2026.04.01
AIが自動で実験を反復する「autoresearch」の仕組み
TL;DR

図1:概要(NotebookLMで生成)
- autoresearch は、AI が学習コードを自分で修正しながら実験を繰り返す OSS です。
- ポイントはコード生成そのものではなく、実験して評価し、良かった変更だけを残す改善ループの自動化にあります。
- データ準備や評価のルールは固定し、AI は改善対象のコードだけを触る設計になっています。
- 短時間の実験、シンプルな評価指標、自動的な採用/却下の判断、この 3 つが揃うことで大量の自動試行錯誤が可能になっています。
はじめに
こんにちは、グループ研究開発本部・AI研究開発室のB.D.です。
2026年3月、Andrej Karpathy 氏が公開した autoresearch は、AI エージェントに小さな学習環境を与え、自分でコードを修正しながら実験を回させる OSS です。
一見すると「AI がコードを書いてくれるツール」に見えますが、仕組みを見ていくと、改善案を作る、実験する、評価する、良かった変更だけを残す、という反復ループまで含めて設計されていることが分かります。単発の支援というより、研究開発プロセスそのものの自動化を狙った構成です。
この記事では、autoresearch の仕組みを整理したうえで、何が新しく、どこが実務上のポイントになるのかを見ていきます。
autoresearch とは何か
autoresearch は、単一 GPU 上で動く小さな学習環境を使い、AI が自律的に改善ループを回すための実験プロジェクトです。AI は次のような流れで動きます。
program.mdを読み、何を守るべきか理解するtrain.pyを少し変更する- 5 分だけ学習を実行する
val_bpbを見て、改善したかどうかを判断する- 改善していれば採用し、悪化していれば破棄する
- 次の改善案を試す
ここで登場する val_bpb は、未知のデータをどれだけ無駄なく予測できたかを測る指標で、低いほど良い結果を意味します。実務的にはモデル品質を比較するための共通スコアと考えれば十分です。
※ bpb は bits per byte の略で、クロスエントロピー損失を log 2 で変換し、トークンの UTF-8 バイト数で正規化した値です。トークナイザーの語彙サイズに依存しないため、異なる設定間の比較に適しています。
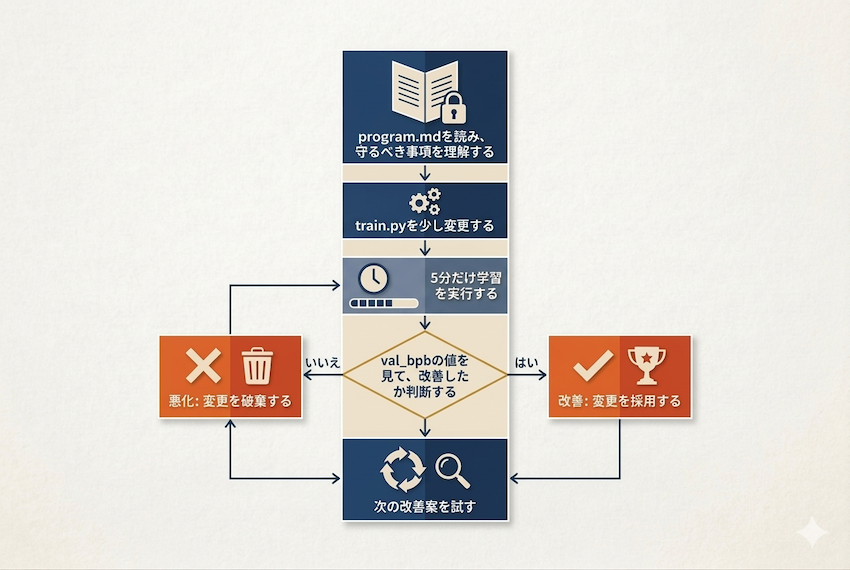
図2:autoresearch の改善ループ(Geminiで生成)
三層構造
リポジトリの中心は 3 つのファイルで構成されています。
prepare.py:データ準備・トークナイザー作成・評価処理を担う固定部分。いわば実験の採点基盤です。train.py:AI が実際に書き換える対象。モデル構造や学習条件が入っています。program.md:AI エージェントへの運用指示書。人間が主に調整するのはここです。
採点基盤は固定し、改善候補だけを AI に任せ、運用ポリシーは人間が設計する。この三層の役割分担がはっきりしているからこそ、小さなリポジトリでも自律的な研究ループとして成立しています。
設計の 3 つのポイント
1. 5 分固定が比較可能性を生む
このプロジェクトでは、どんな変更を入れても学習時間は 5 分固定です。通常の研究では、モデルサイズや設定次第で実験時間がばらつくため、単純比較が難しくなります。autoresearch では「同じ持ち時間でどの変更が最も良い結果を出したか」を比較しやすくするために、この固定時間の設計を採っています。
1 時間で約 12 回、一晩で約 100 回の試行が可能で、短い試行錯誤を大量に回すことが前提です。この割り切りが、val_bpb のように低い計算コストで評価できる指標との組み合わせで効いていると感じました。5 分で回して短時間で採点できるから、反復が現実的な速度で成立しています。
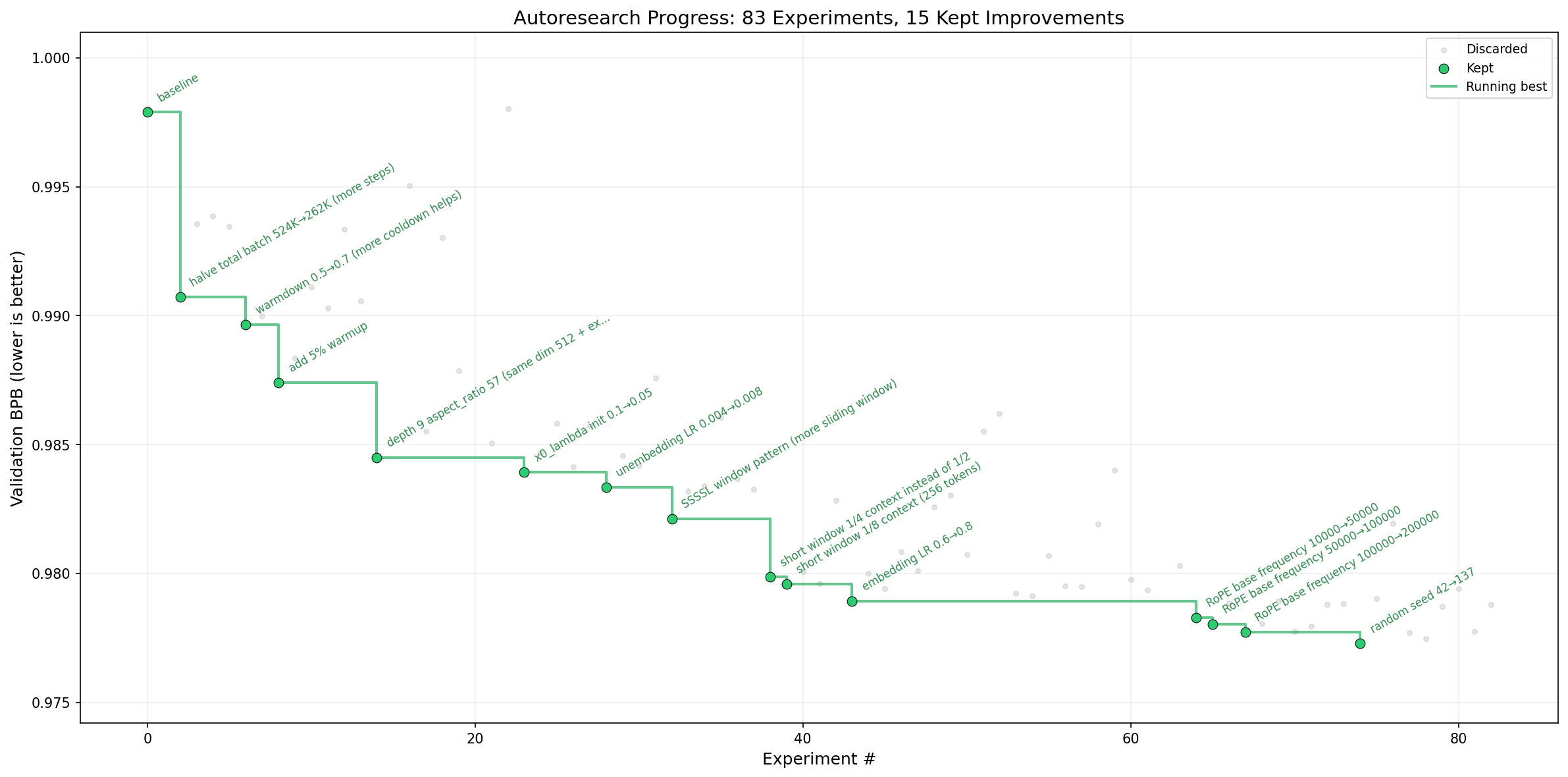
図3:実験の累積改善(出典:karpathy/autoresearch)
2. AI に触らせる範囲を絞っている
program.md では、AI が編集できるファイルを train.py に限定しています。データ準備や評価ロジックを持つ prepare.py は固定されており、AI はそこを変更できません。評価関数 evaluate_bpb を含む評価ハーネスの変更も禁止されています。
なぜこの制約が必要なのか。評価ロジックを AI が触れる状態にしておくと、モデルを改善する代わりに採点基準の方を書き換えて、改善したように見せかけてしまう傾向があります。つまり「ズル」です。改善対象と採点基準を分離することで、そうした動きを構造的に防いでいるわけです。個人的には、この制約の置き方が autoresearch の設計で最も巧いところだと思いました。
3. 人間の役割が変わる
autoresearch では、人間は Python を直接触るのではなく、program.md を通じて AI の行動方針を設計する側に回ります。何を任せ、何を禁止し、どの指標で評価するかを定義することが、このプロジェクトにおける人間の主な仕事です。
program.md の中身を読んで印象的だったのは、いわゆるプロンプトの小技やチューニングのテクニックが一切使われていないことです。やるべきことを具体的に、細かく書いているだけ。今の LLM は十分に強いので、従来のプロンプトエンジニアリングの技法よりも、前提条件と採用基準をどこまで明文化できるかの方が重要になっていると感じます。この点が、autoresearch を単なるコーディング支援と区別するポイントだと思いました。
実務から見た展望
想定ユースケースの面白さと限界
program.md には、ユーザーが寝ている間に AI が実験を回し、朝に大量の結果が揃っている状態、という想定ユースケースが明示されています。研究者が寝ている間に 100 回の試行錯誤が走るという絵は分かりやすく、特に少人数チームにとっては夜間や待ち時間を実験に充てられる可能性を示しています。
一方で、この仕組みが安定して回っている理由の一部は、実験空間をかなり狭く保っていることにもあります。単一 GPU・5 分固定・val_bpb 中心という明確な前提条件があるからこそ成り立っている面があり、そのまま多くの現場に一般化できるかはまだ分かりません。この仕組みがどこまで実際に活きるのか、個人的には興味を持って見ています。
他タスクへの展開で難しいのは評価設計
別環境や別タスクへ広げようとした場合、そのまま横展開するというよりは条件を再設計しながら使う前提になります。データセット、語彙数、系列長、モデル深さなど調整すべきパラメータは多く、他タスクへの応用事例もまだ出てきていないのが現状です。
その中で最も難しいのは、モデルの書き換えそのものよりも、何を固定し、何を成功とみなし、どう評価ロジックを守るかという設計の部分だと考えています。autoresearch 自体がそうであるように、固定できるものはなるべく固定し、シンプルにできるものをシンプルにするというアプローチが、他タスクでも有効なのではないでしょうか。
学術的な拡張:AutoResearch-RL
autoresearch の設計思想を強化学習の枠組みで理論化・拡張した論文も登場しています。Jain らの「AutoResearch-RL」(arXiv: 2603.07300, 2026)は、autoresearch のループを MDP(マルコフ決定過程)として定式化し、PPO で方策を学習させるフレームワークです。論文自身が「This paper formalises, extends, and analyses that prototype through the lens of reinforcement learning」と述べており、autoresearch の直接的な拡張に位置づけられます。
主な拡張は 3 点です。
第一に、実験履歴を蓄積して次の提案に活かすメタ方策の導入です。autoresearch の LLM エージェントは、毎回プロンプト内のコンテキストから方策を再構築します。過去の実験結果はプロンプトに含まれるものの、エージェント自体は学習しません。AutoResearch-RL は過去 32 回分の実験結果をスライディングウィンドウで保持し、PPO で方策そのものを更新していきます。これにより、「どのクラスの変更が効きやすく、どのクラスが有害か」という研究上のヒューリスティクスをエージェントが内在化できるようになります。
第二に、途中で見込みのない実験を打ち切る self-evaluation モジュールです。autoresearch では、すべての実験が 5 分間フルに走ります。良い変更も悪い変更も同じ時間を消費するため、悪い実験に費やす GPU 時間が無駄になります。AutoResearch-RL では、30 秒ごとに損失曲線をべき乗則モデルでフィッティングし、最終スコアを予測します。改善が見込めないと判断した場合は早期に中断することで、GPU 時間あたりのスループットを 2.4 倍に改善しています。
第三に、収束保証の理論的証明です。「採用した最良スコアは実験を重ねるほど単調に改善し、到達可能な最小 bpb に確率 1 で収束する」ことを、確率論(優マルチンゲール)を用いて証明しています。工学的なプロトタイプであった autoresearch に、数学的な裏付けを与えた形です。
同じベンチマーク(H100 単一 GPU、FineWeb、300 秒固定、val-bpb)で実験した結果、約 100 回の試行(約 8 GPU 時間)で val-bpb 2.681 を達成し、人間のエキスパートによる手動チューニング(2.847)を上回ったと報告されています。
なお、この論文は共著者に AI を記載したことが arXiv のポリシーに抵触し、現在は取り下げ済みです。ただし ResearchGate では引き続き閲覧可能です。内容自体は autoresearch の改善ループをどこまで拡張できるかを示す参考事例として興味深いものです。
コミュニティによる分散化の動き
学術面の拡張とは別に、autoresearch プロジェクト自体もグローバルな開発者コミュニティに引き継がれ、複数のエージェントが成果を共有しながら分担・協調する分散協調層が構築されています。単一 GPU・単一エージェントだった原型が、学術と実践の両面から拡張され始めている状況です。
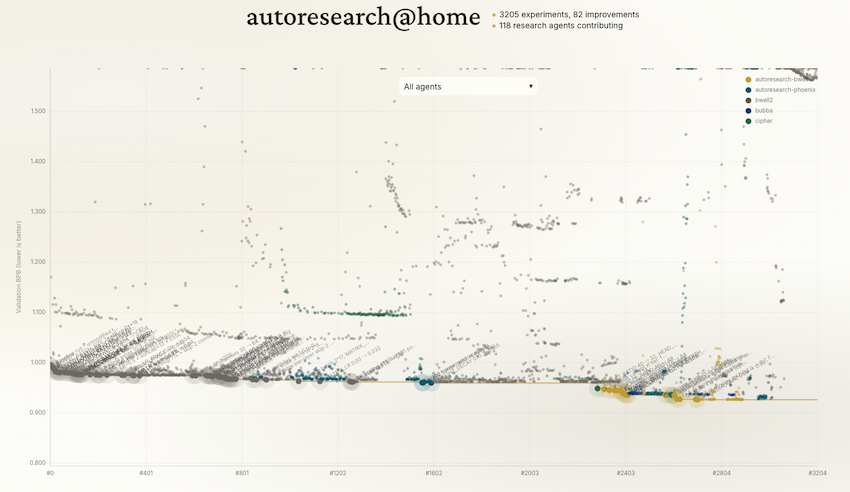
図4:autoresearch@home のダッシュボード(出典:ensue-network.ai、2026-03-30 スクリーンショット)
まとめ
本記事では、Karpathy 氏の autoresearch を題材に、AI が自分で実験を回す仕組みと、その設計思想を整理しました。
- 価値の中心はコード生成ではなく、実験と評価を含む改善ループの自動化にある
- 採点基盤(
prepare.py)・改善対象(train.py)・運用指示(program.md)の三層構造が、小さなリポジトリで自律研究を成立させている - 5 分固定という割り切りが、短い反復を大量に回す運用を支えている
- 他タスクへ広げる際の難所は、モデルよりも評価軸と制約条件の設計にある
現時点では単一 GPU 前提の実験的な仕組みですが、AI が自律的に改善ループを回した初期の実装例として注目に値します。今後は「どれだけ賢いモデルか」だけでなく、「AI にどう改善ループを任せ、どう評価し、どこまで任せるか」を設計できることが、研究開発の現場で重要になっていくのではないかと思います。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- karpathy/autoresearch – GitHub
- AI两天推翻20年工作习惯,Karpathy百行代码开源项目”封神”,AI替你通宵肝研究、战绩可查 – 36Kr
- AIが自分で深層学習の研究をする – makokon
- まだコードを書いてる?AIがAIを育てる時代の「人間の役割」 – tyo
- Karpathyのautoresearch — 単一GPUで一晩100件のML実験を自律実行 – EffiFlow
- AutoResearch-RL: Perpetual Self-Evaluating Reinforcement Learning Agents for Autonomous Neural Architecture Discovery – Jain, N. et al. (2026), arXiv:2603.07300 (withdrawn)
- autoresearch@home – Ensue Network
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD