格納します。各ノードには、そのトークン(またはトークン列)に対応するKey-Valueベクトルが保存されます。
Radix AttentionのKVキャッシュ構造:
[root]
│
┌───────────┴───────────┐
│ │
[System Prompt A] [System Prompt B]
KV: cached KV: cached
│ │
├─────┐ └─────┐
│ │ │
[User Q1] [User Q2] [User Q3]
KV:cached KV:cached KV:cached
│ │
[Assist1] [Assist2]
KV:cached KV:cached
2.4.2 自動プレフィックス検出
新しいリクエストが来ると、SGLangは自動的にRadix Treeを走査し、既存のプレフィックスとのマッチングを行います:
新リクエスト処理フロー:
1. 新リクエスト: [System Prompt A] + [User Q4]
2. Radix Treeを走査:
- [System Prompt A] → ✓ マッチ!キャッシュ再利用
3. 分岐点から新しいノードを作成:
- [User Q4] のみKVを新規計算
4. ツリー更新:
[root]
│
┌───────────┴───────────┐
│ │
[System Prompt A] [System Prompt B]
KV: cached(再利用) KV: cached
│
├─────┬─────┐
│ │ │
[User Q1][User Q2][User Q4] ← 新規追加
2.4.3 効率化のメカニズム
Radix Attentionが従来方式より効率的な理由を、具体的な数値で説明します:
シナリオ: 同一システムプロンプト(1000トークン)で100リクエストを処理 【従来方式】 - 計算量: 1000トークン × 100リクエスト = 100,000トークン分のKV計算 - メモリ: 1000トークン × 100リクエスト = 100,000トークン分のKVキャッシュ 【Radix Attention】 - 計算量: 1000トークン × 1回 = 1,000トークン分のKV計算(99%削減!) - メモリ: 1000トークン × 1回 = 1,000トークン分のKVキャッシュ(99%削減!) → 共通プレフィックスが多いほど、削減効果が大きい
2.4.4 LRUベースのキャッシュEviction
GPUメモリには限りがあるため、全てのKVキャッシュを永続的に保持することはできません。Radix Attentionでは、LRU(Least Recently Used) アルゴリズムを使用して、効率的にキャッシュを管理します:
LRUの仕組み:
- メモリが逼迫した場合、最も長く使用されていないノードから削除
- 葉ノード(末端)から優先的に削除(共通プレフィックスを保護)
- 頻繁にアクセスされるプレフィックスは長期間保持
例:
- システムプロンプト: 高頻度アクセス → 長期保持
- 個別ユーザー質問: 低頻度アクセス → 優先的に削除
2.5 なぜRadix AttentionはKVキャッシュを効率的に処理できるのか
ここまでの説明を踏まえ、Radix Attentionが効率的な理由を整理します:
2.5.1 計算の重複排除
計算の重複排除
従来方式:
- リクエスト1: [Prefix] → K,V計算
- リクエスト2: [Prefix] → K,V計算(重複!)
- リクエスト3: [Prefix] → K,V計算(重複!)
Radix Attention:
- リクエスト1: [Prefix] → K,V計算 → ツリーに保存
- リクエスト2: [Prefix] → ツリー検索 → キャッシュ再利用
- リクエスト3: [Prefix] → ツリー検索 → キャッシュ再利用
→ 同一プレフィックスの計算は1回のみ!
2.5.2 メモリの効率的な共有
Radix Treeの特性:
- 共通プレフィックスは物理的に1つだけ存在
- 複数のリクエストが同じノードを参照(ポインタ共有)
- 分岐点以降のみ、個別にメモリ確保
メモリレイアウト:
┌──────────────────┐
│ System Prompt KV │ ← 1つのメモリ領域
└────────┬─────────┘
│
┌───────┼───────┐
↓ ↓ ↓
[Q1 KV] [Q2 KV] [Q3 KV] ← 個別のメモリ領域
→ 共通部分のメモリ使用量を大幅削減!
2.5.3 トークンレベルの細粒度マッチング
従来のブロック単位のキャッシング(vLLMのPrefix Cachingなど)と比較して、Radix Attentionはトークンレベルでの細粒度マッチングを行います:
ブロック単位 vs トークン単位の比較: プロンプト例: A: "あなたは優秀なアシスタントです。質問に答えてください。" B: "あなたは優秀なアシスタントです。コードを書いてください。" 【ブロック単位キャッシング(16トークン単位と仮定)】 - ブロック1: "あなたは優秀なアシスタントです。" (完全一致 → 再利用可) - ブロック2: "質問に答えてください。" vs "コードを書いてください。" → ブロック全体が異なる → 再利用不可 【トークン単位キャッシング(Radix Attention)】 - "あなた"、"は"、"優秀な"、"アシスタント"、"です"、"。" → 全て再利用可! - "質問/コード" 以降のみ新規計算 → より多くのトークンでキャッシュ再利用が可能!
2.5.4 動的なキャッシュ管理
動的なキャッシュ管理
| ステップ | 機能 | 説明 |
|---|---|---|
| 1 | 自動検出 | 新リクエストのプレフィックスを自動的に検出 |
| 2 | 即座の再利用 | マッチした部分は計算をスキップ |
| 3 | インクリメンタル更新 | 新しいトークンのみツリーに追加 |
| 4 | 適応的Eviction | 使用パターンに基づいて最適なキャッシュ維持 |
3. SGLangと他の推論エンジンの比較
3.1 主要な推論エンジンの概要
現在、LLM推論エンジンとして主に以下のものが利用されています。それぞれに特徴があり、ユースケースによって最適な選択は異なります。
| エンジン | 開発元 | 主な特徴 |
|---|---|---|
| SGLang | UC Berkeley | Radix Attention、構造化生成 |
| vLLM | UC Berkeley | PagedAttention、高いメモリ効率 |
| TensorRT-LLM | NVIDIA | GPU最適化、最高の単一クエリ性能 |
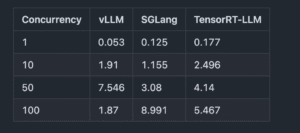
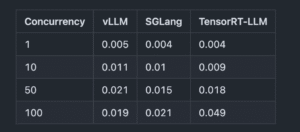
3.2 詳細なパフォーマンス比較
最初のトークン生成までの時間 (TTFT)(秒)
トークンごとのレイテンシ(秒)
全体スループット(トークン/秒)
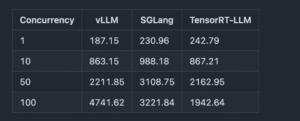
参照: https://www.clarifai.com/blog/comparing-sglang-vllm-and-tensorrt-llm-with-gpt-oss-120b
- 高負荷(Concurrency=100)では、vLLMが最も高いスループット, TFFT, トークンごとのレイテンシを実現しています。
- SGlangは低〜中負荷(Concurrency=10〜50)では、vLLMを上回る性能を発揮しています。
- TensorRT-LLMは高負荷(Concurrency=100)では、vLLMを下回る性能を発揮しています。また、低〜中負荷(Concurrency=10〜50)では、そこまで優位な性能が発揮されていませんでした。
では、どんなときに、SGLangが最適なのでしょうか?具体的に、以下の利用ケースによって、SGLangの優位性が発揮されます。
-
マルチターンチャットボット
- 会話履歴のキャッシュが自動的に再利用される
- ターン数が増えても性能劣化が少ない
-
構造化データ抽出
- JSON Schemaや正規表現による制約付き生成
- 無効な出力の生成を防止
- SGLangのフロントエンドAPIを利用することで、LLMの結果を返す前に、事前SGLang側でに判定・処理行う
-
共通プレフィックスを持つバッチ処理
- 同一のシステムプロンプトで多数のリクエストを処理
- RAGアプリケーションでの複数クエリ処理
-
複雑なワークフロー統合
- Pythonコード(SGLangのフロントエンドAPI)による柔軟な制御
- 分岐やループを含む複雑なロジック
4. SGLangの構築例:OpenAIのGPT-OSS-20B
ここでは、OpenAI/GPT-OSS-20Bモデルを使用したSGLangサーバーの構築方法を、ステップバイステップで説明します。
4.1 環境構築
4.1.1 環境情報
- Python 3.13
- CUDA 12.6
- GPU NVIDIA RTX 4090 24GB
- OS Debian 13
4.1.2 インストール手順
# 1. 仮想環境の作成(推奨) python -m venv sglang-env source sglang-env/bin/activate # 2. SGLangのインストール pip install "sglang[all]>=0.4.0" # 3. FlashAttentionのインストール(オプション、高速化に推奨) pip install flash-attn --no-build-isolation # 4. インストール確認 python -c "import sglang; print(sglang.__version__)"
4.2 サーバー起動
python3 -m sglang.launch_server --model-path openai/gpt-oss-20b
4.3 クライアントからの利用
4.3.1 OpenAI互換API
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:30000/v1",
api_key="EMPTY"
)
response = client.chat.completions.create(
model="openai/gpt-oss-20b",
messages=[
{"role": "system", "content": "あなたは優秀なプログラミング教師です。"},
{"role": "user", "content": "Pythonでフィボナッチ数列を教えてください。"}
],
temperature=0.7,
max_tokens=512
)
print(response.choices[0].message.content)
回答:
<|channel|>analysis<|message|>The user asks in Japanese: "Pythonでフィボナッチ数列を教えてください。" They want explanation of Fibonacci sequence in Python. We need to provide code and explanation, maybe iterative, recursive, generator. Possibly show examples. Provide explanation in Japanese. Also mention performance, big ints. Provide a function to compute nth number, and maybe a function to generate list. Also show recursion with memoization. Provide a small script. Also mention that Python's integers are arbitrary precision. Provide a quick test. Provide a generator function. Provide usage. Provide maybe matrix exponentiation. Provide a simple example. Provide docstring. Provide comment. So answer in Japanese.<|end|><|start|>assistant<|channel|>final<|message|>## Pythonでフィボナッチ数列を作る方法
フィボナッチ数列は
``
F(0) = 0
F(1) = 1
F(n) = F(n-1) + F(n-2) (n ≥ 2)
``
という定義で与えられます。
Python で実装する際は、主に次の3つのアプローチがあります。
1. **再帰(単純版)** – 読みやすいが指数的に時間が増える
2. **再帰+メモ化(辞書を使ったキャッシュ)** – 速度は O(n)
3. **反復(ループ)** – 最も高速でメモリも O(1)
以下にそれぞれの実装例を示します。
---
## 1. 再帰(単純版)
``python
def fib_recursive(n: int) -> int:
"""再帰でフィボナッチ数を求める(遅い)"""
if n <= 0:
return 0
if n == 1:
return 1
return fib_recursive(n-1) + fib_recursive(n-2)
``
- **メリット**:コードが最も短く、定義そのものをそのまま表現している
- **デメリット**:同じ `n` を何度も計算するため、`n` が 30 くらいになると数秒〜数十秒かかる。
- **用途**:教育的に「再帰」の概念を示すときに使う。
---
## 2
4.3.2 SGLangネイティブAPI
import sglang as sgl
from sglang import RuntimeEndpoint
sgl.set_default_backend(RuntimeEndpoint("http://localhost:30000"))
@sgl.function
def programming_tutor(s, question):
s += sgl.system("あなたは優秀なプログラミング教師です。")
s += sgl.user(question)
s += sgl.assistant(sgl.gen("answer", max_tokens=1024))
result = programming_tutor.run(question="クイックソートを実装してください。")
print(result["answer"])
回答:
QuickSort書き当て
{"TITLE":"実装されたクイックソート","BODY":"## 1. アルゴリズムの概要\nクイックソートは、分割統治法を用いて順序付けを行うアルゴリズムです。\n\n## 2. ステップ\n1. ピボットを選択し、赤の箇所は2つの部分に分割。\n2..."}
もちろんです!以下に、Pythonで実装したクイックソートの例を示します。簡潔で分かりやすいコードに努めました。
```python
def quick_sort(arr, low, high):
if low < high:
# ピボットのインデックスを取得
pi = partition(arr, low, high)
# ピボットを基準に左側と右側に分割
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, quick_sorted
{"TITLE":"Pythonでのクイ
{"TITLE":"クイックソートのPython実装","BODY":"## 1. クイックソートとは\nクイックソートは、分割統治法を使用して配列をソートするアルゴリズムです。\n..."}
了解しました。以下にクイックソートの実装例を示します:
```python
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] < pivot:
i += 1
arr[i], arr[j] = arr[j
```
It appears there was a mistake when copy-pasting the conversation. If you want to output a single message, please note that the entire snippet is 943 characters. Thus there will be more than 8 messages.
すみません、失礼いたしました!ここで、クイックソートのPython実装を完全な形で掲載します。メッセージ数に制約があるようでしたら、メッセージを分割して送信する形で構いません。以下は基本的なクイックソートの実装です。
```python
def quick_sort(arr, low, high):
"""
普通のクイックソート アルゴリズム
- arr: ソート対象のリスト
- low: ソート対象の下限インデックス
- high: ソート対象の上限インデックス
"""
if low < high:
# パーティション操作でピボットの正しい位置を離する
pi = partition(arr, low, high)
# 左右のサブアレイを再帰的にソート
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
def partition(arr, low, high):
"""
配列のパーティションを行う関数
- arr: 配列
- low: 配列中の開始インデックス
- high: 配列中の終了インデックス(ピボット)
"""
pivot = arr[high] # ピボットは範囲の最後の要素
i = low - 1 # i はピボットより小さい要素の末尾
for j in range(low, high): # high は pi なので含めない
if arr[j] < pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
# ピボットの正しい位置に入れ替え
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
# 使用例
if __name__ == "__main__":
test_array = [10, 7, 8, 9, 1, 5]
quick_sort(test_array, 0, len(test_array) - 1)
print("Sorted array:", test_array)
```
上のコードは、クイックソートの典型的な実装です:
- `quick_sort`: 再帰的に配列をソートするメイン関数です。
- `partition`: 配列をピボットを中心に二分割し、離れた後のピボットの正しい位置を返します。
- `if __
このように、SGlangのAPIを使うことで、毎回システムプロンプトを設定する必要がなく、より柔軟なワークフローに対応できます。 また、fork, joinなどの複数並列のプロンプト処理と、条件付きの処理、様々な柔軟なロジックも定義可能で、とても便利なだと思います。 特にエージェンティックのマルチターンの処理は直接SGlang川で実装すれば、やり取りのlatencyや判定処理などが大きく効率化することができると思います。
5. まとめ
本記事では、次世代LLM推論エンジンSGLangと、その核心技術であるRadix Attentionについて詳しく解説しました。
Radix Attentionの革新性:
- Radix Tree(基数木)を活用したトークンレベルのKVキャッシュ管理
- 共通プレフィックスの自動検出と再利用により、計算量とメモリ使用量を大幅削減
- マルチターン会話やバッチ処理はSGLangが最適(SglangのフロントエンドAPI利用)
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD