2026.01.27
Unitree G1にアクティブな動きをさせる(BeyondMimic解説)
Unitree G1にアクティブな動きをさせる(BeyondMimic解説)
はじめに
こんにちは。グループ研究開発本部、AI研究開発室のY.Tです。
最近はロボットをやっております。ヒューマノイドロボットの全身動作の制御などの研究開発にUnitree G1というロボットは弊社でも扱っており、触る機会が多いです。
このG1に任意の動きをさせようと思った時、例えば何かパンチのような動きをさせる、というのは思っているより簡単です。
G1では上体の動きを記録させて再生するティーチングがアプリケーションとして提供されており、このアプリケーションを使えば特に何か自分たちで実装する必要はありません。
しかし、ジャンプやターンなど、下半身の動きを伴うアクティブな動きとなると話が変わってきます。ジャンプやターンなどの動きを姿勢制御をロバストに保ったまま行おうとすると、上体のみのパンチのように決まった動きを指示するのが難しく、より高度な制御が必要です。最近では、そういった動きの制御には強化学習を用いた制御などが用いられます。
ダンスでもしようと思ったら、モーションデータを用意し、学習環境を整え、ダンスの動きの獲得を目指して強化学習のトレーニングをする、みたいなことを色々とやらないといけないわけです。
G1の場合はUnitreeが強化学習に使うコードを公開してくれています。(https://github.com/unitreerobotics/unitree_rl_lab/tree/main)
そのため、1から全てを実装しなければいけないわけではないです。しかし、ただ動かすだけというわけにはいかず、ダンスをさせるにはいくつか試行錯誤が必要でした。
平成の名曲「U.S.A.」を
令和のヒューマノイドロボットが踊る!“カモンベイビーアメリカ”🤖🇺🇸#2025国際ロボット展 #DAPUMP pic.twitter.com/NxhYXXgbU4
— GMO AI&ロボティクス商事 (@GMO_AIR) December 5, 2025
ダンスを学習させる時の実装に関する話などは、他のブログ等で語られていますので別の機会に。
この記事では、強化学習の実装の元になっている手法であるBeyondMimicについて解説をしたいと思います。
概要
BeyondMimicは、人間のモーションデータから学習してヒューマノイドロボットに高度な運動スキルを獲得させる最先端のフレームワークです。従来の模倣学習手法では、不自然な動きになったり各モーションごとに細かな調整が必要だったり、習得した動き同士を組み合わせて新たなタスクをこなす汎用性に欠けるという課題がありました。BeyondMimicはこの問題を解決し、細かい設定の調整をせずに複数のモーション学習に対応し、訓練時に見ていないタスクへの適応できるようになっています。
下の図にBeyondMimicの全体パイプラインを示します。まず、強化学習(RL)によるモーショントラッキングで、人間のリファレンス動作を物理シミュレーション上のヒューマノイドに再現するポリシーを習得します。次に、それら各ポリシーで得られる状態–行動軌道データを変分オートエンコーダ(VAE)でエンコードし、潜在表現を抽出します。この潜在空間上で拡散モデル(拡散ポリシー)を軌道データに対して訓練し、状態–行動の潜在拡散モデルを構築します。最後に、この拡散モデルの推論時ガイダンス(分類器/コストガイダンス)技術を用いることで、新たに与えられた目的に沿うよう軌道生成を誘導し、未学習のタスクに対してもゼロショットで複合的な行動を合成・実行できるようにしています。
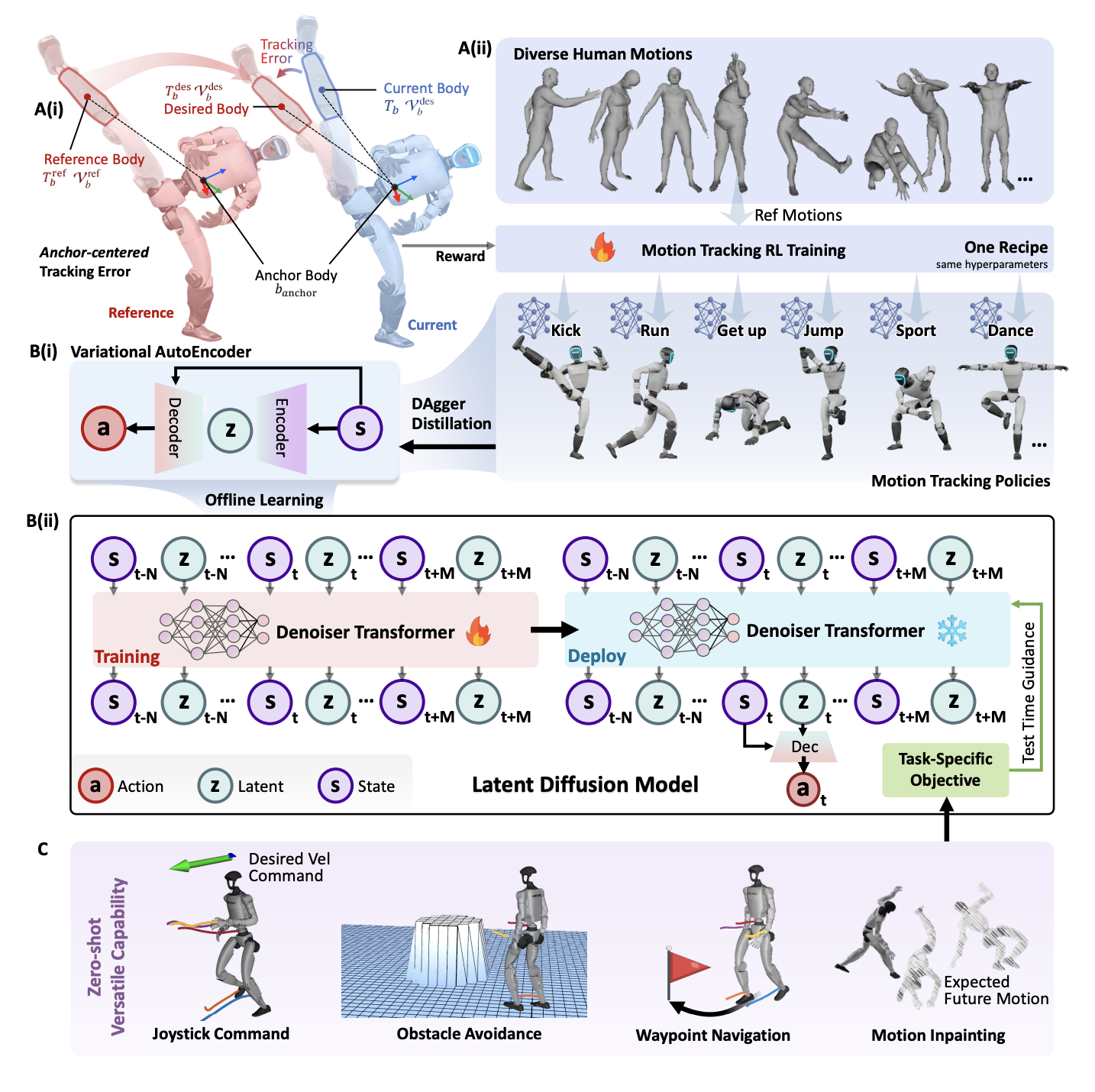
Humanoid Control via Guided Diffusion, Figure 7: Overview of the framework.)
実際にBeyondMimicは、指定位置への自律移動やジョイスティック遠隔操作、障害物回避など多彩な下流タスクを追加学習なしで実機ロボットに遂行させることに成功しています。以下では、このパイプライン各構成要素を順に説明し、それぞれがどのように連携して動作するかを解説します。
強化学習によるモーショントラッキング
BeyondMimicの第一段階では、人間のモーション追従を目的とした強化学習を用いて、物理シミュレーション内のヒューマノイドが与えられた参照動作(モーションキャプチャデータなど)を自然で物理的に実現可能な形で再現するポリシーを学習します。このモーショントラッキングポリシー学習は、PengらのDeepMimic(https://xbpeng.github.io/projects/DeepMimic/index.html)に代表される手法を発展させたポーズ追従を定式化して学習しています。ポイントは、ヒューマノイドの特定の身体部位(アンカー、通常は重心や胴体)を基準とし、そのアンカーのグローバルな位置姿勢のみを絶対座標で追従させる一方、それ以外の部分の目標姿勢はアンカーに対する相対座標系で定義しているところです。
このアンカー基準のトラッキングにより、ロボットは参照動作を維持しながら、全体の位置や向きのわずかなズレによる蓄積誤差(ドリフト)を許容できます。絶対位置を逐一一致させようとするとかえって挙動が不安定になりやすいですが、この方式であれば長時間の歩行やダイナミックな動きでもバランスを崩さず追従しやすくなります。
報酬設計も、物理的に不自然な動作を避けつつ高精度な追従を実現できるように調整されています。タスク報酬としては、手足や胴体など対象ボディ各部位の目標姿勢・速度と実際の姿勢・速度との誤差を計算し、それらをデカルト座標系のタスク空間で評価した追従精度に基づく正の報酬を与えます。どのくらい参照動作を追従できているかを計算するわけです。
物理的に不自然な動作を避けるには、罰則、つまり負の報酬を与えます。具体的には、関節の可動域制限から外れることへのペナルティ、連続する行動変化の大きさへのペナルティ(急激な制御変化の抑制)、および自己衝突の発生に対するペナルティ等が導入され、物理的に不合理な姿勢や振る舞いを避けるようにします。これらはロボットのハードウェア限界内で動作し、過度な振動や関節の逆行、自己干渉などを防ぐ役割を果たします。
基本的には上述の相対姿勢追従で十分にモーションの再現性を確保できるのですが、実際にはアンカーの全体的なグローバル位置追従精度に対する報酬を追加して、位置のずれに対策をすることがあります。
このような報酬設計により、個々の参照動作ごとに細かな報酬調整をせずとも高精度な模倣が可能になっています。これらの報酬はモーションごと、例えばジャンプやターンなど、学習したいモーションによって大きく買える必要がなく、汎用的なものです。
さらに、学習の安定性と効率を高めるために適応的なフェーズサンプリング(適応的サンプリング手法)が採用されています。これは、長時間の参照モーションを複数の時間区間(フェーズ)に区切り、それぞれの区間の開始位置からシミュレーションを始めたエピソードがどの程度失敗するか(失敗率)をモニタし、失敗率の高い困難な区間ほど訓練初期状態として選ばれる頻度を上げるというものです。例えば宙返りの瞬間などロボットが転倒しがちなフェーズはより多く練習させ、一方で容易な歩行区間ばかり学習が偏らないようにします。こうした難所への重点学習によって、途中の困難動作でポリシーが破綻するのを防いでいます。
これらの工夫により、著者らはジャンプスピン、カートホイール(側転)、後方宙返りキック、全力疾走といった多様なアクロバティック動作を、単一のアルゴリズム設定・ハイパーパラメータで安定して習得することに成功しています。
運動軌道の潜在表現抽出(VAE)
個々のモーションを学習しポリシーを獲得した後には、上記で学習した複数のモーショントラッキング・ポリシーから得られる軌道データを統合し、汎用の運動表現として扱うためのステップを踏みます。各ポリシーは例えば「宙返りキック」や「スプリント」等、それぞれ特定のモーションを実行するものですが、BeyondMimicではそれら多様な運動スキルを一つのモデルで扱うために、まず個々のモーションのポリシーが生成する状態–行動履歴をデータセットとして収集します。
このデータセットには、時間系列に沿ったロボットの関節角度や速度などの状態遷移と、それに対応する各時刻のアクション(関節トルクないし目標角度)の並びが含まれます。この高次元な軌道データをそのまま扱うのは計算的にも非効率なため、BeyondMimicではVariational Autoencoder(VAE, 変分オートエンコーダ)を用いて軌道の潜在表現(latent representation)を学習します。
VAEのエンコーダは一定長の軌道(状態とアクションのシーケンス)を入力として受け取り、それを低次元の潜在ベクトルに圧縮します。一方、VAEのデコーダはその潜在ベクトルから元の軌道を再構成(デコード)できるよう訓練されます。これにより、複雑なモーション軌道も情報を損なわずにコンパクトな数値表現に変換され、様々な運動パターンが内在する連続空間が得られます。
VAEによる潜在空間は、訓練データとして供給した熟練ポリシー群の動作分布を学習するため、この空間上の点は「人間らしく自然で物理的に実行可能なモーション」を表現するようになっています。言い換えれば、物理的制約を満たしたモーションプリミティブの辞書のような役割を果たし、この後段の生成モデルにとって扱いやすい特徴空間となります。
潜在拡散モデルによる軌道生成
得られたモーション軌道の潜在表現空間に対し、BeyondMimicでは拡散モデル(Diffusion Model)を用いた生成ポリシーの学習を行います。拡散モデルは近年注目される生成AI手法で、データに徐々にノイズを加えていき最終的にガウスノイズに変換する正方向プロセスと、その逆にノイズから元のデータを段階的に復元する逆方向プロセスを学習するものです。
BeyondMimicでは、この拡散モデルにトランスフォーマーベースのネットワークを採用し、状態–行動軌道の潜在ベクトルをデータとして学習させています。具体的には、前段のVAEで得た多数の軌道潜在ベクトルにノイズを付加していき、各ステップでのノイズ付きベクトルから元の潜在ベクトルを推定するネットワークを訓練します。訓練後のモデルは、任意のランダムなノイズベクトルから徐々に意味のある運動軌道を獲得するような能力を持ち、結果として個々のポリシー群が生み出した多様な運動軌道の分布を再現・補間できる生成モデルとなります。
このモデルは「拡散ポリシー」とも呼ばれ、入力として現在のロボット状態や初期姿勢を与えれば、それに続く将来の状態–行動シーケンスをプランニングすることも可能です。BeyondMimicはモーションキャプチャから得た複数スキルをオフライン蒸留により一つの条件付き軌道生成ポリシーへと凝縮とも言えます。
拡散モデルはもともと多峰的な分布や長い時系列データの生成が得意であり、モーションのバリエーションや非決定性を自然に扱える利点があります。この拡散ポリシーひとつであらゆるスキルを内包しているため、新たな目標に応じて自由に動作を組み合わせたり繋ぎ合わせたりできる柔軟性を持っています。
実際、従来の逐次計画+低レベル制御では、プランナーが生成した動きがロボットにとって実行困難だと失敗する問題がありましたが、BeyondMimicでは実行可能な軌道のみを生成モデルが学習しているためこの問題を大きく緩和できます。また、多様なモーションを直接一つの巨大ポリシーネットワークで学習する方法では新規目標への柔軟な条件付けが難しいですが、本手法は後述のガイダンスによる条件付けを組み合わせることで汎用性と柔軟性を両立しています。
推論時のガイダンスによる未学習タスクの合成
BeyondMimic最大の特徴は、上記の潜在拡散ポリシーに対し「分類器ガイダンス」とも呼ばれるテクニックを用いることで、推論段階で任意のタスク目標にポリシーを適応させられる点です。拡散モデル特有のテスト時最適化手法であるこのガイダンスでは、ユーザが達成したい目的をコスト関数という形で定義し、それに基づいて生成過程を逐次修正します。
具体的には、例えば「ロボットの最終位置が目標地点に近づくほどコストが下がる」あるいは「軌道中に障害物との接触が発生するとコストが上がる」といった損失関数を設計し、拡散モデルの各逆拡散ステップにおいてその勾配情報を利用して生成中の軌道潜在を微調整します。これにより、生成される運動軌道が目的に適合する方向へと誘導されます。重要なのは、この一連の操作にファインチューニングなどの追加の学習が不要という点です。
コスト関数さえ定めれば、拡散モデルが持つ運動の潜在知識を自由に組み合わせてその目的を達成するモーションシーケンスをその場で合成できるのです。たとえば、目標地点までの移動動作では「ゴールへの距離が小さくなる」報酬でガイドし、障害物回避では「障害物との衝突ペナルティ」を組み込むことで回避行動を引き出し、ジョイスティック操作では「指定された並進・回転速度に近づくように」といったコストでリアルタイムにロボットの動きを追従させます。
BeyondMimicの実験では、これらの手法により訓練時に経験していないタスクを次々にゼロショットで実現できることが示されています。下の図に示すように、障害物がある環境での目標地点への自律移動や、人がジョイスティックで指示した方向へ即座に歩行モーションを合成して進む遠隔操作など、タスクごとに追加のポリシー学習をせずとも拡散ポリシーにコストを与えるだけで柔軟に対処できます。
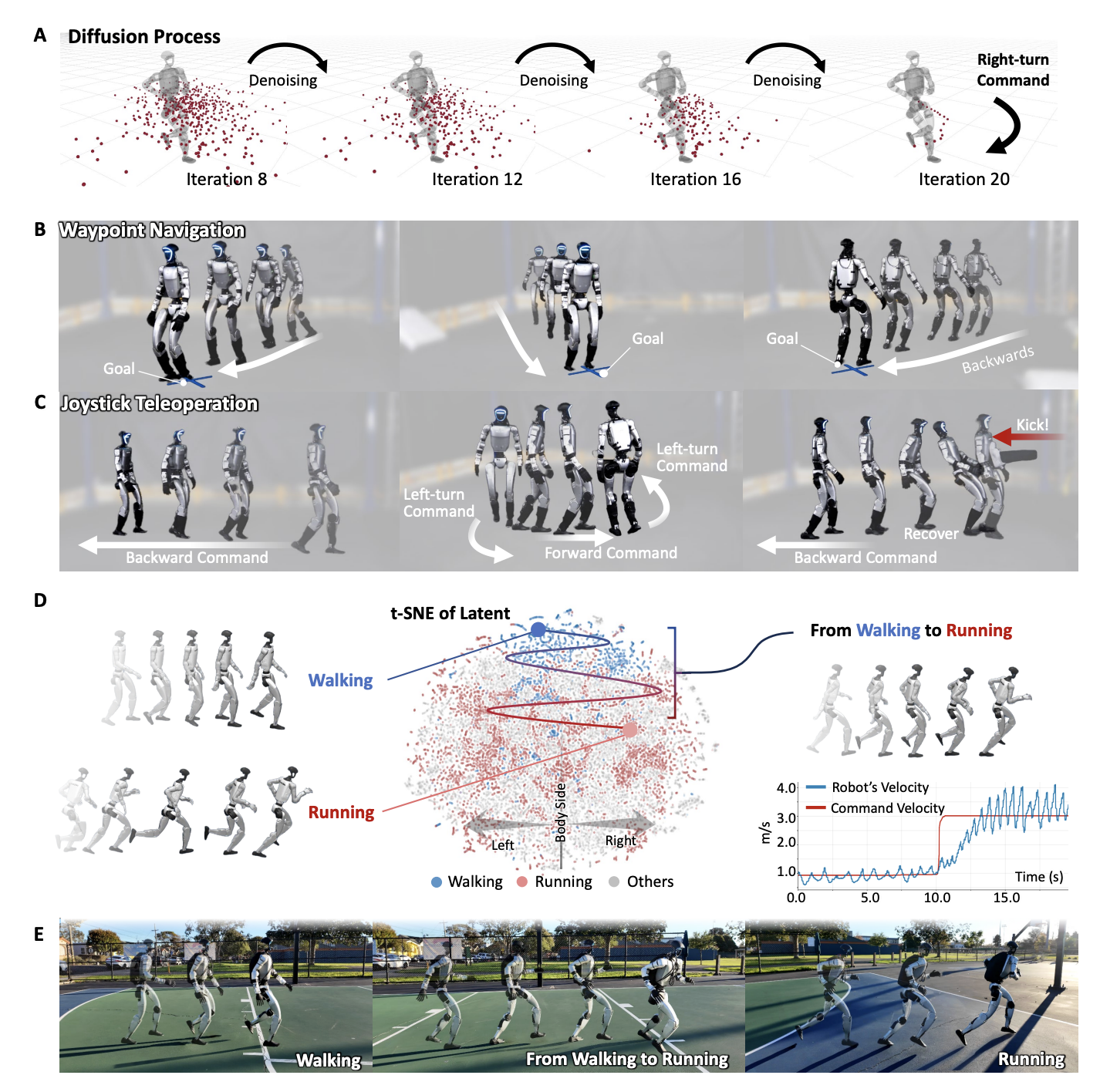
Humanoid Control via Guided Diffusion, Figure 5: Command-conditioned locomotion via guided diffusion.
さらに得られた軌道はシミュレーション上だけでなく実機ロボット(Unitree G1)上でもそのまま実行可能であり、バランスを崩すことなくダイナミックな動作が連続的に繰り出されました。これは、拡散モデル自体が物理的に妥当な行動しか生成しないよう学習されているためで、もし未知の状況(例えば足場の不規則な傾きや突発的な外力)があっても、従来の深層強化学習エージェントのように訓練分布を外れた挙動で暴走するのではなく安全側に振る舞う傾向が報告されており、興味深いです。
まとめ
BeyondMimicは、モーショントラッキングの精密さと生成モデルの柔軟さを組み合わせることで、ヒューマノイドロボットの運動制御における汎用性と適応性を飛躍的に高めました。アンカー相対トラッキングとシンプルで汎用的に調整された報酬により多種多様な人間モーションを習得し、VAEによる潜在表現でそれらの特徴を抽出、拡散モデルにより統一ポリシーとして蒸留、さらにコストガイダンスでゼロショットの動作への適応を達成しています。この統合パイプラインによって、従来は個別にチューニングが必要だったスキル群が単一モデルにまとまり、しかもその場で組み合わせて新タスクに対応できるモデルが獲得できました。
と、色々書きましたが、後半の拡散ポリシー周りは公開実装が見つからないんですよね。プリセットの動作でも使っているとは思うのですが。
また、論文中のAppendixにconfigの細かい調整や実機の計算スペックなど書かれており興味深いです。拡散ポリシーの推論は最適化された実行でもリアルタイム制御できる周波数で実行するにはRTX4060相当が必要なようで課題はある印象でした。拡散ポリシーについては自分も今後調査していきたいと思います。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion (arXiv)
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD