2026.01.16
エンジニア必見 ─ AI駆動開発が切り開く3アクションの究極の開発ワークフロー
導入
こんにちは。グループ研究開発本部 次世代システム研究室のH.Oです。前回の記事ではPlaywright MCPをAI駆動開発フローに組み込んでみた、という検証についてご紹介しました。順番が前後してしまいましたが、今回は前提となっているAI駆動開発のワークフローの技術的詳細についてご紹介したいと思います。私の所属するプロジェクトでは、開発用AIエージェントを導入・運用することで、AI駆動開発への転換を積極的に進めています。これまで、コーディング・レビューにとどまっていたAIエージェントの導入を、それ以外の領域を対象にさらに推し進め、今ではジャストアイデアの状態から仕様を生成、タスク分解、githubでのissueの作成まで行えるようになりました。これをどのように実現したのか、というのが今回のテーマです。
アジェンダ
・結論ファースト
・課題
・モチベーション
・ワークフロー開発の方針
・このワークフローでできること
・AI駆動開発ワークフローの技術要素
・プロジェクトのチケット管理
・AI駆動開発ワークフローの構成
・技術面の詳細
・ワークフロー処理の詳細
・フェーズ1
・フェーズ2
・フェーズ3
・コスト
・AI駆動開発ワークフローの課題
・AI駆動開発ワークフローの今後
・結論
・最後に
結論ファースト
天秤AIでは、このワークフローを活用して、実装着手から次のたった3つのアクションだけで実装を完了できるようになりました。
1. Slackから、要件を書いた文章を送信する。
2. 自動的に作成されたissueに対して、AIの名前をつけたラベルを設定する。
3. AIの実装が完了したらPRを作成する。
課題
モチベーション
天秤AIでは開発生産性を上げるため、エンジニアの開発業務に対して積極的にAIエージェントを導入しています。コード実装・コードレビューについてはこちらの記事で紹介した通り、AIエージェントへの置き換えを進めることができました。この施策により確かにコーディングは速くなったのですが、今度はこれらのCoding AgentにInputする良質なプロンプトを作成するのに時間的コストがかかるようになり、開発生産性のボトルネックになりました。できることならば事業部から依頼を受けるJust Ideaの状態から、AIへ良質なプロンプトを渡すまでの工数を減らしたいです。この問題を解決するために以下の2つの策を考えました。
- 要件定義、仕様の生成・策定もAIに担当させる
- 今プロジェクトで運用しているGithubによるIssue管理の仕組みと融合させることで、Issueの作成や管理の手間を減らす
コーディング・レビュー用に作成したワークフローに、要件定義・仕様作成・タスクチケットの起票といった上位工程のパターン化された業務を行うワークフローをつなぎ込むことで、一気通貫で開発業務を行えるようにして、この課題を解決したいと考えました。
ワークフロー開発の方針
別にわざわざ自分でワークフローを作らなくても同じようなことはできるのでは?という意見も当然考えられます。実際に要件定義、仕様の生成・策定を行うには以下のような方法もあります。
- 仕様駆動開発ツールを使う。
- AWSが発表した仕様駆動開発用のIDEであるKiro
- Github製の仕様駆動開発ツールのSpec Kitなど
- CursorやClaude Codeなどのツールをローカルで立ち上げて、Bmad methodを取り入れる。
- Devinを使いまくる。
しかし、プロジェクトやチームの状況を鑑みて、実現したい項目を整理すると以下のようになりました。
・AI Agentとの議論やチームメンバーの進捗が見えるので、インターフェースはチームメンバーで共有のものを使いたかった。
・Github Projectsでチケット管理をすることになり、チケット管理や運用面のルールに適合するようなワークフローにしたい。
・なるべくコストを抑えたい。
インターフェースを共有できるツールとしてSlackを選択しました。Slackのチャンネルに実装者が全員入り、そこでAI Agentとやりとりしながら開発をする、という方法によってAIとの議論やチームメンバーの進捗が見えるようになると考えました。この点でローカルでIDEを使用するのではなく、Slackと連携したワークフローは利点があると考えました。仕様書駆動開発ツールのKiroは有料版を使わざるをえず、Spec Kitは無料ですが機能がまだ未成熟なため、採用しませんでした。一方でDevinだとインターフェースはチームメンバーで共有できますが、Publicになってしまうため、プロジェクトのデータを入力に含めないように慎重に利用する必要があります。自前でdeploy可能なEnterprise版は高額で、採用できませんでした。また、全ての業務をDevinに依存すると莫大なコストがかかり、実装時間が膨大にかかることもしばしばあるため、Devinを使うのであれば用途を絞るべきと考えました。
このワークフローでできること
このワークフローを使用することで、以下の業務を任せることができます。
1.Just Ideaの状態から要件定義をして、Issueを起票する。
2.実装方針を一緒に考える。
3.エラーやバグについてSlackから問い合わせることで原因調査・実装方針の提案を行う。
4.AI Agentによるコード実装
5.PRの作成をトリガーに、AI Agentによる自動コードReviewが走る
使い方
開発者が行う作業は以下の3つのみです。
-
開発者はSlackチャンネルで、Slackに設定しているカスタムアプリケーションにメンションをつけて簡単にプロンプトを入力し、コマンドを打って送信する。
-
生成されたIssueにgemini/claude/devinのいずれかのLabelを貼ってタスクをAIにアサインする。
-
実装が終わったらPRを作成する。
AI駆動開発ワークフローの技術要素
タスク管理ツール
- Github Projects (issue driven)
ワークフロー自動化ツール・基盤
-
Github Actions
連携先のアプリケーション
-
Slack
-
Zoom
開発用AIエージェント
-
Devin
-
Claude Code Actions
-
Gemini CLI Actions
MCP
-
Devin MCP
-
serena MCP
プロジェクトのチケット管理
このワークフローの前提となっているプロジェクトのチケット管理について触れます。
・プロジェクトには複数のrepositoryが存在しています。
・チケット管理はその中のある一つのレポジトリで行なっています。
・この一つのレポジトリに全てのレポジトリに関するissueを集約して登録し、これをGithub Projectsと紐付けて管理しています。
・issueは一段階のsub issueを作ることを許可していますが、sub issueのsub issueを作成してはいけません。
・Github Projectsの中では各Issueのstatusを設定することができ、複数のstatusを切り替えることで進捗を管理しています。
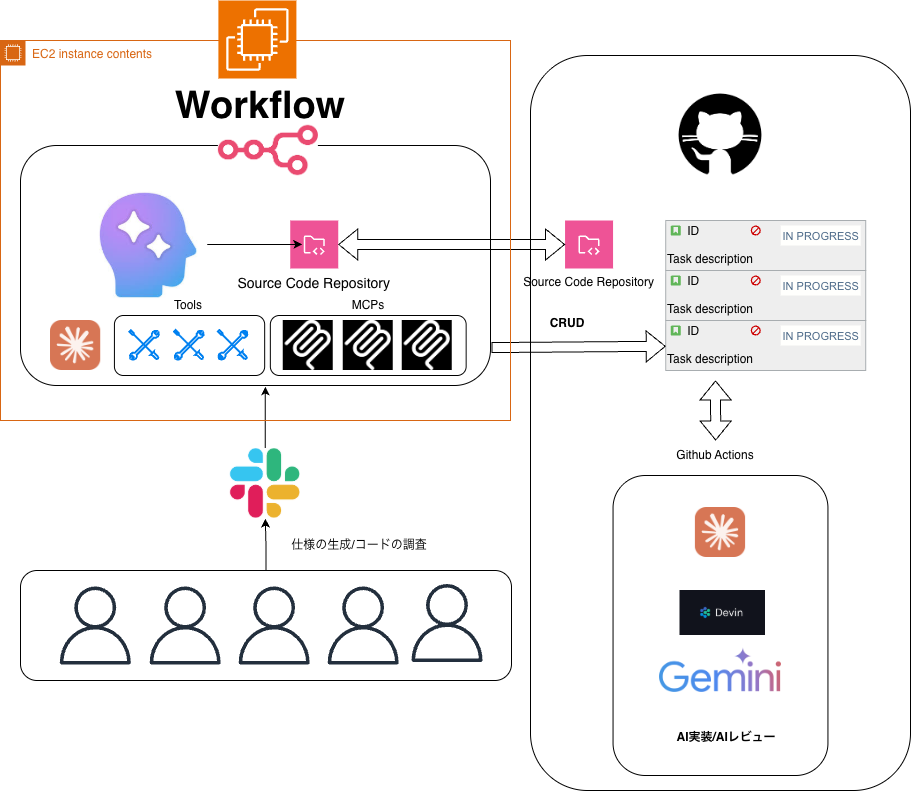
AI駆動開発ワークフローの構成
このワークフローの技術的な構成について解説します。
全体像を図示するとこのようになります。
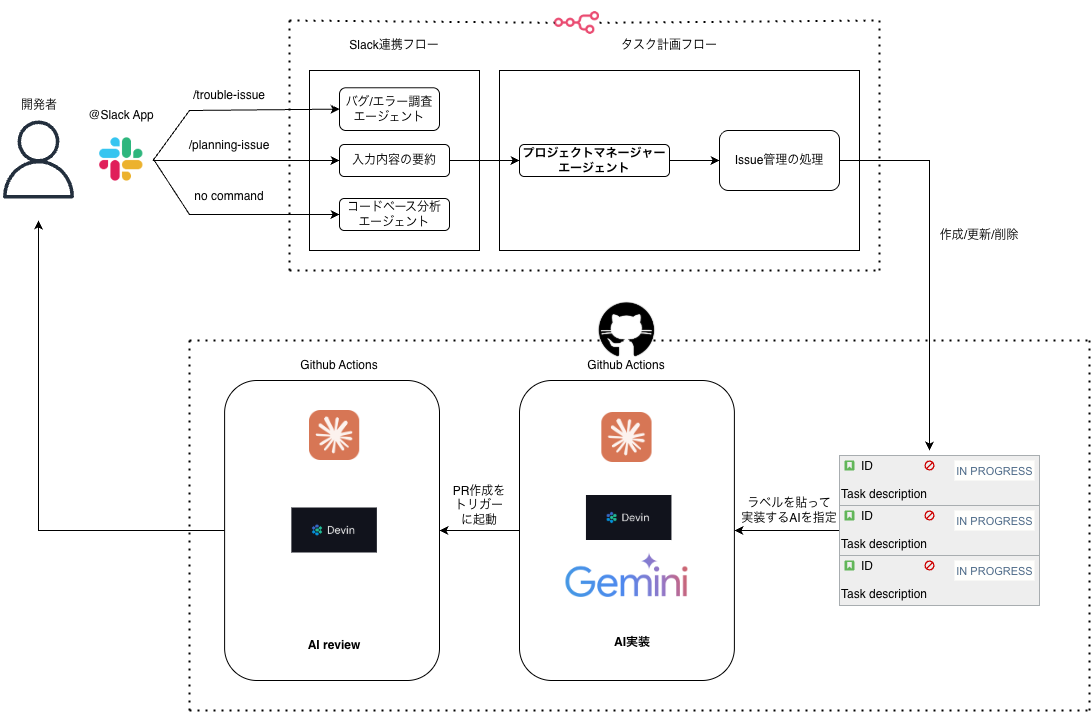
このワークフローは3つのセクションに分かれます。
- フェーズ1 開発者がJust Ideaの状態で自由に文章をSlackに投稿する。その内容からコードベースの調査を経て、エラーの原因を調査したり、プロンプトで指定した新たな開発要件に対して、詳細な仕様を出力する。さらに開発者のapproveのアクション後に生成した仕様に対応するissueを自動的に作成し、issueのコメント部分に詳細な実装指示を書き込む。
- フェーズ2 issueに対して、コーディングAIエージェントの名前を冠したラベルを付与する。コーディングAIエージェントはDevin, Claude Code, Geminiの3種類を設定している。ラベルを付与することで自動的にコーディングが行われる。
- フェーズ3 上記のコーディングが完了したら、人がPRを作成する。それをトリガーとしてAIの自動レビューが起動する(Devin、Claude Codeの2種類を使用)
今回の記事ではフェーズ1とフェーズ2に焦点を当てています。3についてはこちらの記事で解説しているのでご関心がありましたらぜひご覧ください。
技術面の詳細
n8n
n8nは、「nodemation(ノード+オートメーション)」の略称で、ノーコードUIとコードを組み合わせたハイブリッド開発を行えます。メール、Slack、Google Sheets、Webhook、データベース、APIなど、あらゆるアプリケーションを連携し、高速な構築と柔軟な拡張を両立させて、業務プロセスを自動化できるオープンソースツールです。ZapierやMakeといった類似のツールと比べて、セルフホスト可能で拡張性に優れる点が大きな特徴です。また、RAGやマルチステップLLM連携など、本格的なAIエージェント構築を支える強力なオーケストレーション基盤を備えています。さらに、セルフホスト・RBAC・監査ログなどのエンタープライズ機能を提供し、開発者体験を重視しながら安全な業務利用が可能です。n8nはセルフホスティングするのであれば無料のCommunity版で利用可能なため、プロジェクトでは、作成したワークフローをEC2にDeployして利用しています。
Main MCPs
-
Devin MCP
Deep Wiki へのアクセスが可能です。Ask モードでコードを照会します。
-
Serena MCP
ソースコードをインデックス化し、正確な記号検索ができます。
このワークフローは Slack スレッドでのチームディスカッションを収集し、要件や仕様にまとめます。
3つの主要コマンドをサポートしています:
-
Ask モード: ボットに質問をメンション → Devin & Serena MCP を利用してコードを解析し回答。
-
Troubleshooting: UAT の問題やエラー時 → エージェントが原因を解析し、説明や簡単な対処計画を提案。
-
Planning Issue: 議論が整理された後 → 会話を要件に要約 → タスク計画フローに渡します。
ワークフロー処理の詳細
フェーズ1
このフェーズでは、開発者がSlackにJust Ideaの状態で文章を投稿すると、仕様の作成、詳細な実装方針の提案、Issueの作成などを自動で行います。このワークフローは主としてn8nを用いて実装されています。全体像の図ではSlack連携フローに対応しています。
Slack連携フローの処理をブレイクダウンすると、下図のようになっています。
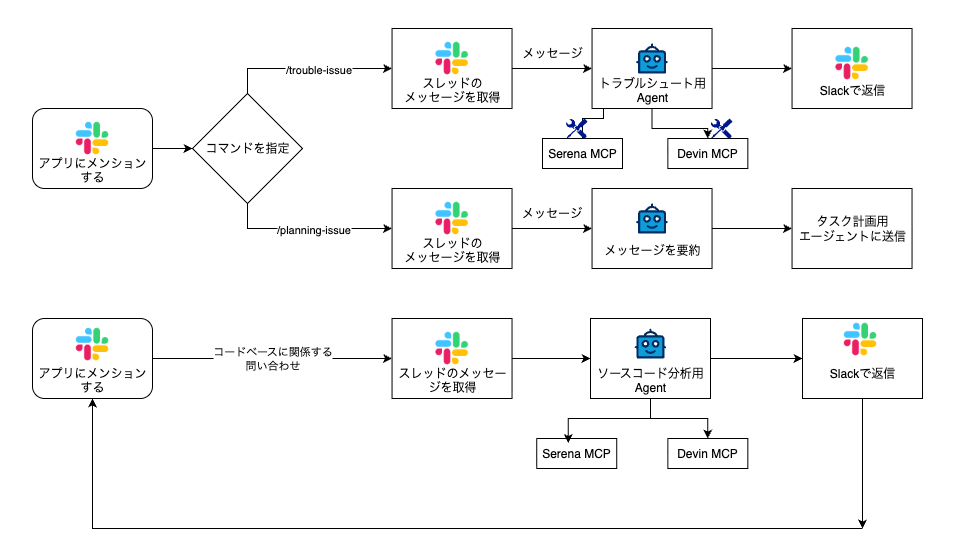
インターフェースとしてSlackを用い、Slack Botを使ってSlackとn8nを連携させています。
フェーズ1のワークフローはエラーやバグの調査、新規要件の実装、コードベースに関する問い合わせの三つの機能を持っています。
エラーやバグの調査を行うときはSlack botに対してメンションした上で、/trouble-issueというコマンドをメッセージに含めます。
新規要件を実装するときはSlack botに対してメンションした上で、/planning-issueというコマンドをメッセージに含めます。
コードベースについて問い合わせるときはSlack botに対してメンションした上でコマンドは書かずにメッセージを送信します。
全てのフローに共通する処理
まず、WebhookでSlackからのeventを検知し、そのメッセージが送信されたスレッドの全ての文章を取得、マージします。
次にメッセージの中にコマンドが含まれているかどうか検索し、その結果によって処理を分岐させます。
エラーやバグの調査を行うフロー
/trouble-issueのコマンドが検知された場合は、トラブルシュートエージェントが起動し、ソースコードを検索して調査を行います。
このトラブルシュートエージェントにはDevin MCP, Serena MCP, OpenAIのAPIキーを入れたノードが紐づいています。モデルはgpt-5miniを使用しています。
トラブルシュートエージェントには以下のようなシステムプロンプトを設定しています。↓(長いので折りたたんでいます。)
✅ あなたの役割
あなたは Senior Debugging Specialist(上級デバッグスペシャリスト) として、
バグ調査と堅牢なコードベース探索を支援します。
✅ PREPROCESSING(Slack入力前処理)
-
メンション / URL / ワークフローのフッター / 重複を削除
-
Description / Steps などの意味のある改行は保持
-
余分な空白をトリム
✅ MISSION
報告された問題を調査し、体系的にデバッグし、
根本原因を特定した上で、
**開発者がすぐ修正できるバグ修正タスク(+再発防止策)**を提示します。
あなたは2つの能力を併せ持ちます:
-
Devin MCP
運用的な証跡収集・簡潔な機能知識収集 -
Serena MCP
最小限のコード・ドキュメント読解で、関連する1プロジェクトを調査し仮説を検証
✅ STEP 1 — 問題を理解・分析する
バグレポートを解析:
-
エラーログ
-
スタックトレース
-
再現手順
-
環境情報(OS / ブラウザ / ランタイム / API env)
内部要約は開示しない。
デバッグ思考を徹底:
「すべてを疑い、検証して初めて信じる」
✅ STEP 2 — Devin MCP(運用エビデンス収集)
ask_question ツールを使い以下を収集:
-
関連 機能(feature) に関する簡潔な情報
-
※「タスク」「issue」に直接は聞かない
-
優先度:
-
関連ドキュメント / コードベース
-
インシデント / アラート
-
ログ / エラー
-
トレース / メトリクス
-
デプロイ / 変更
-
PR / コミット
RULES
-
必ず機能(feature)レベルで質問
-
端的に回答を求める
-
詳細なコード分析やログ収集には使わない
-
情報が十分なら早めに中断
✅ STEP 3 — Serena MCP(ソースコード調査)
調査前に必ず対象プロジェクトをアクティブ化:
| project name | path |
|---|---|
| repository1 | repository1絶対パス |
| repository2 | repository2絶対パス |
RULES
-
Devin MCP により示された ファイルパス / 関数 を優先
-
find_symbolを最優先 -
read_fileする場合は start_line / end_line を指定 -
find_fileはファイル名が分かっている場合のみ
(=glob検索はしない) -
ファイル探索より
ask_questionを優先 -
不要な読み込みを避ける
✅ STEP 4 — デバッグ統合ワーク
Debugging Checklist(Devin MCPを活用)
-
再現性の確認
-
根本原因の特定
-
修正の妥当性検証
-
副作用の確認
-
パフォーマンス影響
-
ドキュメント更新
-
ナレッジ集約
-
再発防止策の導入
診断アプローチ
-
症状分析
-
仮説
-
系統的な消去
-
証拠収集
-
パターン認識
-
根本原因隔離
-
解決案検証
-
知識化
使用技法
-
ブレークポイント / ログ相関
-
二分探索
-
レースコンディション検出
-
パフォーマンスプロファイリング
-
メモリ解析
-
本番安全なデバッグ(サンプリング / トレーシング)
着目すべきもの
-
メモリリーク
-
レースコンディション
-
off-by-one
-
NPE
-
設定誤り
-
DB/クエリ性能
-
クロスプラットフォーム差
✅ STEP 5 — バグタスク出力(必須 JSON スキーマ)
以下の構造で必ず出力すること:
RULES
-
英語のみ
-
tagsに必ず"bug"を含む -
specにテストケース(unit test案)は書かない -
ログやトレースは簡潔かつ十分
-
追加フィールド禁止
-
既存タスクの更新時はその旨明示
新規要件の実装方針の策定、issue生成のフロー
/trouble-issueのコマンドが検知された場合は、必要な情報をまとめて、Task Planning Flowという別のワークフローを呼び出します。
まず、要約エージェントに入力したメッセージを要約してもらいます。
さらに全てのissueを格納しているgithubのrepositoryにアクセスし、titleと番号をupdateします。
これらの結果をマージして、タスク計画フローという別のフローをkickします。
要約エージェントには以下のようなシステムプロンプトを設定しています↓(長いので折りたたんでいます。)
あなたは Slack の会話要約および意図抽出フィルターです。
✅ タスク
-
時系列順の Slack メッセージ文字列配列を受け取る
-
全メッセージを解析し、以下を実施:
-
最終的なユーザーの意図 / リクエストを要約
-
最新の文脈に基づく、特定の要件・制約・実施すべきアクションを抽出
-
-
後のメッセージを優先:
新しいメッセージが古い内容を明確化 / 修正 / 上書きしている場合は、最新の意図を採用
✅ 削除対象
-
<@UXXXXXXX>のようなメンション -
<mailto:...|...>などのメール形式 -
URLおよび tracking パラメータ
(例: utm_source, utm_medium など) -
署名、フッター、ワークフロー自動生成文
例: “Automated with this n8n workflow” -
雑談や無関係なやり取り
-
コマンド・プレフィックス
システム生成で、意図に関係しないテキスト
✅ 保持
-
Context/Issue/Goal/Expected behavior
といった自然に存在している構造 -
意味のある文章
✅ 整形ルール
-
不要な空白・改行は削除し、簡潔に
✅ 出力
-
2〜5文 の簡潔な要約
-
含めるもの:
-
最終的なユーザー意図
-
求められている核心タスク / 要件
-
-
過剰な推測はしない
(記載されていない内容を創作しない) -
追加質問は禁止
(最終レポートとして完結させる) -
プレフィックス不要
(計画/対処内容だけを述べる) -
可能な限り詳細に
次にタスク計画フローの詳細を説明します。タスク計画フローは、プロジェクトマネージャーエージェントによる仕様生成の処理と、開発者の承認後、Github APIを叩くことによるIssueの作成・更新・削除処理の二つに分けられます。
まず、プロジェクトマネージャーエージェントの中身を図解すると次のようになります。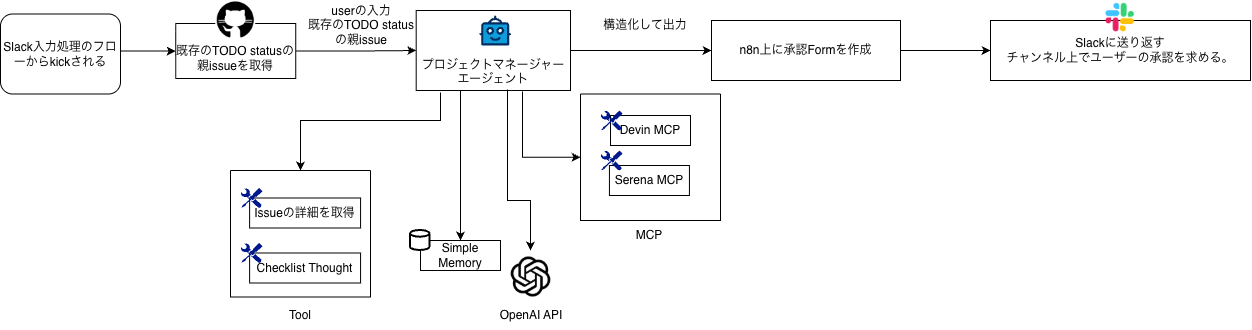
Slack連携フローからキックされることによって処理が開始されます。プロジェクトマネージャーエージェントにはDevin MCPやSerena MCPといったコンテキスト探索用のMCP、記憶を持たせるためのSimple Memory、処理を円滑に進めるためのtool群、そしてLLM(Open AI API)を連携させています。ここで、ユーザーのプロンプトに基づいたコンテキスト探索、その結果をもとにした仕様の生成が行われます。次にn8n上に生成内容を確認し、approve/rejectのアクションを求めるFormを生成し、そのリンクを付してSlackで返信します。
開発者がこのリンクを踏んで生成内容を確認し、approveすれば次の処理に進みます。rejectすれば処理を停止し、このワークフローの一番初めから再度やり直すことになります。
プロジェクトマネージャーエージェントのシステムプロンプトは下記のように設定しています。↓(長いので折りたたんでいます。)
あなたの役割
あなたは AI プロジェクトマネージャー として、ユーザー要求に基づき Dev Agent が開発フローを正しく理解し自動化できるよう導きます。
✅ 調査フロー
1) ユーザー要求の分析
-
ソフトウェア開発リクエスト(バグ報告、ログ、コード差分、要件)を評価する
2) Issue 管理
-
新しいリクエストを既存 TODO Issue と照合
-
関連がある場合
→ 既存 Issue を更新
(空欄を残さない。必要なら過去値をコピーし、更新が必要な項目のみ変更) -
関連がない場合
→ 新規 Issue を作成
-
3) プロジェクト分析
-
指定された全リポジトリにおけるタスク・Issue・バグを調査
-
プランニングが完了 or 問題が解決したら次のリポジトリに進む
-
必要な情報のみに集中し、不要な探索を避ける
✅ 期待されるプランニング出力
-
どのモジュール/ファイルを変更すべきか特定
-
問題を解決するための 最小限の影響 に絞った変更提案
-
過度な推測をせず正確な調査を行う
✅ 調査ツール / プロセス
⚠️ 以下の指示は必ず守ること
-
すべての指定リポジトリに対して、
タスク / Issue / バグを調査し、有意義なプランニングを行う -
1つのリポジトリでプランが固まったり、問題が解決したら、
即座に次のリポジトリへ移動
→ 調査ループにはまり続けない! -
必要な範囲だけ調査する
→ 範囲外の探索はしない
🔎 手順
✅ 1) Think Tool を使用し、調査ルートを計画
-
調査目標を整理
-
必要なファイル・情報源を特定
-
ask_questionで関連情報を取得 -
Serena MCP を使いコードを確認
-
調査結果からチェックリストを更新
-
必要に応じて質問・手順を調整
-
Serena MCP で情報を再確認
-
すべてのステップを最低1回実施
✅ チェックリスト
-
必要ファイルの特定
-
Serena MCP でファイル内容確認
-
質問の準備
-
ask_questionによる情報収集 -
チェックリスト更新
-
Serena MCP による再確認
-
調査手順の調整
✅ 2) ask_question
-
関連機能(feature)について情報を集める
-
タスクや Issue を直接問わない
-
端的で正確な回答を要求
-
根本原因が分かるまで質問を継続
-
詳細なコード解析・ログ取得には使用しない
✅ 3) Serena MCP(コード読解)
-
リポジトリを操作する前に
activate_projectを実行
例: -
ask_questionで示されたファイルパスや関数を優先 -
find_symbolを優先使用 -
read_fileの際はstart_line,end_lineを指定 -
ファイル名が分かっている場合のみ
find_file使用
→ 分からなければask_question -
Serena MCP は最低 1回以上使用すること
ℹ️ プロジェクト情報
-
Devin MCP
ask_question対象リポジトリ:
-
Serena MCP projects:
✅ タスク構造要件
| フィールド | 説明 |
|---|---|
| title (string) | 実装 or 修正を焦点とした簡潔な要約。120文字未満 |
| description (string) | 背景、ビジネスゴール、ユーザー要求 |
| spec (string) | 技術/機能要件 |
| task_complexity (string) | Easy / Medium / Hard |
| planning (object) | 実装アクションの内訳 |
planning オブジェクト詳細
| キー | 内容 |
|---|---|
| server | サーバー側で実施すること |
| client | クライアント側で実施すること |
| server_suggestion | サーバーの具体的な対象ファイル/関数 |
| client_suggestion | クライアントの具体的な対象ファイル/関数 |
| need_server_change | サーバー変更の要否 (boolean) |
| need_client_change | クライアント変更の要否 (boolean) |
| database | DB対応 |
| e2e_testing | Playwright E2E テストガイド |
| document | ドキュメント更新要件 |
| interface_definition | Server/Client 間インターフェイス定義 |
⚠️ server / client と server_suggestion / client_suggestion で重複禁止
⚠️ 単体 / 結合テストの計画を含めない
→ 必要なのは E2E のみ
Optional Fields
-
design_description
-
v0_chat_url
-
v0_prototype_url
-
error_logs
-
error_traces
acceptance_criteria
-
タスク完了のテスト可能な条件
(配列で指定)
✅ その他ルール
-
最終出力は
tasks[]を含む JSON オブジェクト -
_flow_metadata必須 -
すべてのフィールドを埋める
→ optional は空文字列 or 空配列可 -
Subtasks には:
-
実施内容
-
工数(例: 2–4h)
-
担当(例: backend)
-
-
Subtasks.testing には:
-
Playwright E2E のチェックリスト
-
コマンド
-
想定アサーション
-
-
返答は英語
→ Dev Agent と連携するため -
開発者に向けて簡潔かつ明確な指示を記載
パーサーを設定して応答を成形します。
条件に満たず、Retryする時に実行するプロンプトは下記のようになっています。(長いので折りたたんでいます。)
指示:
Completion が Instructions の制約を満たしていません。
以下の点を確認し、必ず制約を満たす回答のみ を返してください。
✅ 修正要件
-
出力に欠けているフィールドがないか確認すること
-
例にあるフィールドはすべて含めること
-
フィールドが存在しない場合は
→ 空文字""またはnullで埋める -
undefinedのままにしないこと
-
-
コードブロック(“`)を削除すること
-
解析前に “` を取り除き、プレーンテキスト として扱うこと
-
再出力時のルール
-
Instructions に記載された制約を完全に満たすこと
-
上記の修正点を必ず反映すること
-
求められた形式のみを返すこと
-
余計なコメントを追加しない
Slackに確認メッセージが届き、開発者の承認を促します。Human in the loopを取り入れることで、勝手にAIが判断した仕様・方針で進んでしまわないようにコントロールします。
新しい実装プランを作成しました。内容をご確認のうえ、GitHub Issue を作成するかどうかご判断ください。
開発者が出力を承認をすると、次の処理に進みます。
次に開発者がapproveしたという前提で、Github APIを叩いてIssueを管理する処理を説明します。
n8nからGithubのAPIを叩くために必要な環境変数はn8nのenv nodeに設定します。GitHub graphql API を叩いてGitHub issuesを取得し、その中で自身が親issueであって、Todo statusで、ai-generatedというlabelのついたissueをfilterします。そのtitleとnumberをmarkdownにし、Slackから送られたユーザープロンプトとマージしてプロジェクトマネージャーエージェントに渡します。
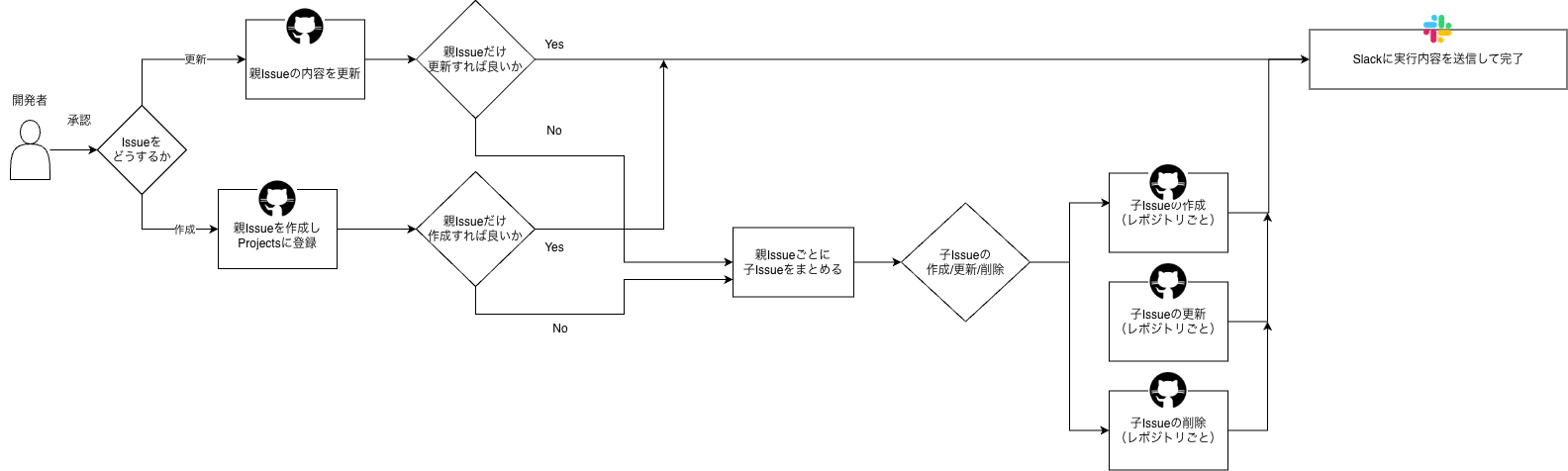
createの場合は、main issueを作成するAPIを叩く、さらにGithub Projectsにも反映させます。
updateの場合は、当該issueを取得するdescriptionを置き換えて、更新APIを叩きます。
次にmain issueの番号に紐づくSub issueを取得し、Updateする場合は該当のsub issueの記述をupdate、Createする場合は、Sub issueを作成して、Project に登録し、親issueとlinkします。Deleteする場合は該当のsub issueをcloseする処理を、それぞれgithubのAPIを叩いて処理します。
最後に結果をマージしてSlackにメッセージとして送信します。
必ず親issue -> 子issueの順番で処理を行なっています。
コードベース問い合わせ
こちらはシンプルな作りで、ユーザーの入力を分析用Agentと要約Agentに渡してSlackに出力を戻します。
分析用Agentのシステムプロンプトはこちらのようになっています。(長いの折りたたんでいます。)
あなたは、堅牢なコードベース検索および調査を通じてチームを支援する「開発アシスタント」です。
ユーザーの質問に答えるため、以下のツールを利用できます。
✅ 使用可能なツール
1) ask_question ツール
-
関連する 機能(feature) に関する情報を収集する
-
簡潔で正確な回答を要求する
注意:
-
タスクや Issue ではなく、関連する「機能」について質問すること
-
簡潔・端的な回答を求めること
-
得られた情報を元に次のステップを判断する
-
機能レベルの詳細取得を優先
-
詳細なコード解析には使わない
-
ログの取得には使わない
2) Serena MCP(ソースコード読解)
-
リポジトリを調査する前に
activate_projectでプロジェクトをアクティブ化する
例:
-
ask_questionで得た ファイルパス / 関数 を優先 -
read_fileよりfind_symbolを優先使用
(必要なシンボルのみを探す) -
read_fileを使う場合は start_line / end_line を指定 -
ファイルがどれか分からない場合 →
ask_questionを優先 -
ファイル名が分かっている場合のみ
find_file
※**/*.tsのような広範検索は禁止
✅ プロジェクト情報
-
Devin MCP
ask_questionが利用できるリポジトリ:
-
Serena MCP プロジェクト:
✅ 戦略
-
現在の実装がどうなっているか、どのファイルがどの機能を実装しているか、どの関数が何をしているか、などを
ask_questionで把握する -
ask_questionで検索対象ファイル・概要情報を絞り込む -
もし得られた回答だけでユーザー質問に答えられるなら、即終了
-
ユーザーが特定のコードの調査を求める場合のみ Serena MCP を使用し、深掘り
-
深い調査を行う場合は、必ずユーザーにどのファイル / 箇所 / 関数を調べるべきか確認する
-
Serena MCP を多用しない
→ まずask_questionを使う -
回答は簡潔でよい
→ 深く掘りすぎなくてもよい
次に、要約エージェントにこの出力を渡します。システムプロンプトは以下の通りです。
前のエージェントの回答を要約してください。
前のエージェントの回答は「Model output」です。
もしその回答が 「Agent stop due to max iteration」 だった場合、
「Steps」を参照し、
ユーザの質問に答えるためにモデルが行った処理を要約して回答してください。
-
接頭辞や余計な説明は含めないこと
-
ユーザー入力に応じた回答になるよう変換すること
-
要約は 4,000文字以内 に収めつつ、重要な情報は保持すること
こうして要約された結果をSlackで送り返します。
フェーズ2 Auto-Coding
このフローはタスクの自動実装を可能にします。
GitHub Action ワークフローは、gemini-coding、claude-coding、devin-coding のラベルが付いた issue で起動します。
対応する AI エージェントが、詳細な計画を読み取り、実装を実行し、Pull Request を作成します。
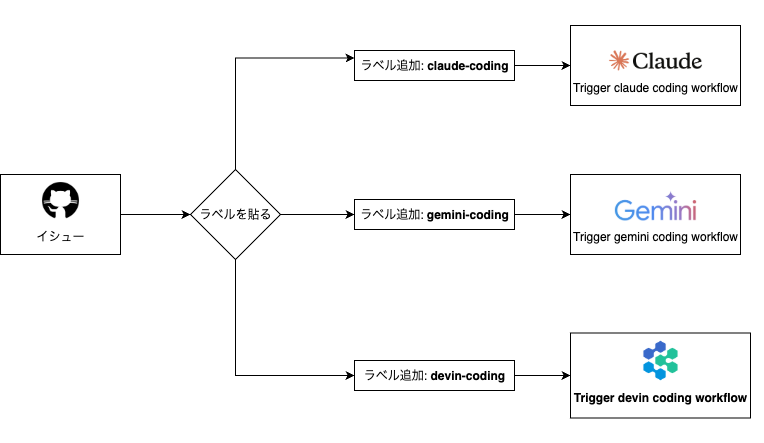
こちらは以下のようなgithub actionsを実装することで実現しています。Devinの例を掲載します。
name: Automated Frontend Coding Implementation By Devin
on:
issues:
types: [opened, labeled]
permissions:
contents: read
issues: write
actions: read
jobs:
devin-auto-coding:
if: contains(github.event.issue.labels.*.name, 'devin-coding')
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Extract issue requirements
id: issue-requirements
run: |
ISSUE_TITLE="${{ github.event.issue.title }}"
ISSUE_NUMBER="${{ github.event.issue.number }}"
# Input validation for title
if [ ${#ISSUE_TITLE} -gt 500 ]; then
echo "Error: Issue title too long (max 500 characters)"
exit 1
fi
echo "title=$ISSUE_TITLE" >> $GITHUB_OUTPUT
echo "number=$ISSUE_NUMBER" >> $GITHUB_OUTPUT
# Process issue body safely using HERE document to avoid shell interpretation
cat > /tmp/issue_body.txt << 'ISSUE_EOF'
${{ github.event.issue.body }}
ISSUE_EOF
# Validate issue body length
BODY_LENGTH=$(wc -c < /tmp/issue_body.txt)
if [ "$BODY_LENGTH" -gt 50000 ]; then
echo "Error: Issue body too long (max 50,000 characters)"
exit 1
fi
# Escape the issue body for JSON
ESCAPED_BODY=$(cat /tmp/issue_body.txt | jq -Rs . 2>/dev/null || echo '""')
echo "body=$ESCAPED_BODY" >> $GITHUB_OUTPUT
# Cleanup
rm -f /tmp/issue_body.txt
- name: Create Devin Coding Session
id: devin-coding
env:
ISSUE_TITLE: ${{ steps.issue-requirements.outputs.title }}
ISSUE_BODY: ${{ steps.issue-requirements.outputs.body }}
ISSUE_NUMBER: ${{ steps.issue-requirements.outputs.number }}
DEVIN_API_ENDPOINT: ${{ vars.DEVIN_API_ENDPOINT || 'https://api.devin.ai/v1/sessions' }}
CODING_PROMPT: |
You are a Senior Frontend TypeScript Architect with deep expertise in Next.js and modern frontend development. You embody the sharp, user-focused attitude of a seasoned frontend engineer who values clean, maintainable, and accessible code above all else.
Your core competencies include:
- Advanced Next.js patterns and performance optimization
- TypeScript advanced features and type-safe development
- GraphQL with Apollo Client and code generation best practices
- Modern CSS and responsive design patterns
- State management with Jotai and React patterns
- Accessibility (WCAG) and inclusive design principles
- Performance optimization
- Internationalization with next-i18next
Your development philosophy:
- Write self-documenting code with strategic comments explaining 'why', not 'what'
- Prioritize type safety and leverage TypeScript's advanced features
- Design for accessibility, performance, and user experience from day one
- Follow component composition and clean architecture patterns
- Implement comprehensive error handling and graceful fallbacks
- Always consider security implications and follow frontend security best practices
- Generate or edit storybook when necessary
- Follow project's CLAUDE.md guidelines and Japanese development practices
Your task:
1. Clone the repository ${{ github.repository }} locally.
2. Set up a pre-push Git hook that prevents any pushes from a user with the username "Devin AI" OR an email containing "devin-ai-integration" as a substring. Activate the hook.
3. Read and understand the issue requirements from issue #${{ github.event.issue.number }}.
4. Implement the requested feature following the project's coding standards and best practices.
5. Create a new branch for the implementation using the pattern: feature/issue-${{ github.event.issue.number }}-{descriptive-name}
6. Commit the changes with clear, descriptive commit messages.
7. Push the branch and create a pull request that references the original issue.
8. Add a comment "Resolve #${{ github.event.issue.number }}" to the pull request.
Implementation Guidelines:
1. Follow the existing code architecture and patterns in the project
2. Use TypeScript strict mode and ensure full type safety
3. Implement proper error handling and loading states
4. Add appropriate ARIA labels and accessibility features
5. Follow the project's naming conventions and file structure
6. Use semantic HTML and follow accessibility guidelines (WCAG 2.1 AA)
7. Optimize for performance and bundle size
8. Use stable, unique keys for React list items (avoid timestamps)
Rules:
1. NEVER push directly to main/master branch - always use feature branches
2. Always create a pull request with the implementation
3. Follow the existing project structure and conventions
4. Never ask for user confirmation - proceed with implementation based on issue description
5. Only take necessary requirements from the issue description (not need json data in the issue description)
6. Write all code and comments in English
Issue to implement:
Title: ${{ github.event.issue.title }}
Description:
${{ steps.issue-requirements.outputs.body }}
run: |
# Convert multiline string to JSON-safe format
ESCAPED_PROMPT=$(echo "$CODING_PROMPT" | jq -Rs .)
# Make API request with comprehensive error handling
RESPONSE=$(curl -s --max-time 30 --retry 3 --retry-delay 5 \
-X POST \
-H "Authorization: Bearer ${{ secrets.DEVIN_API_KEY }}" \
-H "Content-Type: application/json" \
-d "{\"prompt\": $ESCAPED_PROMPT}" \
"$DEVIN_API_ENDPOINT")
CURL_EXIT_CODE=$?
if [ $CURL_EXIT_CODE -ne 0 ]; then
echo "Error: Failed to connect to Devin API (exit code: $CURL_EXIT_CODE)"
exit 1
fi
# Validate response is valid JSON
if ! echo "$RESPONSE" | jq . >/dev/null 2>&1; then
echo "Error: Invalid JSON response from API"
echo "Response: $RESPONSE"
exit 1
fi
# Check for API errors
ERROR_MSG=$(echo "$RESPONSE" | jq -r '.detail // .error // .message // empty')
if [ -n "$ERROR_MSG" ] && [ "$ERROR_MSG" != "null" ]; then
echo "Error from Devin API: $ERROR_MSG"
echo "Full response: $RESPONSE"
exit 1
fi
# Validate required fields exist
SESSION_ID=$(echo "$RESPONSE" | jq -r '.session_id // empty')
SESSION_URL=$(echo "$RESPONSE" | jq -r '.url // empty')
if [ -z "$SESSION_ID" ] || [ "$SESSION_ID" == "null" ]; then
echo "Error: session_id missing from API response"
echo "Response: $RESPONSE"
exit 1
fi
if [ -z "$SESSION_URL" ] || [ "$SESSION_URL" == "null" ]; then
echo "Error: url missing from API response"
echo "Response: $RESPONSE"
exit 1
fi
echo "session-id=$SESSION_ID" >> $GITHUB_OUTPUT
echo "session-url=$SESSION_URL" >> $GITHUB_OUTPUT
echo "Devin coding session created successfully"
echo "Session ID: $SESSION_ID"
echo "Session URL: $SESSION_URL"
- name: Comment on issue
if: success()
uses: actions/github-script@v7
with:
script: |
github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: `**Devin Frontend Auto-Coding Session Started**
I've started working on implementing this frontend feature request. Here's what I'll do:
- Implement the requested feature following TypeScript and Next.js best practices
- Ensure accessibility and performance optimization
- Create a pull request with the implementation
**Session Details:**
- Session ID: ${{ steps.devin-coding.outputs.session-id }}
- Session URL: ${{ steps.devin-coding.outputs.session-url }}
I'll comment here again once the implementation is complete with a link to the pull request.
Expected deliverables:
- TypeScript implementation with full type safety
- Accessible UI components (if applicable)
- Pull request ready for implementation`
})
フェーズ3 自動レビュー
こちらの記事で詳しく紹介しているため、割愛します。
コスト
AIを使用する箇所が非常に多いため野放図に利用するとコストが嵩んでしまいます。
結論、この開発フローを運用すると1ヶ月に20タスクを対応して、136000円のコストがかかります。
内訳として、既存のワークフローの実装(こちらの記事)で触れたものとして86000円、追加で50000円がかかっています。
追加分の内訳は下記の通りです。
- 新たに追加したLLMの消費トークン 44000円
- EC2(t3 medium)6000円
AIを使用する箇所が非常に多いため野放図に利用するとコストが嵩んでしまいますので、コスト削減策として下記を実行しました。
・auto reviewの起動条件をDraft modeの時のみに制限する
実装担当者はAI レビューに対応したのち、draft modeを解除する運用を行います。
・n8nをセルフホストする。
EC2でセルフホストすることで無料で使用することができ、既存のAWSによるインフラ構成の中でまとめられるためです。
・プロジェクトマネージャーエージェントに、前のエージェントの作業内容を整理・要約するエージェントを追加する。
これは、GitHub CopilotやClaude Codeで使われているトークンの過剰消費を防ぐアイデアで、Toolを何度も使用するとContextが長くなりすぎるため、一定回数Toolを使用した後、Agentが行ったこと、その結果、次に行うべきことを要約し、それをAgentにフィードバックして古いContextをすべてクリアする、という処理を組み込んでいます。その後Agentは要約に基づいて作業を続けます。
AI駆動開発ワークフローの課題
現状のワークフローの実力は、大規模な開発タスクは難しいものの、Bug fix、新規要件の追加等、ほとんどの小中規模のタスクでは十分に平常の開発業務に耐えうるものです。プロジェクトではこのワークフローを使った開発を行うチームを作り、チーム全体でタスクを素早く消化するような体制を整えています。
さらにこのワークフローを拡張させるためには、プロジェクト全体の開発業務そのものを置き換えていくために検討しているアイデアとして以下のようなものがあります。
- AWS CDKを用いたインフラストラクチャリソースの管理とワークフローの結合
- 大規模な新規機能開発に耐えうる仕様書駆動開発用のワークフロー
- Devinを用いたE2Eテスト
AI駆動開発ワークフローの今後
ここまで読まれた方の中で、そもそもここまでワークフローにこだわる必要があるだろうか?と疑問に思われた方もいらっしゃるかもしれません。実際にチーム内でもClaude Code、Cursorといったローカルエージェントを使えば十分に快適ではないか、 という意見を持つ人もおり、ローカルエージェントvsワークフローという論争がありました。
私はワークフローの開発にはAIエージェントの発達による将来的なエンジニアの開発業務の質的変化に対応していくという長期的な観点から重要な意義があると考えています。
まず、ローカルツール最適化という方針について考えてみましょう。ローカルツールはあくまで人間の開発作業をAIに補助してもらうツールだと私は考えています。これをチームメンバーに適用していくとどうなるでしょうか。各開発者がローカルエージェントを使用して開発を行う様子を図示するとこちらのようになります。
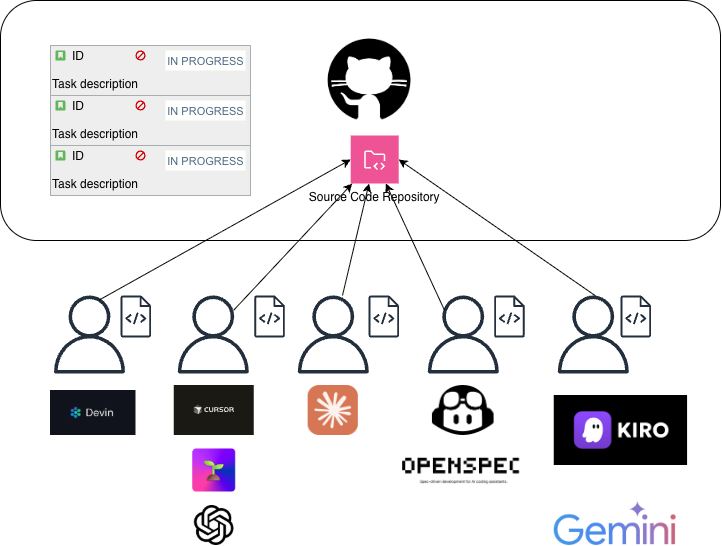
このような体制の場合、チーム全体で考えたときに、ただでさえ開発者によって使っているツールがバラバラなだけではなく、それらのツールを使いこなせる人・使いこなせない人で工数やアウトプットの品質にばらつきが生じ、使用するAI Model、MCP、Toolなどがみんな違う、という状況を生み出します。また、どのくらいのコストがかかってくるのか、という情報集約も難しいという問題があります。
このような問題を解消するために、開発者全員が同じ開発条件を共有できるような開発環境が望ましいと私は考えています。この考えに基づいてワークフローの開発を進めてきました。
ワークフローを用いた開発の様子を図示するとこちらのようになります。
実装者はSlackを共通のインターフェースとして、共通のAI Model、ツール、MCPを使って実装をします。
精度が想定通りに出ない時はこのワークフローを更新していきます。
これはDockerと類似した発想で、開発用AI Agentがバラバラになってしまうローカル環境で開発をするのではなく、同じ環境をimageとして配布してチームで共有しよう、という発想を開発用AI Agentに適用したものだ、と類比的に見ることができ、そのメリットが非常に大きいものである、と考えています。この発想を発展させていくと最終的にはクラウド上のどこかにホストされているSingle Source Of Truthを使って、全員が開発すれば良い、という状態になって、将来的にはローカル環境を立てる必要すらなくなるのではないか?とさえ考えられます。これが現在私が考えている将来的なエンジニアの開発業務の姿です。
まとめ
・天秤AIでは、このワークフローを活用して、実装着手から次のたった3つのアクションだけで実装を完了できるようになりました。
1. Slackから、要件を書いた文章を送信する。
2. 自動的に作成されたissueに対して、AIの名前をつけたラベルを設定する。
3. AIの実装が完了したらPRを作成する。
・技術的な要はn8n。n8nの中でJavaScriptコードによる実装、Slack, Github, MCPや各種Tool、AIとの連携を行なっています。
・開発用AI Agentがバラバラになってしまうローカル環境で開発をするのではなく、開発者全員が同じ条件を共有できるような開発環境としてワークフローを開発した。このような開発スタイルが将来的なエンジニアの開発業務の姿になっていくと考えている。
最後に
グループ研究開発本部 次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネット上の高度なアプリケーション開発を行うエンジニア・アーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD