2026.04.06
Claude Code 基本機能を使い倒して開発工程をもう1歩自動化する
はじめに
こんにちは。次世代ベトナム研究室のK.X.Dです。
AIエージェントによるコーディング支援は急速に普及しています。しかし「AIに開発を任せる」と一口に言っても、実際にはプロンプトの書き方ひとつで結果が大きく変わり、セッションが変わればそれまでの指示もリセットされてしまいます。単発のコード生成ではなく、要件分析から設計・実装・テスト・コードレビュー・ドキュメント更新・Git操作までの開発工程全体をAIで自動化するには、もう一段階の工夫が必要です。
本記事では、Anthropic社が提供するターミナルベースのAI開発エージェント「Claude Code」の基本機能に焦点を当て、外部フレームワークに頼らずに開発工程をどこまで自動化できるかを検証した実践記録をお届けします。対象読者はClaude Codeをすでに使っている方はもちろん、AIエージェントを活用した開発自動化に興味があるエンジニア全般を想定しています。
1. 概要:この記事で扱うこと
本記事の全体像を先にお伝えします。
まず導入として、開発工程の自動化を取り巻く現状と、小規模チームが直面する「フレームワークが重すぎる」という課題を整理します。その上で、Claude Codeの基本機能だけで開発ワークフローを構築するための4原則を提示します。
次に実践編として、要件整理からGit操作までをカバーする8ステップのワークフローを解説し、そのワークフローを実運用する中で直面した3つの課題と、それぞれに対する施策を詳しく紹介します。
| 課題 | 施策 | キーとなるClaude Code機能 |
|---|---|---|
| 大きなタスクを任せると品質が落ちる | 施策1:複数エージェントオーケストレーター | Agent Teams + Sub Agents |
| 何度教えても同じミスを繰り返す | 施策2:経験則自動メモリ | Hooks + Memory + Skills |
| トークンコストが膨らみすぎる | 施策3:ドキュメント自動メンテナンス | Skills + Hooks |
最後に、これらの施策を組み込んだ開発環境の最終構成(Agent定義8種、Skill定義21種、カスタムHook4種)と、今後の展望をまとめます。
2. 背景:外部フレームワークの「重さ」という課題
小規模案件にとって、フレームワークの導入コストが自動化のメリットを上回ることがあります。
私たちが日常的に行う開発作業は、大きく7つの工程に分かれます。要件分析、設計、既存コードの調査、実装、コードレビュー、検証、ソースコード管理です。これらをAIエージェントに任せるためのツールセットとして、GitHub上には「Everything Claude Code」「Awesome Claude Code」「BMAD Method」「SpecKit」といったフレームワークが公開されています。
ただし、実際に使ってみるとわかるのですが、とにかく機能の分量が多い。2〜3人で回す小規模案件には重厚すぎて、フレームワーク自体の理解と設定に時間がかかります。
一方で、Claude Code自体が持つ基本機能を改めて整理してみると、ワークフロー自動化に必要な要素が一通り揃っていることに気づきます。
| 基本機能 | 役割 | 開発工程での使いどころ |
|---|---|---|
| Skills | 作業手順の定義 | 調査・計画・実装・レビューなど各工程の手順書 |
| Rules | 開発ルールの注入 | コーディング規約、命名規則、アーキテクチャ制約 |
| Hooks | ライフサイクルへの自動処理の挿入 | セッション開始時のルール注入、編集後の品質チェック |
| Sub Agents | 独立コンテキストでのバックグラウンド処理 | 専門ロール(テスター、レビュアーなど)の分離 |
| Agent Teams | 並列マルチインスタンスの起動 | 複数画面の同時実装、多角的な調査 |
| Memory | セッション間の知識引き継ぎ | プロジェクト固有のルールや過去の判断の永続化 |
今回のゴールは、外部フレームワークを最小限に抑え、これらの基本機能を使い倒して開発全工程を自動化することです。対象は小規模案件。プロンプトの一部は既存フレームワークから参考にしつつも、全体として軽量に仕上げるアプローチを取ります。
3. 設計思想:ハーネスエンジニアリングとは
AIを「賢い単体モデル」として扱うのではなく、その周囲の仕組みごと設計する考え方です。
今回のバックボーンとなっている設計思想は「ハーネスエンジニアリング」です。LLMの周囲にあるコンテキスト供給、ツール、制約、検証、修復まで含めて、安定して成果を出すワークフローを運用する考え方です。モデルの性能だけに頼るのではなく、「AIが間違えにくい環境をつくる」ことに重点を置きます。
これをClaude Codeの基本機能で実現するとどうなるか。実践を通じて、4つの原則が見えてきました。
AIに適切に開発させる4原則
| # | 原則 | Claude Code機能 | 具体的な意味 |
|---|---|---|---|
| 1 | コンテキストを適切に分割する | Agent Teams | 1セッションのコンテキストを大きくしない。タスクごとにセッションを分ける |
| 2 | ロールを明示的に決める | Sub Agent | 「テスター」「レビュアー」「ドキュメント管理者」など、タスクに対応する役割を定義する |
| 3 | タスク対応を手順化する | Skill | 「計画を立てるときはこの手順で」「レビューではこの観点をチェック」といった作業手順を定義する |
| 4 | 実装ルールをコンテキストに入れる | Rules + Hook | コーディング規約やアーキテクチャ制約を、セッション開始時に自動で注入する |
重要なのは、この4原則がClaude Code公式のベストプラクティスそのものであるという点です。特別なフレームワークを導入しなくても、基本機能を正しく使うことが、AI開発の設計指針になります。
4. ワークフロー全体像:8ステップの開発フロー
いきなり実装に入らず、計画から順に開発工程を進行する点が重要です。
具体例として、「ユーザー認証を追加してほしい」という依頼が来たケースで全体像を見てみます。
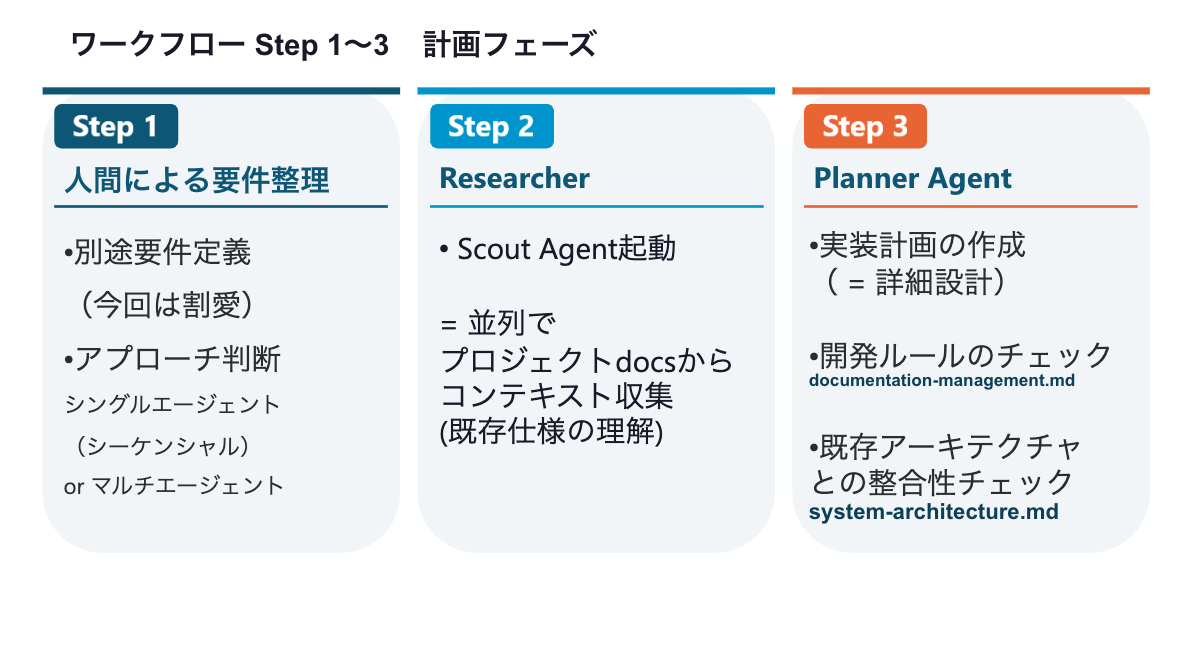
計画フェーズ(Step 1〜3)
Step 1:人間による要件整理では、まず「アプローチ判断」を行います。シーケンシャルなシングルエージェントで進めるか、マルチエージェントで並列に進めるかの選択です。「ユーザー認証の追加」のように独立した機能であれば、シングルエージェントのシンプルなフローを選択します。なお、仕様要件は事前に別のワークフローで整備済みであることが前提です。
Step 2:Researcher Agentが動きます。Scoutスキルを使って、並列でプロジェクトのdocsから開発に必要な情報を取得します。既存の仕様ドキュメントを読み込み、コンテキストとして入力する段階です。
Step 3:Planner Agentが実装計画(詳細設計)を作成します。このとき、開発ルールが定義されたdocumentation-management.mdを確認し、既存アーキテクチャのsystem-architecture.mdを参照して全体との整合性をチェックした上で計画を立てます。
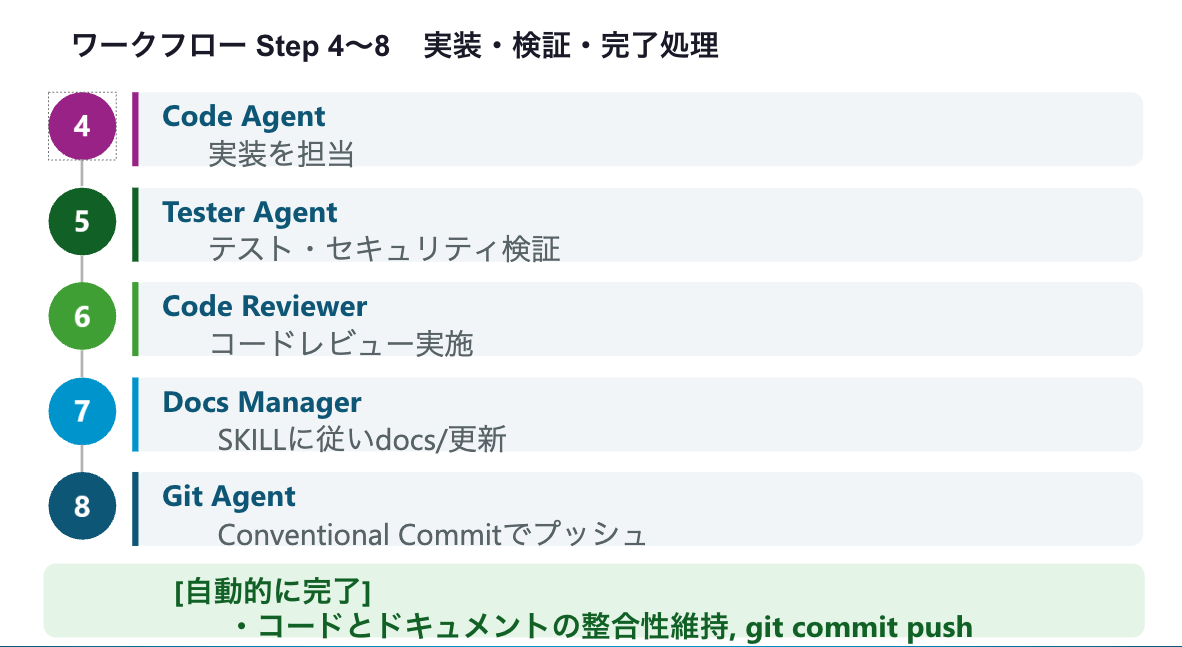
実装・検証フェーズ(Step 4〜6)
Step 4:Code Agentが実装を担当します。Planner Agentが作った計画に沿ってコードを書き進めます。
Step 5:Tester Agentがテストとセキュリティ検証を行います。実装されたコードに対して自動テストを実行し、セキュリティ上の問題がないかも確認します。
Step 6:Code Reviewer Agentがコードレビューを実施します。コーディング規約への準拠、ロジックの妥当性、パフォーマンスの観点からレビューします。
完了処理(Step 7〜8)
Step 7:Docs Manager AgentがSkillに従ってdocs/を更新します。コードと仕様ドキュメントの整合性をここで維持します。
Step 8:Git AgentがConventional Commitの形式でコミットを作成し、変更をプッシュします。
各ステップには承認ゲートが設けられており、人間が品質をコントロールできるバランスを保っています。

5. 実際に発生した3つの課題
ワークフローを回してみると、3つの課題が浮き彫りになりました。
このワークフローで実際に開発を進めてみたところ、以下の問題に直面しました。
課題1:大きなタスクを任せられない。 画面数が多い機能や複雑なビジネスロジックをまとめてAIに任せると、個々の画面設計が薄くなり、エッジケースが漏れやすくなります。さらにコンテキストが膨らむため、処理速度も低下します。
課題2:何度教えても細かいミスが治らない。 「DBのトランザクションを使わないで」「Selectクエリに論理削除の条件(delete_flg = 0)をつけないで」——こうしたプロジェクト固有のルールは一度教えれば理解してくれますが、セッションが変わると同じミスを繰り返します。
課題3:トークンが非常に多くかかる。 タスクが大きくなるほどコンテキストが膨らみ、トークン消費量が爆発的に増えます。自動化の範囲が広がるほどコスト面で無視できない問題になります。
以下では、この3つの課題に対して実装した施策を詳しく解説します。
施策1:複数エージェントオーケストレーターで大規模タスクを自動分解する
大きなタスクをそのまま投げると品質が下がる問題を、AI自身によるタスク分割と並列実行で解決します。
課題の具体例:プロフィール全8画面の実装
たとえば、プロフィール機能の開発で8つの画面(2FA、パスワード変更、プロフィール編集、設定、通知設定、セキュリティ、アカウント削除、および共通基盤)を実装する必要があるケースを考えます。
これを「全部作って」とClaude Codeに丸投げすると、2つの問題が起きます。まず、AIが一度に多くの画面を処理しようとするため、個別のエッジケースが漏れます。2FAのタイムアウト処理やパスワード変更時のバリデーションなど、本来しっかり考えるべき部分が抜け落ちがちです。次に、単純に時間がかかります。コンテキストが膨らみ、途中で方向を見失うこともあります。
Claude Codeは小さく区切ったタスクでは非常に優秀ですが、大きなタスクをそのまま投げると品質も速度も落ちてしまうのです。
解決策:Agent Teams + Sub Agentsの2層構成
解決策は、Claude CodeのAgent TeamsとSub Agentsを組み合わせた複数エージェントオーケストレーターです。
アプローチはシンプルです。大きな実装はAI自身にタスク分割を作成させ、依存関係をAgent Teamで管理します。分割後の小さな実装は、Sub AgentのImplement Orchestratorに委任して進めます。
Claude Code公式のAgent Teamsベストプラクティスに沿って、5つの原則を守るよう設計しています。
- 各エージェントへ十分なコンテキストを与える — spawn promptsにタスク固有の詳細を含めます。省略すると品質が大きく低下します。
- タスクを適切に分割する — 1エージェントあたり5〜6タスクで生産性を維持します。多すぎるとコンテキストが溢れます。
- チームメイトのタスク完了を待つ — 依存関係がある場合、先行タスクの完了を確認してから後続に入ります。
- ファイル競合を避ける — 同一ファイルを複数エージェントが編集すると上書きリスクがあるため、ファイル所有権を明確に分離します。
- 監視と誘導 — 進捗を確認し、必要に応じてアプローチを修正します。
5つのAgent Teamテンプレート
マルチエージェントが効果的に機能するために、タスクの種類に応じた5つのテンプレートを用意しました。
① research(並列リサーチ) 複数のエージェントが異なる角度で同時に調査し、リーダーが統合レポートを作成します。たとえばセキュリティ視点とUX視点で同時にアーキテクチャ調査を行うようなケースに適しています。
② implement-orchestrator(並列実装) 共有ワークスペースでの並列実装です。プランを分割し、ファイル所有権を分けて並列に実装します。完了後にテスターを起動し、ドキュメントを同期します。日常の開発で最も使用頻度が高いテンプレートです。
③ independent-impl(独立実装) 各エージェントがgit worktreeで独立したワークスペースを持ち、それぞれがPRを作成します。implement-orchestratorと異なり、ファイル競合のリスクを根本から排除できます。大規模な機能追加で依存関係が少ない場合に有効です。
④ review(並列レビュー) セキュリティ、パフォーマンス、テストカバレッジなど異なる観点で同時にコードレビューを行います。1人のレビュアーでは見落としがちな問題を、多角的に検出できます。
⑤ debug(競合仮説デバッグ) 複雑なバグ調査で、複数のエージェントがそれぞれ仮説を立て、互いの仮説を反証しながら根本原因を特定します。「たぶんここが原因だろう」という思い込みを排除できる点が強みです。
実践結果:8画面を30分で全自動実装
プロフィール全8画面の実装にAgent Team Orchestratorを適用した結果です。
メインのエージェントがタスクを分割し、各チームメイトがそれぞれの画面を独立して実装しました。関連画面の塊にはClaude Codeが1セッション分の集中力を注げるため、エッジケースもしっかり処理されます。
成果①:実装品質の安定化。 各エージェントが小さいタスクに集中するため、個々の画面の設計精度が向上しました。
成果②:高速化。 8画面の実装が並行処理で約30分で完了し、5つのプルリクエストが全自動で作成されました。
Screenshot
施策2:経験則自動メモリでセッション間の学習を実現する
「何度教えても同じミスを繰り返す」問題を、Hookベースの自動学習機構で解決します。
課題の本質:セッション間の知識断絶
Claude Codeを使っていると、人間のペアプロ相手なら一度言えば済むことを、セッションが変わるたびに繰り返し伝える必要があります。コンテキストがリセットされるため、プロジェクト固有のルールが毎回失われてしまうのです。これはストレスであると同時に、生産性の大きなロスです。
解決策:常時稼働する2つの監視Hook
この問題に対して、セッション中の学習機会を自動的に監視する2つのHookを実装しました。論文やOSSをヒントにして作成した仕組みです。
Hook①:memory-save-detector(訂正・承認シグナルの検出)
ユーザーの発言から4つのパターンを検出し、知識として永続化します。
修正指示の検出: 「違う」「やめて」「するな」といった否定語や、「じゃなくて」「代わりに」「にして」といった指示語を検出します。たとえば「データベースに直接クエリしないで、Transactionを使ってください」という指示があった場合、これは既存の開発ルールに追加される形でRules化されます。以降のセッションでは、この指示が自動的にコンテキストに注入されます。
承認の検出: 「完璧」「その通り」「いいね」といった承認語を検出し、Memoryに保存します。「この書き方でいいんだ」という成功パターンを記録するためです。
外部参照の検出: LinearやJira、Slack、Grafanaといった外部システム名と、「のXXXプロジェクト」「channel “xxx”」「URL」のようなロケータをセットで検出し、Memoryに記録します。プロジェクトの外部ツール連携情報を蓄積するためです。
ユーザー情報の検出: 「私は」「僕が」といった自己参照を検出し、Memoryに保存します。開発者の役割や担当領域を覚えることで、より適切なレスポンスが可能になります。
Hook②:skill-create-on-miss(繰り返しパターンの検出)
同じツール操作の繰り返しを検出し、「スキル化すべき」と判断して再利用可能なSkillへの昇格を提案します。
新規スキルの検出条件: 3〜5のツール列が2回以上繰り返されると繰り返しパターンとして検知し、6ツール目以降から昇格対象になります。また、類似トピックのWebSearchやWebFetchが2回以上続くと調査ループとして検知し、3回目の検索から昇格対象になります。
既存スキルの改善検出: スキルの使用回数が5回以上で、かつ成功率が60%未満、さらに前回の改善から30分以上経過していれば、改善候補として検出します。
学習から昇格までの6ステップ
経験則の自動保存は、以下の6ステップで機能します。
Step 1: 行動観察 — Hookがセッション中の全操作を監視 Step 2: データ蓄積 — 観察データを保存 Step 3: パターン抽出 — セッション終了時にパターンを分析 Step 4: 経験則保存 — パターンを経験則として記録 Step 5: 昇格判定 — 3つの条件で昇格可否を判定 Step 6: 自動適用 — 次セッションでSkill/Rulesとして読み込み
昇格の判定条件は3つあります。
- 失敗パターンが3回以上観測されると、経験則データが生成されます
- ユーザー指示パターンが検出されると、ルールが生成されます
- 信頼度スコアリングにより、ノイズを排除し品質を保証します
実践で自動生成されたスキルの例
例1:CloudFront知識のスキル化。 WebSearchで「CloudFront JWT RS256 signature verification」を繰り返し調査していたケースでは、CloudFrontに関する知識がSkillとして自動保存されました。次回セッション以降、同様の調査をゼロから行う必要がなくなりました。
例2:ユーザー質問パターンのスキル化。 AskUserQuestionで「公開スライドのビューアアクセスについて」とAIが毎回ユーザーに質問していたケースでは、その知識をSkillに埋め込むことで、次回から自動判断が可能になりました。Claude Codeが判断できず毎回聞いてしまっていた情報を、一度埋め込めば解決です。
例3:WebSearchレポートの自動生成スキル。 開発中に外部ライブラリの仕様を調べたり、ベストプラクティスを検索してレポートにまとめたりする作業を繰り返していたところ、skill-create-on-missがパターンを検出。「Web検索 → 情報の整理 → レポート作成」の一連の流れが1つのスキルとしてパッケージ化されました。以降は「レポート作って」の一言で同じ品質の成果物が自動生成されます。
学習の成果:2つの資産の蓄積
この仕組みによって、2種類の資産が自律的に蓄積されていきます。ルール・メモリは知見を長期記憶として蓄積するもので、スキルは学習した行動パターンとして定着するものです。使うほどエージェントが成長し、セッション間で同じミスを繰り返さない自動学習機構が実現しました。
施策3:ドキュメント自動メンテナンスでトークンコストを削減する
コンテキスト収集段階でAIが仕様を探し回る問題を、ドキュメント管理の最適化で防ぎます。
課題の根幹:実装前の調査コスト
ワークフローを自動化するとトークンコストが跳ね上がる原因を調べたところ、問題の根幹は実装前のコンテキスト収集段階にありました。AIが関連仕様を探し回ることで、大量のトークンを消費していたのです。
解決策①:Scout Skillでコンテキスト収集を最適化
Claude Code公式ドキュメントにあるMemoryのIndex構造をヒントに、コンテキスト収集そのものを最適化するScout Skillを作成しました。
Scout Skillは、ワークフローの初期ステップで強制的に呼び出されます。並列でプロジェクトのdocsから必要な仕様ドキュメントを収集し、後続の工程に渡します。ポイントは、コンテキスト収集をワークフロー初期で強制的に行わせることです。これにより、その後の実装・テスト・レビュー工程での余計な再調査がなくなり、トークン削減に直結します。
タスク種別に応じて必要なDocsだけを読むアプローチが最も効率的であることも、実践を通じて確認できました。
解決策②:Docs Manager Agentによる自動分割
ドキュメントが大きくなりすぎると、それ自体が無駄なトークン消費の原因になります。そこで、ドキュメントを自動的にメンテナンスするDocs Manager Agentを実装しました。
仕組みはシンプルです。各ドキュメントが800行を超過した場合にHookが検知し、Docs Manager Agentが自動で分割します。分割後は、リンク集(Index)に再構成されます。
たとえば、system-architecture.mdが1,200行に膨らんだ場合、認証・DB・API・インフラなどの関心事ごとに分割され、元ファイルは各分割ドキュメントへのリンク集になります。AIは必要な部分だけを読めばよくなるため、無関係な情報に惑わされることがなくなります。
この施策による効果は2つあります。
コンテキストエンジニアリングの改善: AIが常に最適なサイズの情報のみを参照できるようになり、不要な情報によるハルシネーションが減少しました。
消費トークンの削減: 必要な仕様のみを読み込む構造にしたことで、無駄なトークン消費が大幅に減りました。
4. 開発環境の最終形態
Agent定義8種、Skill定義21種、全ライフサイクルをカバーするHook構成が最終形態です。
3つの施策を組み込んだ.claude/ディレクトリの構成をまとめます。
Agent定義(8種)
architecture、researcher、planner、developer、code-reviewer、tester、code-simplifier、git-manager の8つのエージェントが、それぞれの専門領域を担当します。
Skill定義(21種)
plan、scout、code-review、debug、research、impl-orchestrator、agent-team-orchestration など、11のメインスキルと10の補助スキルを備えています。
カスタムHook(4種)
| タイミング | Hook名 | 機能 |
|---|---|---|
| SessionStart | session-init.cjs |
プロジェクトルールの注入、タスク種別検出、Git情報の取得 |
| UserPromptSubmit | dev-rules-reminder.cjs |
セッション情報、モジュール化ルール、品質ガイドラインの注入 |
| PreToolUse | descriptive-name.cjs |
ファイル命名規則のガイダンス注入 |
| PostToolUse | post-edit-simplify.cjs |
同一ファイル5回修正を検知してcode-simplifierを自動起動 |
SessionStartからSessionEndまで、全ライフサイクルをカバーする構成です。
まとめ
Claude Codeの基本機能を使い倒すことで、小規模案件の開発工程自動化は高いレベルで実現可能です。
改めて4原則と3施策を整理します。
4原則:
- コンテキスト分割 → Agent Teamsで分担
- ロール明示 → Sub Agentの役割定義
- 手順化 → Skill定義
- ルール注入 → Rules + Hook
3つの施策:
- 施策1:複数エージェントオーケストレーター — 大規模タスクを自動分解し、8画面の実装を30分で完了
- 施策2:経験則自動メモリ — セッション間の学習を自動化し、同じミスの繰り返しを防止
- 施策3:ドキュメント自動メンテナンス — トークンコストを3〜10分の1に削減
1つ1つの改善は、Skill・Hook・Ruleなど基本機能の作り込みで実現できています。これが今回の最も重要な成果です。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD