2022.01.11
MLOps on GCP 入門 〜Vertex AI Pipelines 実践〜
ご覧いただきありがとうございます。次世代システム研究室の N.M.と申します。
前回のブログでは kedro を使って MLOps っぽいことを見様見真似でやってみましたが、今回はより実用的なものに手をつけてみようと GCP における機械学習プラットフォームである Vertex AI を使ってみたという内容になります。モニタリングなどを絡めてをガシガシ実践できたらいいなぁと思っていたのですが、これがなかなか一筋縄ではいかず…。今回のブログでは表形式データの前処理から前回のブログでできなかったモデルのデプロイまでのパイプラインを作るという基礎的な内容に留まっていますが、最後までお読みいただければ幸いです。
要約
- Vertex AI Pipeline でデータの前処理 => モデル作成 => デプロイまでの一連の流れを作ってみる。
- デプロイの前に精度のチェックを行う処理を挟んでみる。
- 新サービスだけあって情報がまとまっていない。ベストプラクティスやドキュメントも含めて今後もより調査が必要。
Vertex AI と Vertex AI Pipelines
Vertex AI は 去年 5 月に開始した GCP 上における機械学習プラットフォームです。旧バージョンである AI Platform にあったサービスに加え、Workbench と呼ばれる便利な開発環境をはじめ、様々な機械学習エンジニアリングにかかわるサービスを一元的に実行できるようになっています。昨年末ごろまで、公式のガイドには至る所にプレビューのマークが付いていたのですが、少しづつ正式版に移行しつつあり、実用フェーズに入ってきたかなと感じます。
その中でも今回は前回のブログでも使った kedro のように機械学習パイプラインを作成することができるサービスであり、2021 年の 11 月 15 日に一般提供が開始された Vertex AI Pipelines を取り上げていきたいと思います。
概要
Vertex AI Pipelines といっても Google らしく内部では Kubeflow Pipelines と Tensorflow Extended が使われており、前者二つを使用したことのある方にとっては Vertex AI Pipelines のために覚えなければならないことは少ないと思います。どちらの実装を選ぶかについては公式のガイドに下記のように書かれていました。今回は Kubeflow Pipelines を選択して実装していきます。
- テラバイト単位の構造化データまたはテキストデータを処理する場合は Tensorflow Extended (TFX)
- それ以外の場合は Kubeflow Pipeline SDK (KFP)
Vertex AI をいろいろと触ってみて感じた点として、データセットを作成するところから 同じく Vertex AI のサービスである AutoML を使ってモデルを作るまでは GCP Console 上の GUI からサクサクできるのですが、パイプラインに関してはGUI でパイプラインを作ってコードが作成されるわけではなく、コードを書いてコンパイルして出力された JSON ファイルから図が作成されるという形式であるため、まだまだカジュアルに使う域にはないです。そもそも機械学習パイプラインを作りたい人間がカジュアルを求めているのかは置いておいて、今後のアップデートに期待したいところではあります。
また、実用フェーズに入ってきたとはいえ、まだまだ新規のサービスのため情報がまとまっていないです。最も厄介だった点は、バージョンによる違い、特に後述の Google cloud パイプライン コンポーネントにおけるバージョン間違いの大きさでした。実装する際に codelab などでサンプルコードを漁っていたのですが、後述の Google Cloud パイプライン コンポーネントのアウトプットの class が変わってしまい値が渡せなかったり、0.1.6 から 0.1.7 に変えることで“No module …“のエラーが出たりなど振り回されました。この後も少し触れますが、情報の少なさとデバッグの難しさから非常に厳しい戦いでした。
ただ、GCP の Console(GUI)上であればボタンを押して指示に従いながらデータセット作成 => モデル構築 => デプロイにとどまらず、テストや監視までスムーズにできます。これをコードで実行できればより効率化も進むので、今後も注目していきたいです。
コンポーネントとパイプライン
Vertex AI では、モデルのトレーニングやデプロイなどの処理を行うコンポーネント(@component デコレータが付きます)と、それらを実行する順番を定義するパイプライン(@pipeline デコレータが付きます)の二つを組み合わせて実装していきます。
このような考え方自体は Vertex AI に限りません(例:kedro における node と pipeline 相当)。しかしながら、GCP の強みとして GCR(Container Registry) に push されているビルド済みの docker image を簡単に再利用できるほか、主な処理は既にコンポーネントが実装されているなど、より中身を知らなくても実装できるようになっています。ただし、「中身を知らなくても書けるからすごく便利じゃん!」と手放しに喜ぶことはできませんでした(デバッグの際に中身が分かりづらく痛い目を見ました…)。
コンポーネントはパイプライン上の処理を一つ一つ分解した単位のことです。
例えば、データを取得 -> モデル作成 -> デプロイであれば「データを取得」、「モデル作成」、「デプロイ」がそれぞれコンポーネントとなり得ます。上述の通り、コンポーネントの実装にはさまざまなパターンが存在します。その中でも、以下の 3 つが主要になっていると思います。
- パイプラインのソースコードに関数ベースで書く
- Google Cloud パイプライン コンポーネントを使う
- GCR に push されている docker image を使う
一つ目のパイプラインのソースコードに関数ベースでの実装は、docker の image を使わなくても Python ベースで好きな処理を書くことができるため、自由度は高いですが、後述の実装方法と比べて再利用のしやすさは劣ります。個人的には Vertex AI workbench と非常に相性が良く実装がしやすかったため、今回のブログはこの実装方法を使っています。この実装方法ではこちらの codelab が非常に参考になります。
二つ目の Google Cloud パイプライン コンポーネントを使う実装では、「AutoML を使って表形式のデータからモデルを作りたい!」や「エンドポイントを作ってモデルをデプロイしたい!」など、よく使うであろう処理(裏を返せばよく使えばベストプラクティスになるかもしれない処理)を事前に関数一発で呼び出して実行してくれるものになっています。例えば、下記のような関数でテーブルデータから Vertex AI Pipelines で使用するデータセットを作成してくれるような感じです。
from google_cloud_pipeline_components import aiplatform as gcc_aip
dataset_create_op = gcc_aip.TabularDatasetCreateOp(
project=project, display_name=display_name, bq_source=bq_source
)
GCR(Container Registry)を気にする必要すらなく、レールの上に乗っかっている分には非常に使いやすいですが、アレンジを加えようと思うとモデルのパラメータやテスト時に得られたメトリクスなどのアーティファクトの I/O にかなり気を遣うことになりそうです。この実装方法ではこちらの codelab が非常に参考になります。
三つ目の GCR に push されている docker image を使う実装は厳密にいえば二つ目の実装の一種であり、GCR に push されている image の URI を引数として与えることで処理を行う関数が用意されています。
from google_cloud_pipeline_components import aiplatform as gcc_aip
training_op = gcc_aip.CustomContainerTrainingJobRunOp(
container_uri=container_uri,
dataset=dataset_create_op.outputs[“dataset”],
training_fraction_split=0.8,
...
)
既にある docker image を使いたい場合 や Google Cloud パイプライン コンポーネントにはないが再利用する可能性がある処理はこの実装を使えばうまくいきそうです。この実装方法ではこちらの codelab が非常に参考になります。
上記のいずれかの形でコンポーネントを作成したのち、これらをつなげるパイプラインを作成していきます。例えばデータセットを作るコンポーネントとモデルを作るコンポーネントがあったとして、それらの間でデータを渡すには以下のような書き方になります。
@component(base_image=“python:3.9")
def foo_create_dataset(
bq_source: str,
dataset: Output[Dataset],
):
....
@component(base_image=“python:3.9”)
def var_create_model(
dataset: Input[Dataset],
model: Output[Model],
):
....
@pipeline(name=“foo_var_pipeline”)
def pipeline(bq_source: str = “bq://foo_var”):
create_dataset_op = gcc_aip.TabularDatasetCreateOp(
bq_source=bq_source
)
create_model_op = gcc_aip.TabularDatasetCreateOp(
dataset=create_dataset_op.outputs[“dataset”]
)
パイプライン構築系のライブラリでは逆に馴染み深い、よくわからない 独特な I/O です。Input[Dataset]やOutput[Model]などの括弧の中には、他にもテスト中などに得られたメトリクス(指標)をやりとりできるMetricsや一般に使えるArtifactなどがあります。この部分の理解がスムーズにパイプラインを作れるか否かに関わってきます。
パイプラインを python で記述した後、コンパイルして作成された JSON を GCP の Console から流したり、そのままメソッドから submit することでパイプラインが実行されます。
実装
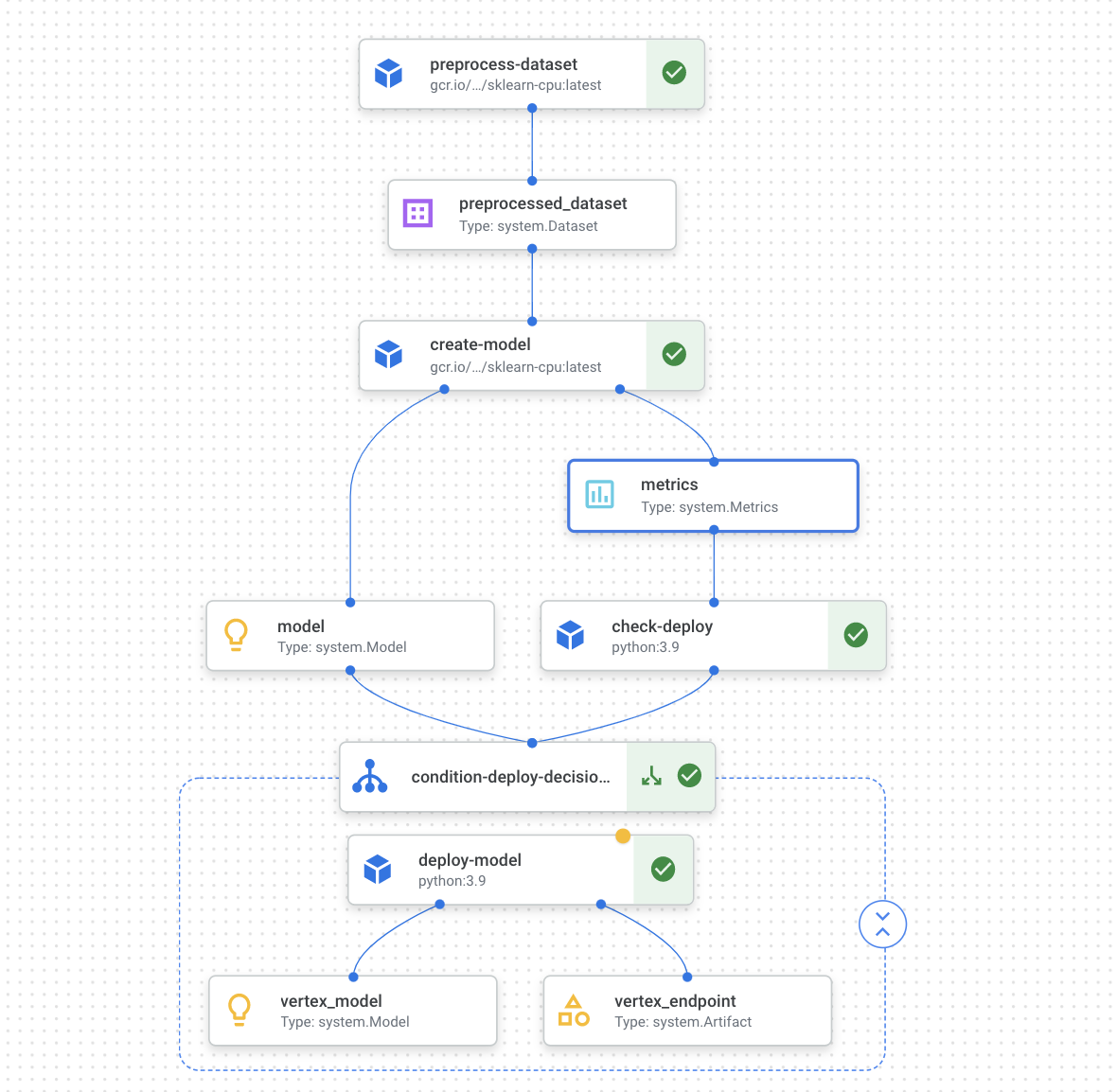
前置きが長くなりましたが、今回は年収のデータセットを使って機械学習モデルを構築しデプロイするまでの下図のようなパイプラインを構築していきたいと思います。今回のパイプラインに必要な以下のコンポーネント 4 つ+パイプラインを実装していきます。
前準備
パイプラインを作成するにあたって、パイプラインを実装・コンパイルする環境が必要になります。このcodelabをはじめ、Vertex AI Pipelines の codelab はこの環境を workbench で簡単に作成する手順をまとめてあるので、今回こちらのブログでは割愛させていただきます。なお、使用している KFP と Google cloud パイプライン コンポーネントのバージョンは以下の通りです。
KFP SDK version: 1.8.9 google_cloud_pipeline_components version: 0.1.6
コンポーネント
今回のパイプラインでは、以下の 4 つのコンポーネントを関数ベースで実装していきます。処理の中身に関しては特に吟味したものではないことを御留意ください。
- データの前処理
- モデルトレーニング
- 品質のチェック
- モデルのデプロイ
また、下記のライブラリを import しておきます。
import kfp from kfp.v2 import compiler, dsl from kfp.v2.dsl import component, pipeline, Artifact, Dataset, Input, Output, Model, Metrics, OutputPath from google.cloud import aiplatform from google_cloud_pipeline_components import aiplatform as gcc_aip from typing import NamedTuple
1. データの前処理
まずは、データの前処理を行うコンポーネントを実装します。今回使うデータセットである年収データセットに対して、カテゴリ変数に変更したり、欠損値のあるレコードを落としたりします。
component デコレータの中の base_image はこのコンポーネントをどの docker image 上で動かすかを指定しています。
gcs_file_path には事前 GCS(Cloud Storage)に入れておいた csv のパスを格納しておき、読み込む形にします。
OutputPathはOutput[Dataset]のように Object として出力を定義するのではなく、str として出力する部分がおおきく異なり、次のコンポーネントでもdf.read_csvで前処理済みのデータを読み込むため、パスで渡すことを想定しています。
@component(
base_image=“gcr.io/deeplearning-platform-release/sklearn-cpu:latest”
)
def preprocess_dataset(
gcs_file_path: str, # “gs://adult-vertex-ai-mlops/datas/adult.csv”
preprocessed_dataset: OutputPath(“Dataset”)
):
import pandas as pd
import numpy as np
dataFrame = pd.read_csv(gcs_file_path)
data = [dataFrame]
income_map={‘<=50K’:1,‘>50K’:0}
dataFrame[‘income’]=dataFrame[‘income’].map(income_map).astype(int)
...
dataFrame.to_csv(preprocessed_dataset)
2. モデルのトレーニング
次に、モデルのトレーニングを行うコンポーネントを実装します。今回はランダムフォレストを使います。入力はDatasetを想定し、Modelを出力します。また、作成されたモデルの精度が良い場合と悪い場合で今後のアクションを変えるために、Metricsに accuracy を保存しておき、これもアウトプットしておきます。
@component(
base_image=“gcr.io/deeplearning-platform-release/sklearn-cpu:latest”,
)
def create_model(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model],
):
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
X = df.drop([‘income’],axis=1)
y = df[‘income’]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=0)
skmodel = RandomForestClassifier(n_estimators=100)
skmodel.fit(X_train,y_train)
score = skmodel.score(X_test, y_test)
print(‘accuracy is:’,score)
metrics.log_metric(“accuracy”,(score * 100.0))
dump(skmodel, model.path + “.joblib”)
3. 品質チェック
前述のモデルがデプロイするに足るかをチェックするコンポーネントを実装します。metircs.metadataで前のコンポーネントで保存した accuracy にアクセスして、閾値よりも高ければ true, 低ければ false を返します。返し方もかなり特殊ではありますが、このあたりは一度再整理が必要かと思います。
@component(
base_image=“python:3.9”
)
def check_deploy(
deploy_th: float,
metrics: Input[Metrics],
) -> NamedTuple(“Outputs”, [(“dep_decision”, str)]):
import logging
if metrics.metadata[“accuracy”] > deploy_th:
dep_decision = “true”
else:
dep_decision = “false”
logging.info(“deployment decision is %s”, dep_decision)
return (dep_decision,)
4. モデルのデプロイ
最後にモデルをエンドポイントにデプロイする処理を実装します。component 内部のpackages_to_installでは必要な package を記述します(sk-learn の docker image で sk-learn を再宣言する必要などはありません)。aiplatform.Model.upload()で作成したモデルをアップロードして、戻り値として帰ってきたmodelに対してmodel.deploy()を実行することでエンドポイントが作られ、API 等から予測できるサービスとして動かせるようになります。
@component(
packages_to_install=[“google-cloud-aiplatform”],
base_image=“python:3.9”,
)
def deploy_model(
model: Input[Model],
project: str,
location: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model],
):
from google.cloud import aiplatform
aiplatform.init(project=project,location=location)
deployed_model = aiplatform.Model.upload(
display_name=“adult-trained-model”,
artifact_uri = model.uri.replace(“/model”, “/”),
serving_container_image_uri=“us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest”
)
endpoint = deployed_model.deploy(machine_type=“n1-standard-4")
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
パイプライン
上記のコンポーネント群を使ってモデルを作ってデプロイするまでのパイプラインを実装します。作成したコンポーネントをtmp_op = tmp()のような形で呼び出すと、tmp_opの中にアウトプットが格納されます。また、kfp.v2.dsl.Condition()を使うことで条件を満たす場合のみ内部の処理が実行するなどの条件分岐をすることができます。
@pipeline(name=DISPLAY_NAME,pipeline_root=PIPELINE_ROOT)
def pipeline(
display_name: str = DISPLAY_NAME,
project: str = PROJECT_ID,
bucket: str = BUCKET_NAME,
gcp_region: str = REGION,
deploy_th: float = 95.0,
):
preprocess_op = preprocess_dataset(
gcs_file_path=“gs://adult-vertex-ai-mlops/datas/adult.csv”,
)
training_op = create_model(
dataset=preprocess_op.output,
)
check_metric_op = check_deploy(
deploy_th=deploy_th,
metrics=training_op.outputs[“metrics”],
)
with dsl.Condition(
check_metric_op.outputs[“dep_decision”] == “true”,
name=“deploy_decision”,
):
deploy_model(
model=training_op.outputs[“model”],
project=project,
location=gcp_region
)
実装が終わった後、パイプラインをコンパイルします。以下のように記述し、実行することで json に変換されます。
TEMPLATE_PATH = “train.json”
compiler.Compiler().compile(
pipeline_func=pipeline, package_path=TEMPLATE_PATH
)
作成された json ファイルを GUI からアップロードするか、以下のようなコードを実行することで、パイプラインが作成され実行されます。PipelineJob のenable_cachingの引数(デフォルトは True)は実行時に変更のないコンポーネントはキャッシュされた結果を返すことで余分な計算をしないようにできます。コメントアウトを外してキャッシュを使わない設定にすると最初から実行されます。
from datetime import datetime
job = aiplatform.PipelineJob(
# enable_caching=False,
display_name=“train-pipeline”,
template_path=TEMPLATE_PATH,
job_id=“train-{0}“.format(datetime.now().strftime(“%Y%m%d%H%M%S”)),
parameter_values={
“display_name”: DISPLAY_NAME,
“gcp_region”: REGION,
“project”: PROJECT_ID,
“bucket”: BUCKET_NAME,
“deploy_th”: 70.0,
},
)
job.submit()
これでパイプライン作成から実行までが完了しました。作成されたエンドポイントをそのままにしておくとゴリゴリ課金されてしまうので、使わない場合はモデルのデプロイを解除したのち削除しておきましょう。
まとめ
今回のブログでは、Vertex AI Pipelines を使用してデータの前処理 => モデル構築 => デプロイまでのパイプラインを構築しました。昨年 11 月に一般開放されたサービスではありますが、ハイスピードでアップデートが実施されているため、こちらの実装もいずれは使えなくなる、または良いコードではなくなる可能性が高いです。ある程度落ち着いてきた段階で最も良い書き方の模索や、Cloud Scheduler と連携して定期的にパイプラインを実行する実装、Monitoring と連携して精度が悪くなってきたタイミングでパイプラインを実行する実装などができればより可能性が広がると思うので、Vertex AI Pipelines のベストプラクティスを引き続き模索しながら、機会があれば実装してみようと思います。ご覧いただきありがとうございました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティスト、及びグループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD