2026.02.02
DeepSeek Manifold-Constrained Hyper-Connections (mHC) について
こんにちは、グループ研究開発本部・AI研究開発室のA.Zです。
今回は、DeepSeekが2025年末に発表し、新たなアーキテクチャ「Manifold-Constrained Hyper-Connections (mHC)」について解説します。
10年以上もの間、深層学習の根幹を支えてきた「残差接続(Residual Connection)」の限界を突破し、大規模モデルの学習をより安定、かつ高性能にするこの技術。その仕組みを紹介します。
概要
DeepSeekが提案したManifold-Constrained Hyper-Connections (mHC)は、ニューラルネットワークのスケーリング問題を解決する新しいフレームワークです 。
最大の特徴は、27B(270億)パラメータを超えるような超大規模モデルを、わずか6.7%の追加計算コストで安定して学習できる点にあります 。従来の技術では困難だった「信号の爆発」を数学的な制約(多様体への投影)によって抑え込み、推論性能の向上にも成功しています 。
Residual Connection(残差接続)の背景
現在のすべての大規模言語モデルは Residual Connection(残差接続) に依存している。この技術は 2015年の ResNet により導入され、深層学習の発展を根本的に変えた。
残差接続の基本的な考え方は非常にシンプルである。
- 入力を層の出力に直接加算する
- 情報が層を「スキップ」して流れる経路を作る
これにより、学習時に勾配がスムーズに伝播する。勾配消失問題(Gradient Vanishing Problem)解決と学習安定化を可能にします。
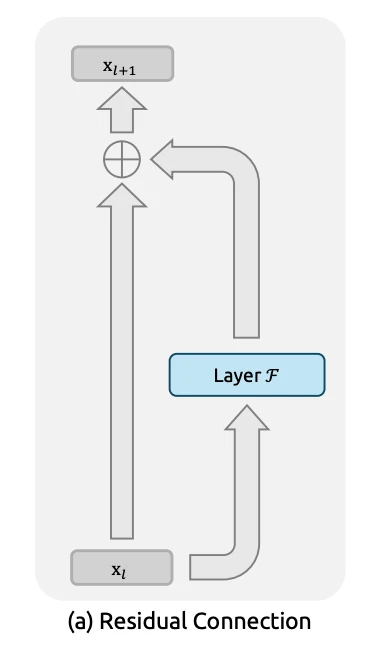
https://arxiv.org/pdf/2512.24880より引用
残差接続の本質:Identity Mapping
残差接続は数式で次のように表されます。
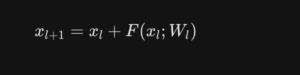
ここで最も重要なのが、入力をそのまま伝えるIdentity Mapping(恒等写像)です 。
- 入力 (x_l) をそのまま次層へ伝える
- 信号強度と勾配ノルムを保存
- 勾配消失・爆発を防止
これにより、ネットワークの深さそのものが不安定性の原因になることを防いでいる。
残差接続のの課題
しかし、この優れた残差接続にも、モデルの巨大化に伴い無視できない限界が見えてきました 。
主な問題・課題としては
剛直性 (Rigidity):
- 残差は 常に重み1.0で加算
- 入力を抑制・強調する学習ができない
- 情報経路が固定され、柔軟なルーティングが不可能。l層とl+1層にしか情報経路存在しない
- 層によって、重要度(weighy)が柔軟に調整ができない
幅 (Width) のボトルネック:
- Residual Stream の幅 = Attention / FFN の次元
- Residual Streamは複数層に順番に処理され、最後の層まで情報を伝える。
- 層の次元と同じになっているため、AttentionやFFNの次元を増やすと、Residual Streamの幅も増える。
- メモリ容量を増やすには計算コストも増加
- 層が深いと、この全ての層に学習したシグナルを保持するため、メモリ容量を増やさなければならない。
- メモリ容量を増やすと、層の全体の容量も増加必要になり、計算量・コストも増加する。
混合 (Mixing) のボトルネック:
- 残差は単なる「搬送路」
- ロジック自体はただ、ある層からの情報を次の層へ搬送するだけで、n前の層と連動したり、することができない
- Residual Stream 内で情報が混ざらない
- Residual Streamは完全に一つ前の層と依存するため、内部的に複数層の情報が混ざらない
Hyper-Connections (HC)
これらの限界を打破するために提案されたのが Hyper-Connections (HC) です 。
https://arxiv.org/abs/2409.19606
基本アイデア
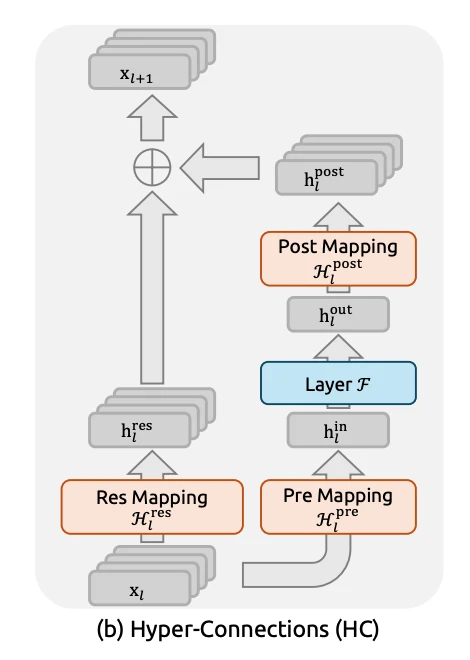
https://arxiv.org/pdf/2512.24880より引用
| 要素 | 役割 |
|---|---|
| Hpre | 広いResidual Streamから計算層への入力を読み出す |
| Hpost | 計算結果を再びResidual Streamへ書き戻す |
| Hres | Residual Stream内での情報の混合を行う |

主な改善効果またはポイント
- 仮に層の次元はC、n倍に拡張したい場合は、通常の残差接続では、計算メモリはnC x nC(n^2C^2) となります。一方、HCでは、一回の計算で必要なメモリはnC x C(nC^2)となり、メモリ容量を削減できます。
- Hresは残差接続と同様に、Residual Stream内での情報の混合を行う役割を果たし、より柔軟な情報経路を可能にします。
これにより、計算コストを抑えつつ「作業メモリ」を拡張でき、収束速度も1.8倍に向上しました 。
https://arxiv.org/abs/2409.19606より引用
HCのスケール不安定性問題
しかし、従来のHCには大規模化すると破綻するという致命的な欠陥がありました 。 Hresが自由に学習される、大規模のLLMの学習(27B parameter)時、信号が3000倍に爆発してしまったことが報告されました。これにより、学習が崩壊(Catastrophic Divergence)を引き起こしました 。
Manifold-Constrained Hyper-Connections (mHC)
この爆発問題を解決したのが、DeepSeekの真骨頂である mHC(Manifold-Constrained Hyper-Connections) です 。
https://arxiv.org/pdf/2512.24880
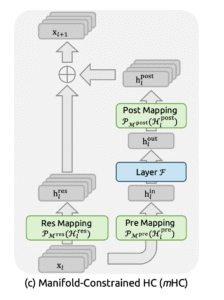
https://arxiv.org/pdf/2512.24880より引用
多様体制約による解決
mHCは、 をBirkhoff Polytope(ビルコフ多胞体)という数学的な多様体の上に制約します 。具体的に、学習時、自由度が非常に高い部分は、Sinkhorn-Knopp アルゴリズムを適用することで、この制約を維持します 。
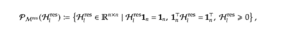
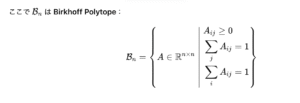
これは「二重確率行列(Doubly Stochastic Matrix)」と呼ばれ、行と列の和がすべて1になる行列です 。この制約下では、信号は「凸結合」として混合されるため、理論的に増幅が起こりません 。
学習中には、Sinkhorn-Knopp アルゴリズムを適用することで、この制約を維持します 。
効果または成果
この数学的アプローチにより、信号の増幅は以下のように劇的に抑制されました 。
| MODEL | BASELINE | HC (従来) | mHC (今回) |
|---|---|---|---|
| 3B signal gain | 1.2x | 48x | 1.5x |
| 9B signal gain | 1.3x | 287x | 1.6x |
| 27B signal gain | 1.4x | 3012x | 1.6x |
HCで3000倍以上に爆発していた信号が、mHCではわずか1.6倍程度に安定して制御されています 。
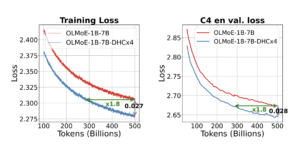
また、モデル性能関連の指標も、改善効果を示しています 。

https://arxiv.org/pdf/2512.24880より引用
Baselineに比べて、計算量が多ければ多いほど、安定的に、lossが約1.5%改善される。LLMの学習において、計算量を抑えつつ安定的に学習を続けることが可能になり、更に性能も改善される見込みです。
まとめ
DeepSeekのmHCは、計算量を抑えつつ大規模モデルの学習を安定させる、非常にエレガントな解決策です。このアーキテクチャが単なる安定化だけでなく、モデルの知能そのものを底上げすることを示唆しています。 DeepSeekの最新モデルはまだリリースされていないが、実際にこちらの手法が採用されたら、どんなモデルが生まれるか興味深いですね。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。 ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。 皆さんのご応募をお待ちしています。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD






