2025.01.07
MarkItDownを活用した請求書データ抽出機能の検証
1. はじめに
こんにちは、次世代システム研究室のT.D.Qです。ビジネスでは、PDFや画像形式の請求書からデータを抽出する作業が頻繁に発生します。本記事では、Microsoftの「MarkItDown」ライブラリとOpenAIの「GPT-4o API」を活用し、効率的かつ正確に請求書データを解析・抽出できないか検証を解説します。
目次
2. なぜMarkdown形式を選んだのか
Markdown形式は、シンプルで軽量なマークアップ言語であり、様々なシステムでの互換性が高いことが特徴です。MicrosoftとMITの研究では、Markdown形式のプロンプトを使用することで、LLM(大規模言語モデル)の性能が向上することが示されています。この特性を活かし、請求書データの解析精度を向上させることを目指しました。
2-1. MarkItDownについて
MarkItDownは、Microsoftが開発したPythonライブラリであり、さまざまな形式のファイルをMarkdown形式に変換する機能を提供します。このライブラリの主な特徴は以下の通りです:
- 対応形式:Officeドキュメント(Word、Excel、PowerPoint)、PDF、画像(OCR対応)、HTML、CSV、JSON、XML
- 簡単な使用方法:シンプルなコードで複雑なドキュメントを処理可能
- 互換性:GPT-4oなどの大規模言語モデルと統合可能
MarkItDownは特に、GPT-4oのOCR機能を活用して画像や手書き文書から正確にテキストを抽出する能力を持ち、多くのビジネスユースケースで活用できます。
3. データ抽出の手順
3-1. Pythonによる実装
実装したコードは以下の通りです。PDF、Excel、画像などの請求書データを自動抽出し、JSON形式で出力する機能です。
各ファイル形式に応じた専用ハンドラ(PDFHandler、ExcelHandler、ImageHandler)を採用しています。
MicrosoftのMarkItDownライブラリとOpenAIのGPTモデルを活用してテキスト抽出と構造化を実現。
抽出結果は、OpenAI APIを通じてプロンプトを使用し、請求書項目を正確に整形します。
拡張性とエラーハンドリングに優れており、新しいファイル形式にも対応可能な設計です。
import json
import openai
import os
from markitdown import MarkItDown
from openai import OpenAI
class FileHandlerStrategy:
"""Base class for file handling strategies."""
def handle(self, file_path, markitdown, **kwargs):
raise NotImplementedError("Subclasses must implement this method.")
class PDFHandler(FileHandlerStrategy):
"""Handler for PDF files."""
def handle(self, file_path, markitdown, **kwargs):
print("Processing PDF...")
return markitdown.convert(file_path)
class ExcelHandler(FileHandlerStrategy):
"""Handler for Excel files."""
def handle(self, file_path, markitdown, **kwargs):
print("Processing Excel...")
sheet_name = kwargs.get("sheet_name")
return markitdown.convert(file_path, sheet_name=sheet_name)
class ImageHandler(FileHandlerStrategy):
"""Handler for Image files."""
def handle(self, file_path, markitdown, **kwargs):
print(f"Processing Image: {file_path}")
llm_prompt = kwargs.get("llm_prompt")
result = markitdown.convert(file_path, llm_prompt=llm_prompt)
if not result or not getattr(result, "text_content", None):
raise ValueError(f"Failed to process image: {file_path}")
return result
class InvoiceExtractor:
def __init__(self, llm_model="gpt-4o"):
"""Initialize the InvoiceExtractor class."""
api_key = os.environ.get("OPENAI_API_KEY")
if not api_key:
raise EnvironmentError("OPENAI_API_KEY is not set in environment variables.")
self.client = OpenAI(api_key=api_key)
self.llm_model = llm_model
self.markitdown = MarkItDown(llm_client=self.client, llm_model=llm_model)
# Dynamic handler registration
self.handlers = {
'pdf': PDFHandler(),
'xls': ExcelHandler(),
'xlsx': ExcelHandler(),
'png': ImageHandler(),
'jpg': ImageHandler(),
'jpeg': ImageHandler()
}
self.invoice_extract_prompt = """
以下の請求書の内容から、以下の項目を正確に抽出し、JSON形式で出力してください。
抽出する項目が存在しない場合は "null" を記入してください。
請求書の項目:
1. 請求書番号
2. 発行日
3. 支払期日
4. 請求元会社名
5. 請求元住所
6. 請求先会社名
7. 請求先住所
8. 明細項目(項目名、数量、単価、金額、税率、備考)
9. 小計
10. 消費税
11. 合計金額
12. 支払方法
13. 備考
JSON形式での出力:
"""
def extract_invoice_content(self, text_content):
"""Extract structured content using OpenAI's chat completions."""
response = self.client.chat.completions.create(
model=self.llm_model,
messages=[
{
"role": "system",
"content": (
"You are a professional accountant specialized in Japanese invoices. "
"Your task is to accurately extract key information from invoices in Japanese and format them as structured JSON. "
"Do not make assumptions, and if a value cannot be determined, leave it as null."
)
},
{
"role": "user",
"content": self.invoice_extract_prompt + "\n請求書データ:\n" + text_content
}
]
)
return response.choices[0].message.content
def extract(self, file_path, sheet_name=None):
"""General method to extract invoice content based on file extension."""
extension = file_path.split('.')[-1].lower()
handler = self.handlers.get(extension)
if not handler:
raise ValueError(f"Unsupported file type: {extension}")
content = handler.handle(
file_path,
markitdown=self.markitdown,
sheet_name=sheet_name,
llm_prompt=self.invoice_extract_prompt
)
if not content or not getattr(content, "text_content", None):
raise ValueError(f"Failed to extract content from file: {file_path}")
return self.extract_invoice_content(content.text_content)
3-2. PDF請求書のテスト
以下のPDFファイルを使用してテストを実施しました。
入力ファイル: invoice_sample.pdf
スクリーンショット:

使用したコード:
extractor = InvoiceExtractor(llm_model="gpt-4o")
try:
result = extractor.extract("invoice_sample.pdf")
print(result)
except Exception as e:
print(f"Error: {e}")
結果:
Processing PDF...
```json
{
"請求書番号": "123456-123",
"発行日": "2021年12月30日",
"支払期日": "2021年12月31日",
"請求元会社名": "株式会社 日本サンプル",
"請求元住所": "〒123-1234 東京都杉並区〇〇〇1-2-3 △△△ビル 1F 123",
"請求先会社名": "株式会社サンプル 〇〇支社",
"請求先住所": "〒123-1234 東京都世田谷区〇〇〇 1-2-3",
"明細項目": [
{
"取引日": null,
"項目名": "サンプル タイプA",
"数量": 10,
"単価": 12345678,
"金額": 123456780,
"税率": null,
"備考": null
},
{
"取引日": null,
"項目名": "システム機器(自動調整タイプ)",
"数量": 2,
"単価": 123456789,
"金額": 246913578,
"税率": null,
"備考": null
},
{
"取引日": null,
"項目名": "システムの取付作業",
"数量": 3,
"単価": 40000,
"金額": 120000,
"税率": null,
"備考": null
},
{
"取引日": null,
"項目名": "システムの操作説明 講習会",
"数量": 4,
"単価": 5000,
"金額": 20000,
"税率": null,
"備考": null
},
{
"取引日": null,
"項目名": "素材 (✖✖を含む)",
"数量": 50,
"単価": 3000,
"金額": 150000,
"税率": null,
"備考": null
}
],
"小計": 370870358,
"消費税": 37087035,
"合計金額": 407957393,
"支払方法": "銀行振込",
"備考": "お振込手数料は御社ご負担にてお願いします。"
}
```
評価:
PDFファイルからのデータ抽出において、特に表形式のデータの検出が正確ではなく、多くの箇所で誤りが見られました。これは、MarkItDownが表形式のPDFファイルを処理する際に抱える弱点であり、OCRシステムにとって表形式データの扱いが困難であることが影響している可能性があります。この点を改善することで、より高精度なデータ抽出が期待されます。
3-3. Excel請求書のテスト
提供されたExcelテンプレートを使用してテストを行いました。
スクリーンショット:

使用したコード:
extractor = InvoiceExtractor(llm_model="gpt-4o")
try:
result = extractor.extract("invoice_sample.xlsx", sheet_name="請求書")
print(result)
except Exception as e:
print(f"Error: {e}")
結果:
Processing Excel...
```json
{
"請求書番号": "123456-123",
"発行日": "2021-12-30",
"支払期日": "2021-12-31",
"請求元会社名": "株式会社 日本サンプル",
"請求元住所": "〒 123-1234 東京都杉並区〇〇〇1-2-3 △△△ビル 1F 123",
"請求先会社名": "株式会社サンプル 〇〇支社",
"請求先住所": "〒 123-1234 東京都世田谷区〇〇〇 1-2-3",
"明細項目": [
{
"取引日": null,
"項目名": "○○○○○○ サンプル タイプA",
"数量": 12345678,
"単価": 10,
"金額": 123456780,
"税率": null,
"備考": null
},
{
"取引日": null,
"項目名": "△△△△ システム機器( 自動調整タイプ )",
"数量": 2,
"単価": 123456789,
"金額": 246913578,
"税率": null,
"備考": null
},
{
"取引日": null,
"項目名": "△△△△ システムの取付作業",
"数量": 3,
"単価": 30000,
"金額": 90000,
"税率": null,
"備考": null
},
{
"取引日": null,
"項目名": "△△△△ システムの操作説明 講習会",
"数量": 40,
"単価": 4000,
"金額": 160000,
"税率": null,
"備考": null
},
{
"取引日": null,
"項目名": "□□□□○○○○素材 ( ✖✖ を含む )",
"数量": 50,
"単価": 5000,
"金額": 250000,
"税率": null,
"備考": null
}
],
"小計": 370870358.0,
"消費税": 37087035,
"合計金額": 407957393,
"支払方法": "銀行口座振込 ( 普 ) 01234567 カ) ニホン サンプル 支店名:△△△",
"備考": "※お振込手数料は御社ご負担にてお願いします。"
}
```
評価:
Excelファイルからの抽出も問題なく動作しました。マルチシートの処理がスムーズで、指定されたシートのみのデータを正確に抽出できました。
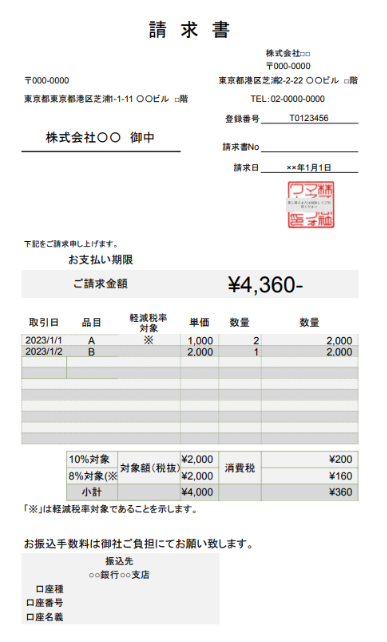
3-4. 画像請求書のテスト
画像形式の請求書についてもテストを実施しました。
スクリーンショット:
使用したコード:
extractor = InvoiceExtractor(llm_model="gpt-4o")
try:
result = extractor.extract("invoice_sample.png")
print(result)
except Exception as e:
print(f"Error: {e}")
結果:
Processing Image: invoice_sample.png
```json
{
"請求書番号": null,
"発行日": "2023年1月1日",
"支払期日": null,
"請求元会社名": "株式会社○○",
"請求元住所": "〒000-0000 東京都港区芝2-22-22 ○○ビル○階",
"請求先会社名": "株式会社○○",
"請求先住所": "〒000-0000 東京都新宿区西新宿1-1-1 ○○ビル○階",
"明細項目": [
{
"取引日": "2023/1/1",
"項目名": "A",
"数量": "2",
"単価": "1,000",
"金額": "2,000",
"税率": "10%",
"備考": null
},
{
"取引日": "2023/1/2",
"項目名": "B",
"数量": "2",
"単価": "2,000",
"金額": "4,000",
"税率": "8%",
"備考": null
}
],
"小計": "4,000",
"消費税": "360",
"合計金額": "4,360",
"支払方法": null,
"備考": "※支払期限内の支払"
}
```
評価:
画像請求書の抽出も非常に正確であり、OCRを活用して明細データも正確に取得できました。
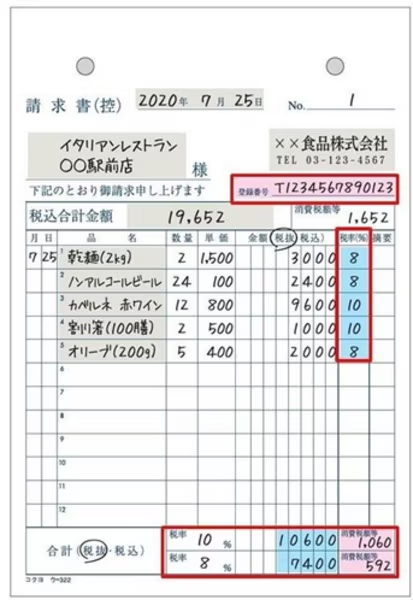
3-5. 手書き請求書のテスト
手書きの請求書データについてもテストを実施しました。
スクリーンショット:
使用したコード:
extractor = InvoiceExtractor(llm_model="gpt-4o")
try:
result = extractor.extract("handwriting_invoice_sample.png")
print(result)
except Exception as e:
print(f"Error: {e}")
結果:
Processing Image: handwriting_invoice_sample.png
```json
{
"請求書番号": "1",
"発行日": "2020年7月25日",
"支払期日": null,
"請求元会社名": "××食品株式会社",
"請求元住所": "〒1234567890123",
"請求先会社名": "イタリアンレストラン ○○駅前店",
"請求先住所": null,
"明細項目": [
{
"項目名": "乾麺(2kg)",
"数量": 2,
"単価": 1500,
"金額": 3000,
"税率": 8,
"備考": null
},
{
"項目名": "ハンブルコーヒービール",
"数量": 12,
"単価": 800,
"金額": 9600,
"税率": 8,
"備考": null
},
{
"項目名": "カルボナードホワイト",
"数量": 10,
"単価": 1000,
"金額": 10000,
"税率": 10,
"備考": null
},
{
"項目名": "サラリ塩(100g詰)",
"数量": 2,
"単価": 500,
"金額": 1000,
"税率": 10,
"備考": null
},
{
"項目名": "オリーブ(200g)",
"数量": 5,
"単価": 400,
"金額": 2000,
"税率": 8,
"備考": null
}
],
"小計": 19652,
"消費税": {
"10%": 1060,
"8%": 592
},
"合計金額": 21052,
"支払方法": null,
"備考": null
}
```
評価:
手書きの請求書でも、OCRの精度が高く、ほとんどの項目が正確に抽出されました。わずかな手動修正が必要な場合がありましたが、全体的なパフォーマンスは良好です。
4. おわりに
MarkItDownとGPT-4oを組み合わせることで、請求書データの抽出を効率化できます。特に、複数形式(PDF、Excel、画像、手書き)の請求書への対応力は実務上の大きなメリットです。ぜひ試してみてください。
5. 技術者募集の案内
次世代システム研究室では、最新技術を活用したシステム開発に興味を持つエンジニアを募集しています。ご興味のある方はこちらからご応募ください。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD






