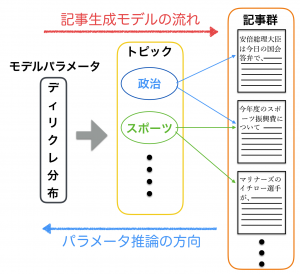
2026.02.16
PaperBanana: 学術イラスト自動生成AIエージェントを使ってみた
TL;DR
- PaperBananaは、論文などで利用するダイヤグラムや統計グラフなどの学術イラストを自動生成するAIエージェントツールで、Peking UniversityとGoogle Cloud AI Researchの研究者らによって発表されました。Retriever Agent、Planner Agent、Stylist Agent、Visualizer Agent、Critic Agentの複数のエージェントが協力してイラストを生成します。画像生成だけでなく、コード生成による統計グラフの生成も可能です。PaperBananaのコードはまだ公開されていませんが、論文を参考にしたオープンソースの実装がすでに公開されており、試してみました。
はじめに
こんにちは、グループ研究開発本部のAI研究開発室のT.I.です。昨年末にインフォグラフィックのような複雑で文字を含む画像を高精度に生成できるNano Banana Proが登場して以来、誰でも手軽にインフォグラフィックを作成できるようになりました。その利便性ゆえか、最近ではテキスト数行で済むような内容まで、猫も杓子もインフォグラフィック化して応酬し合うという事態となっており、少々食傷気味な今日この頃です。
さて、先日、Peking UniversityとGoogle Cloud AI Researchの研究者らによって、「PaperBanana: Automating Academic Illustration for AI Scientists」という論文が発表されました(PaperBanana: Automating Academic Illustration for AI Scientists)。これは、研究者が論文やプレゼンテーションで使用する「学術イラスト」を自動生成するためのAIエージェントツールです。何故に「PaperBanana」なのかと思うかもしれませんが、学術的な文脈では「Paper」は論文を指すので、それに件の「Nano Banana」を掛け合わせたのでしょう。
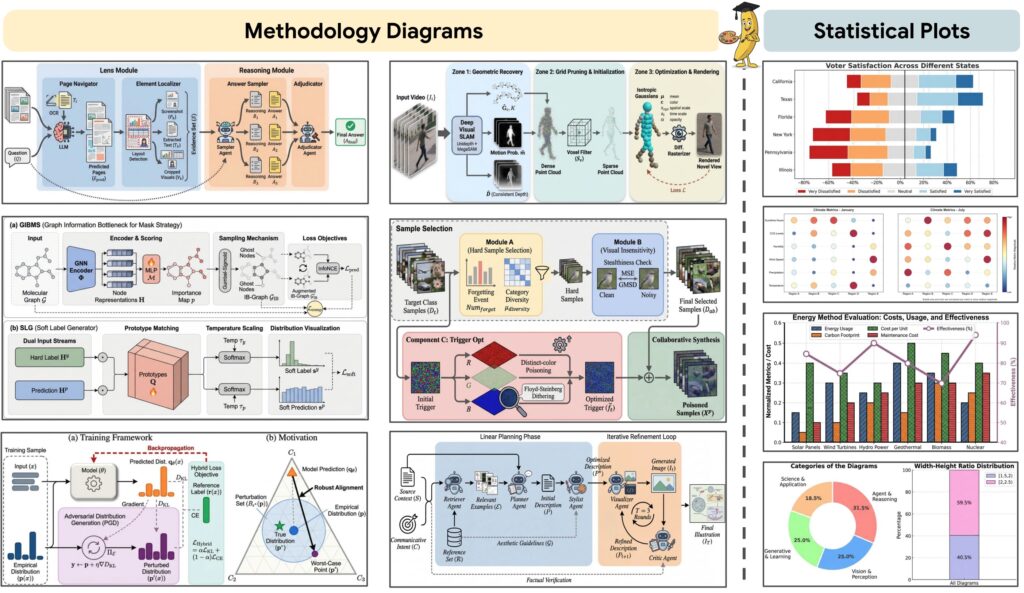
PaperBananaは、イラストを生成するために、役割の異なる複数のエージェントが協調して動作します。まず「Planning Phase」では、Retriever Agentが参考資料を収集し、Planner Agentが詳細な描写案を作成。さらにStylist Agentがガイドラインに基づきブラッシュアップし、イラストの構成を計画します。続く生成・評価プロセスでは、Visualizer Agentが画像を生成し、それをCritic Agentが評価・フィードバックするというループを繰り返すことで、最終的なイラストの完成度を高めていきます。なお、正確な数値表現が求められる統計グラフに関しては、画像生成AIのみでは限界があるため、Pythonコードを生成・実行するアプローチも併用されています(数値の正確さを画像生成AIで保証するのは無理です)。
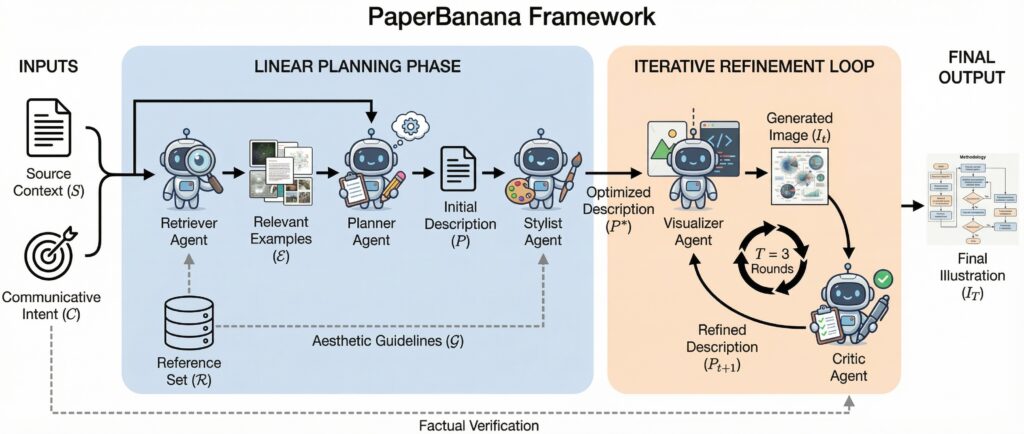
PaperBanana(の非公式オープンソース版)を使ってみる
では、早速「PaperBanana」を使ってみます。PaperBananaで検索すると https://paperbanana.org/ というサイトが出てきます。
Webサービスとして既に公開されているのかと思いましたが、実はこのサイト、PaperBananaの公式ではありません。画面を最下部までスクロールすると、「UNOFFICIAL SERVICE DISCLAIMER」という良心的な注意書きが表示されます。MonthlyのStarterプランが$14.90からという具体的な料金設定まで提示されていますが、少々怪しいので利用は控えた方が良さそうです(同様に、https://paperabnana.studioとか https://paper-banana.org とかもあるのですが、これらも非公式なものかと)。

まあ、公式のGitHubリポジトリも公開されているので、そちらを利用しましょう(GitHub PaperBanana)。
しかし、近日中に公開予定とありますが、2026年2月16日時点ではまだ公開されていません。困りました。実は、PaperBananaの論文を参考にしたオープンソースの実装がなんとすでに公開されています(GitHub llmsresearch/paperbanana)。これを利用してみます。
$ git clone https://github.com/llmsresearch/paperbanana.git $ cd paperbanana $ pip install -e ".[dev,google]"
あとは、.envで、GOOGLE_API_KEYを設定すれば実行できます。以下のようにダイアグラムの内容のテキストをmethod.txtとファイルに保存しておきます。
本モデルは、Transformerアーキテクチャをベースに、いくつかの重要な変更を加えて構築されている。入力トークンはまず学習済み埋め込み層を通じて埋め込まれ、正弦波位置エンコーディングと結合される。結合された表現は、N=13のエンコーダ層のスタックに渡される。各エンコーダ層は、マルチヘッド自己注意機構(8ヘッド)と、GELU活性化関数を用いた位置ごとのフィードフォワードネットワークで構成される。各サブレイヤの前にレイヤ正規化(Pre-LN)が適用され、各サブレイヤは残差接続で囲まれている。 デコーダも同様の構造を持つが、自己注意機構とフィードフォワードサブレイヤの間に、追加のクロスアテンション層が含まれる。クロスアテンションはエンコーダの出力表現に対して注意を行う。デコーダの自己注意機構では、因果マスキングにより未来の位置への注意が防止される。 エンコーダには新たなスパースアテンションパターンを導入し、学習済みルーティング機構によって選択された位置のサブセットにのみ注意を行うことで、二次の計算量をO(n√n)に削減する。ルーターは全位置に対するアテンションスコアを予測し、各クエリに対してトップkの位置を選択する。 デコーダの最終出力は、線形層を通じて射影された後、ソフトマックスにより出力トークンの確率分布が生成される。
では、実行してみます。
$ paperbanana generate --input method.txt \ --caption "スパースルーティングを備えたエンコーダ・デコーダアーキテクチャの概要"
複数のエージェントが起動して思考を巡らせながら動くため少々時間はかかりますが(数分)、上記のように無事に生成されました。PaperBananaは、Nano Banana Proを利用してイラストを生成、それをGemini 2 Flashで画像を評価するというループを繰り返して生成画像の品質を高めていきます。最初の生成画像ではデータのフローの向きなど奇妙なものがありますが、3回目の最終版では一部不自然な矢印が残るものの改善されていることがわかります。
データファイルを与えて、可視化のpythonコードを生成してのグラフの生成も可能ですので、試してみます。
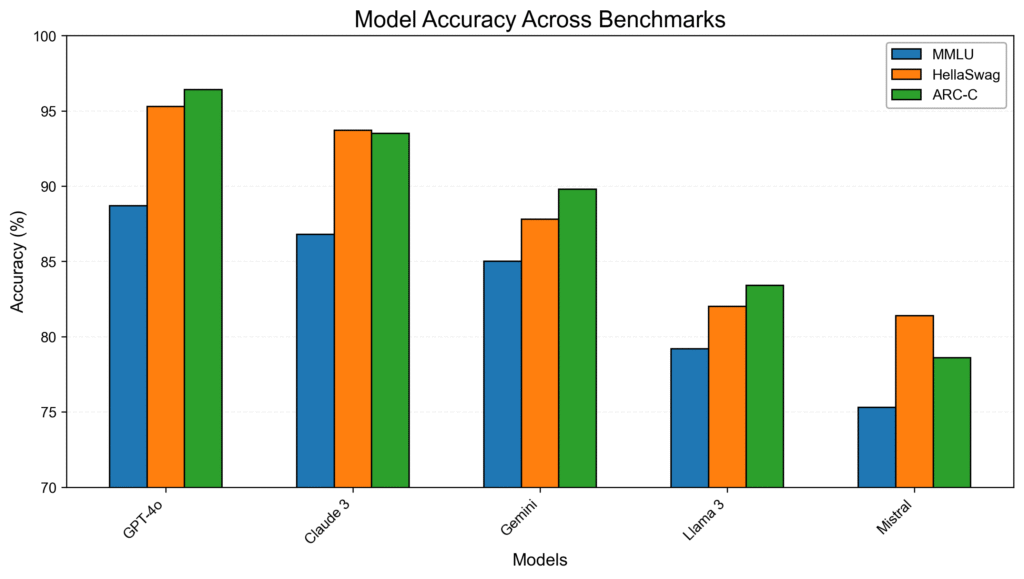
models,MMLU,HellaSwag,ARC-C GPT-4o,88.7,95.3,96.4 Claude 3,86.8,93.7,93.5 Gemini,85.0,87.8,89.8 Llama 3,79.2,82.0,83.4 Mistral,75.3,81.4,78.6
では実行してみます。
$ paperbanana plot --data results.csv --intent "ベンチマーク間でのモデル精度を比較する棒グラフ"
しかし、こちらは生成コードの品質があまり良くないのか画像生成に失敗するケースが多く(VLMをGemini 3 Proに変えたりもしたのですが)、なかなか成功しませんでした。何度か試してようやく生成できましたが、結果はこのような感じで、少々微妙です。
デフォルトでは途中で生成されているPythonコードは出力されませんが、paperbanana/agents/visualizer.pyを一部を修正して、生成されたコードを出力するようにしてみました。確認すると、生成されたコードは以下のようになっていました。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
OUTPUT_PATH = "model_accuracy_plot.png"
# Data from the JSON
data = [
{"models": "GPT-4o", "MMLU": 88.7, "HellaSwag": 95.3, "ARC-C": 96.4},
{"models": "Claude 3", "MMLU": 86.8, "HellaSwag": 93.7, "ARC-C": 93.5},
{"models": "Gemini", "MMLU": 85.0, "HellaSwag": 87.8, "ARC-C": 89.8},
{"models": "Llama 3", "MMLU": 79.2, "HellaSwag": 82.0, "ARC-C": 83.4},
{"models": "Mistral", "MMLU": 75.3, "HellaSwag": 81.4, "ARC-C": 78.6},
]
df = pd.DataFrame(data)
# Calculate average performance for sorting
df['Average'] = df[['MMLU', 'HellaSwag', 'ARC-C']].mean(axis=1)
# Sort by average performance in descending order
df = df.sort_values(by='Average', ascending=False)
models = df['models'].tolist()
mmlu = df['MMLU'].tolist()
hellaswag = df['HellaSwag'].tolist()
arc_c = df['ARC-C'].tolist()
# Plotting parameters
bar_width = 0.2
index = np.arange(len(models))
colors = ['#1f77b4', '#ff7f0e', '#2ca02c'] # MMLU, HellaSwag, ARC-C
font = 'Arial'
# Create the plot
fig, ax = plt.subplots(figsize=(10, 6))
fig.patch.set_facecolor('white')
# Plot the bars
bar1 = ax.bar(index - bar_width, mmlu, bar_width, label='MMLU', color=colors[0], edgecolor='black')
bar2 = ax.bar(index, hellaswag, bar_width, label='HellaSwag', color=colors[1], edgecolor='black')
bar3 = ax.bar(index + bar_width, arc_c, bar_width, label='ARC-C', color=colors[2], edgecolor='black')
# Customize the plot
ax.set_xlabel('Models', fontsize=12, fontname=font, color='black')
ax.set_ylabel('Accuracy (%)', fontsize=12, fontname=font, color='black')
ax.set_title('Model Accuracy Across Benchmarks', fontsize=16, fontname=font, color='black', loc='center')
ax.set_xticks(index)
ax.set_xticklabels(models, fontsize=10, fontname=font, rotation=45, ha="right", color='black')
ax.set_yticks(np.arange(70, 101, 5))
ax.set_yticklabels(np.arange(70, 101, 5), fontsize=10, fontname=font, color='black')
ax.set_ylim(70, 100)
# Add grid
ax.grid(axis='y', linestyle='--', alpha=0.7, color='#EEEEEE', zorder=0)
ax.set_axisbelow(True)
# Add legend
legend = ax.legend(loc='upper right', fontsize=10, frameon=True, facecolor='white', edgecolor='#AAAAAA', framealpha=1)
for text in legend.get_texts():
text.set_fontname(font)
text.set_color('black')
# Add border
for spine in ax.spines.values():
spine.set_edgecolor('black')
# Adjust margins
plt.tight_layout(rect=[0, 0, 1, 0.95]) # Adjust top margin for title
# Save the plot
plt.savefig(OUTPUT_PATH, dpi=300, bbox_inches='tight')
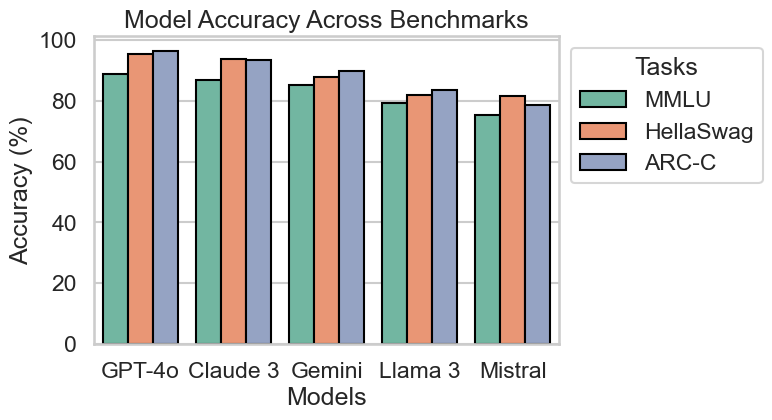
処理に冗長な部分が多く、品質に関する調整も洗練されてないですね。これでは、生成されたコードをそのまま利用するのは難しそうです。自分がやるなら、Seabornを利用して、簡潔に以下のように処理します。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set(style="whitegrid", context='talk')
df = pd.read_csv("results.csv")
_df = df.melt(id_vars="models", var_name="tasks", value_name="scores")
fig, ax = plt.subplots(figsize=(6, 4))
sns.barplot(x="models", y="scores", hue="tasks", data=_df, ax=ax, ec="black", palette="Set2")
ax.set(title="Model Accuracy Across Benchmarks", xlabel='Models', ylabel='Accuracy (%)')
ax.legend(title="Tasks", loc="upper left", bbox_to_anchor=(1, 1))
fig.savefig('model_accuracy_plot_human.png', bbox_inches='tight')
他にも、palmer penguins dataset での可視化も試みましたが、プラン生成までは良いのですが、その先の可視化コードまでの生成には至りませんでした。
$ paperbanana plot --data penguins.csv --intent "くちばしの長さと深さの関係を、種ごとに色分けしてプロット"
生成された実行計画の概要は以下のようになっていました。
**Plot Description:** The plot is a scatter plot displaying the relationship between bill length (in mm) on the x-axis and bill depth (in mm) on the y-axis for different penguin species. Each point represents a single penguin, with its color and shape indicating its species. **Data Mapping:** * **X-axis:** `bill_length_mm` (Numerical) * **Y-axis:** `bill_depth_mm` (Numerical) * **Color (Hue):** `species` (Categorical: Adelie, Chinstrap, Gentoo) * **Shape (Marker):** `species` (Categorical: Adelie, Chinstrap, Gentoo) - Circles for Adelie, Squares for Chinstrap, Diamonds for Gentoo. **Detailed Data Points (Illustrative Subset - include all 344 in actual implementation):** Here's how the first few data points from the sample data would be plotted. It's critical to include *all* 344 data points in the actual plot. Any rows with NaN values in `bill_length_mm` or `bill_depth_mm` should be excluded from the scatter plot. * Adelie, Torgersen, 39.1, 18.7, 181.0, 3750.0, Male: (x=39.1, y=18.7, color=#4c72b0, shape=circle - assigned to Adelie) * Adelie, Torgersen, 39.5, 17.4, 186.0, 3800.0, Female: (x=39.5, y=17.4, color=#4c72b0, shape=circle - assigned to Adelie) * Adelie, Torgersen, 40.3, 18.0, 195.0, 3250.0, Female: (x=40.3, y=18.0, color=#4c72b0, shape=circle - assigned to Adelie) * Adelie, Torgersen, 36.7, 19.3, 193.0, 3450.0, Female: (x=36.7, y=19.3, color=#4c72b0, shape=circle - assigned to Adelie) * Chinstrap, Dream, 46.5, 17.9, 192.0, 3500.0, Female: (x=46.5, y=17.9, color=#dd8452, shape=square - assigned to Chinstrap) * Gentoo, Biscoe, 49.1, 14.8, 220.0, 5150.0, Female: (x=49.1, y=14.8, color=#55a868, shape=diamond - assigned to Gentoo) And so on, for all 344 rows, excluding rows with NA values in bill length or bill depth. **Aesthetic Parameters:** * **Colors:** * Adelie: `#4c72b0` (a shade of blue) * Chinstrap: `#dd8452` (a shade of orange) * Gentoo: `#55a868` (a shade of green) * **Marker Style:** * Adelie: Circle (`o`) * Chinstrap: Square (`s`) * Gentoo: Diamond (`D`) * **Marker Size:** 5 * **X-axis Label:** "Bill Length (mm)" * Font Size: 12 * Font Family: Sans-Serif * **Y-axis Label:** "Bill Depth (mm)" * Font Size: 12 * Font Family: Sans-Serif * **Title:** "Bill Dimensions by Species" * Font Size: 14 * Font Family: Sans-Serif * **Grid:** Light gray dashed grid lines (`#e0e0e0`) behind the data points. * Line width: 0.5 * Line style: `--` * **Legend:** * Title: "Species" * Location: "upper right" of the plot * Font Size: 10 * Font Family: Sans-Serif * **Background Color:** White (`#ffffff`) * **Border:** Thin black border around the plot area (all four spines visible). * **Axis Limits:** Determine appropriate axis limits based on the minimum and maximum values of `bill_length_mm` and `bill_depth_mm` to ensure all data points are visible with some padding. For example, if bill length ranges from 30 to 60 and bill depth ranges from 13 to 22, set the x-axis limits to [28, 62] and the y-axis limits to [12, 23]. * **Data Point Transparency:** Alpha value of 0.7 to avoid overplotting in dense regions. **Plot Generation Steps:** 1. **Data Cleaning:** Remove any rows where `bill_length_mm` or `bill_depth_mm` is NaN. 2. **Color and Shape Mapping:** Assign a unique color and shape to each species (Adelie, Chinstrap, Gentoo). 3. **Scatter Plot Creation:** Create a scatter plot with `bill_length_mm` on the x-axis and `bill_depth_mm` on the y-axis. 4. **Coloring and Shaping:** Color and shape each data point according to its species. 5. **Aesthetics:** Apply the aesthetic parameters described above (marker style, size, colors, labels, title, grid, legend, background, border, axis limits, transparency, font family). 6. **Output:** Save the plot as a high-resolution image (e.g., PNG or SVG).
このプランをプロット対象のデータと併せてVisualizer Agentに渡し、Pythonコードを生成させるというフローになります。しかし、実装を確認すると、以下のようにJSONデータをそのままプロンプトに注入する構成となっているため、データ量が増大するとコンテキスト制限に抵触したり、精度が低下したりする可能性が高いと考えられます。PaperBananaのオリジナル論文のAppendixでは、各エージェントのプロンプトが掲載されていますが、そちらでも同様にデータもプロンプトの一部として扱う実装のようです。大量のデータを統計的に処理しての可視化ではなく、集計後の数値を渡しての棒グラフなどの利用が限界のようです。
## Raw Data
```json
{
"data": [
{
"species": "Adelie",
"island": "Torgersen",
"bill_length_mm": 39.1,
"bill_depth_mm": 18.7,
"flipper_length_mm": 181.0,
"body_mass_g": 3750.0,
"sex": "Male"
},
{
"species": "Adelie",
"island": "Torgersen",
"bill_length_mm": 39.5,
"bill_depth_mm": 17.4,
"flipper_length_mm": 186.0,
"body_mass_g": 3800.0,
"sex": "Female"
},
{
"species": "Adelie",
"island": "Torgersen",
"bill_length_mm": 40.3,
"bill_depth_mm": 18.0,
"flipper_length_mm": 195.0,
"body_mass_g": 3250.0,
"sex": "Female"
},
(略)
}
```
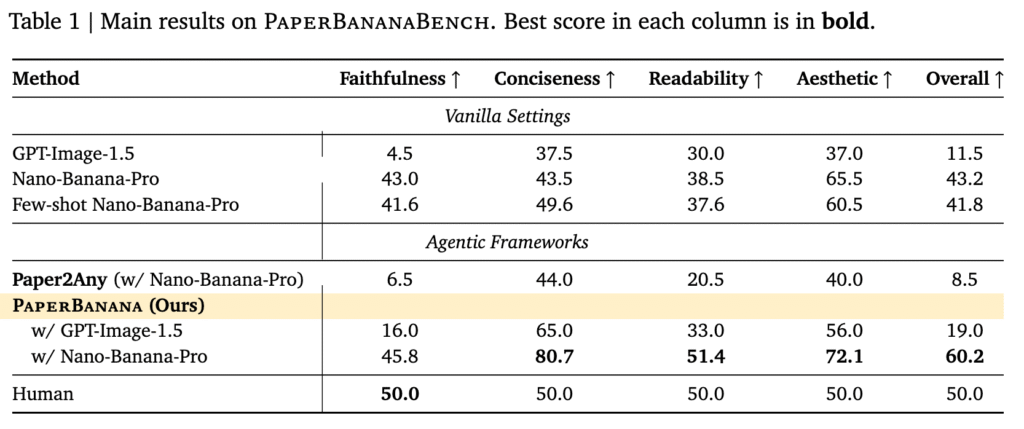
PaperBananaの性能
さて、非公式(?)のオープンソース版のPaperBananaを試してみましたが、オリジナルのパフォーマンスについても軽く紹介しておきます。PaperBananaでは、NeurIPS 2025の論文にある図表からPaperBananaBenchというベンチマークデータセットを作成し、他の画像生成モデルなどと比較しました。以下のように、PaperBananaのフレームワークでNano-Banana-Proを画像生成エンジンに利用した場合、各種スコアでオリジナルのNano-Banana-Proよりも各種指標が改善されています。
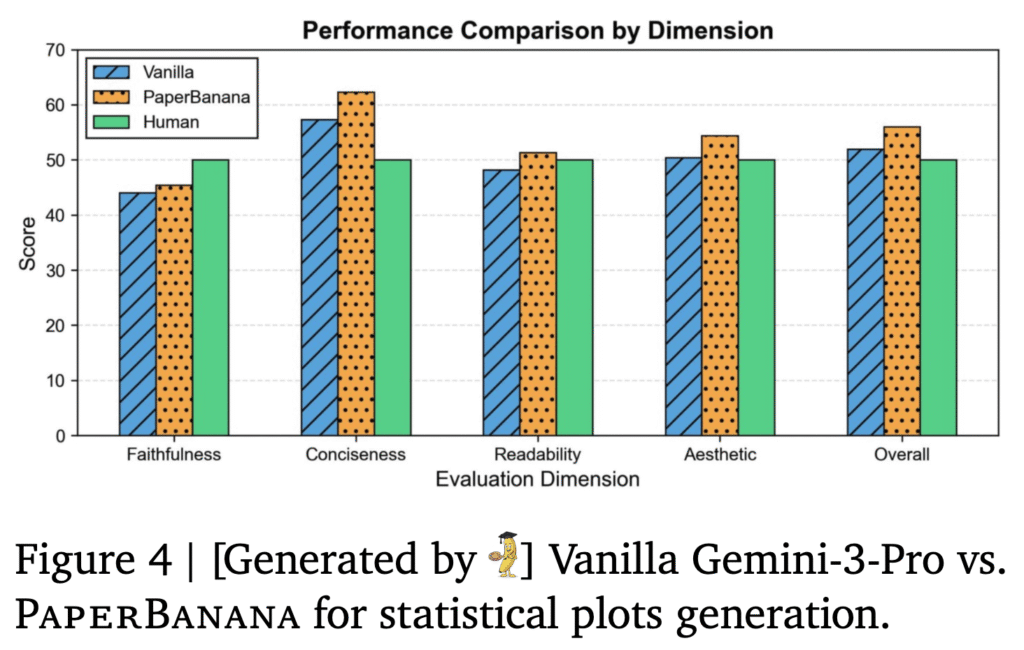
PaperBananaの論文の議論では、生成画像の品質向上には、Critic Agentによる評価とフィードバックが重要であるとされています。結果的に統計グラフのような場合であっても、以下のようにGemini 3 Proでのコード生成の結果よりも、改善が見られます。 一部の指標のパフォーマンスにおいてはヒトを上回っております。
また、グラフの生成に関して、直接Nano Banana ProのようなText-to-Imageを使った場合とコードを生成した場合のパフォーマンスの比較実験もされています。結果は以下の通りでFaithfulness(忠実度)以外に関してはどちらのケースもヒトを超える勝率となっております。これに関しては、学術論文などの統計グラフは見栄えなどはあまり考慮されないことも多いので仕方がない気もします。
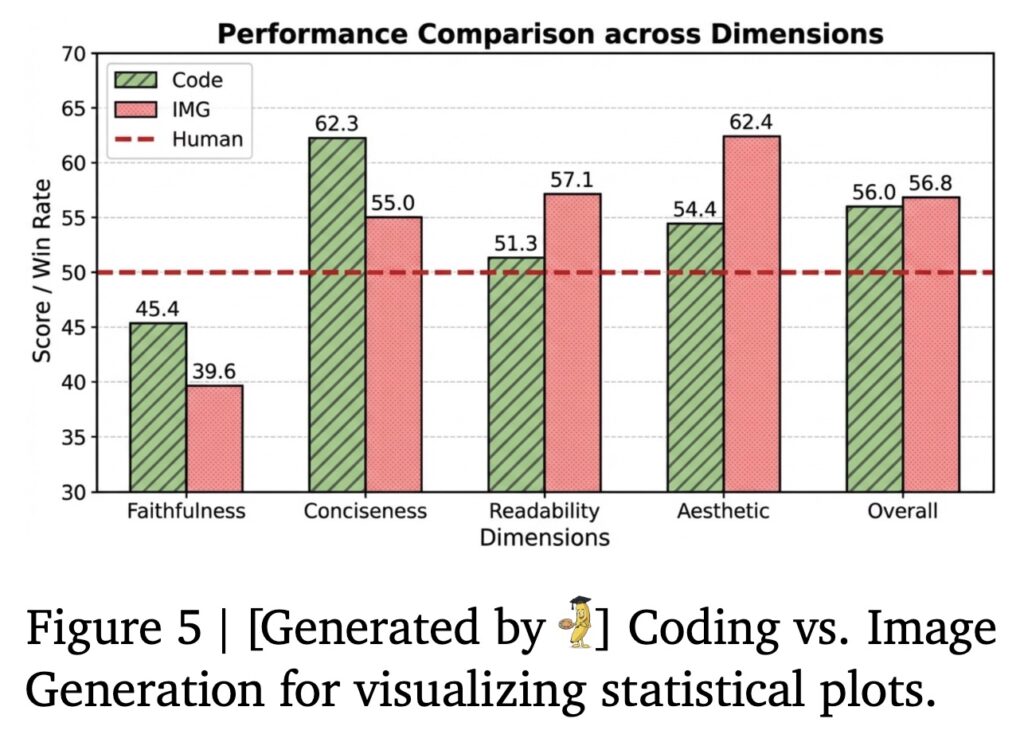
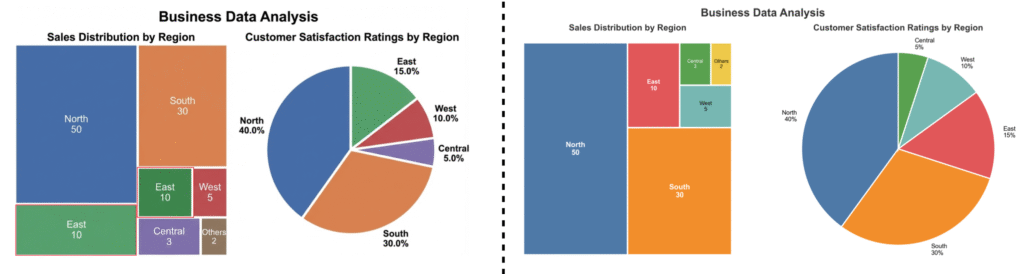
画像生成によるグラフの生成では、可読性(Readability)や美しさ(Aesthetics)のスコアが高い一方で、忠実度(Faithfulness)、簡潔性(Conciseness)のスコアは低くなっています。論文のAppendixでも具体的な生成例が示されていますが、生成されたグラフは、データの傾向を視覚的に捉えることはできるものの、当たり前ではありますが数値的な正確性や情報の過不足が見られるケースもあります。いくら画像生成AIの精度が向上したとしても、正確性・再現性が不可欠である統計グラフの作成では、コード生成による作成が必要であることは変わることはないでしょう。
また、ダイアグラムの生成に関しても、PaperBananaが完璧に生成できるわけではなく、以下のように矢印の向きが不自然なものがあったり、データフローの向きがおかしいものがあったりします。この点に関しては、まだVLMなどの認識精度などの技術的な限界があるため利用に際しては注意が必要でしょう。
まとめ
今回のブログでは、学術イラストを自動生成するAIエージェントツール「PaperBanana」と、その非公式オープンソース版を試してみました。複数のエージェントが協調し、生成されたダイアグラムを自己評価・修正するプロセスを導入することで、より正確かつ高品質なイラストを実現するというアプローチが特徴的です。コード生成による統計グラフの生成も可能ですが、(実験したオープンソース実装版では)成功率や性能には限界があり、実用的なレベルにはまだ不足していると感じました。論文でもPaperBananaの課題として論じられていますが、画像がベクター形式ではなく編集不可能である点も、そのままでは学術用のイラストとしては利用しずらいですね。必要に応じて、別のツールを利用した修正が必要です。
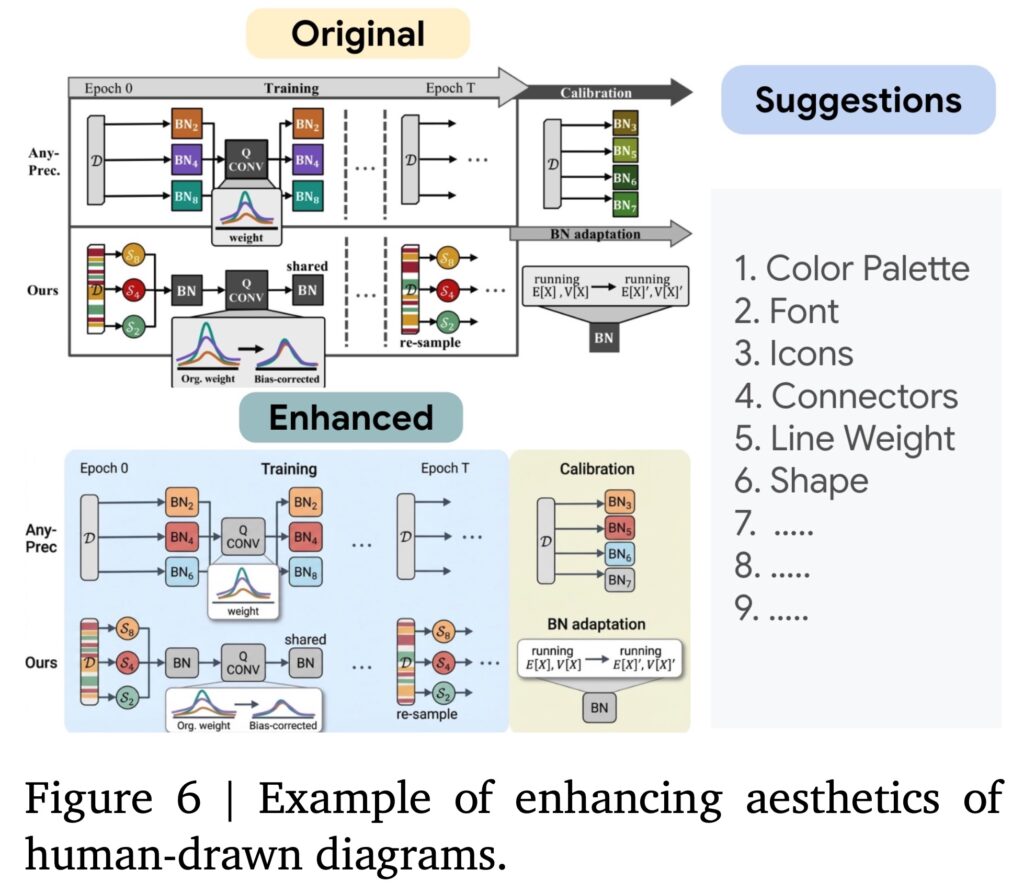
しかし、学術イラストのような専門的で正確性が必要とされるものの生成においては、AIエージェントの自動化には限度があるかと思います。その点について、PaperBananaの論文では、ヒトが作成したダイアグラムをベースにPaperBananaのフレームワークを利用して、改善させるという利用方法についても検証しております。実際に292のテストに関して、改善版のダイアグラムは56.2%のケースでヒトが作成したダイアグラムよりも優れていると評価されました。うまく利用すれば、学術イラストの品質向上のためのツールとして活用できる可能性はあると思います。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD