2026.04.20
Claude Code をローカルLLM(Gemma 4、Qwen 3.6、Bonsai 8B)で動かしてみた
TL;DR
- Gemma4、Qwen3.6、(Ternary) Bonsai 8Bという最近発表されたオープンウェイトモデルを利用して、Claude Codeをローカル環境で動かしてみました。ローカルLLMでClaude Codeを実行できればセキュリティーやプライバシーの面で安心ですし、コストも抑えられる可能性があります。
ollamaやLM Studioを利用すれば簡単にローカルLLMでClaude Codeを動かすことができます。十分なGPUメモリのあるデスクトップPCであればGemma4 (26B-A3B)やQwen3.6 (35B-A3B) が動作しますが、速度・精度に関してはやはり元のClaude Codeの性能には及びません。ラップトップPCでもローカルClaude Codeの実行は可能ですが、Bonsai 8Bのような小型軽量モデルでは、そもそもClaude Codeを動かすには性能的に厳しいです。- ローカルLLMでAIエージェントツールを動かしたい、というのであれば、無理にClaude Codeを動かすよりも、OpenCodeのような、より軽量なツールを利用した方が良さそうです。ラップトップPCでも、Gemma4 E4Bを利用してOpenCodeを動かすことができました。
はじめに
こんにちは、グループ研究開発本部のAI研究開発室のT.I.です。さて、Claude Code(Cowork)が、コーディングだけではなく、様々なタスクに応用して活用されるようになってきました。文章の要約や資料整理など、創意工夫で応用の幅は広がっていると思います。しかし、ここで問題なのですが、Claudeはクラウド上のサービスであるため、ネットワークのトラブルやサービスの障害などで利用できないことがあります。生殺与奪の権をクラウドに握られているのは、なかなかに不安なものがあります。そこで、今回、Claude CodeをローカルLLMを使って動かしてみました。
ローカルLLMを利用することで、クラウドへの依存を減らす他に以下の利点があります。
- プライバシーとセキュリティの向上:入力がクラウドサーバーに送信されないため、社内の機密情報や個人情報を含むデータも安心して扱える(はずですが、エージェントの挙動により思わぬリスクがあるかもしれません)
- コストの削減:APIの利用料金が発生しないため、大量のトークンを消費するような長時間の作業でもコストを気にせず利用可能
- オフライン利用:インターネット接続のない環境や、ネットワークが不安定な環境でも利用可能
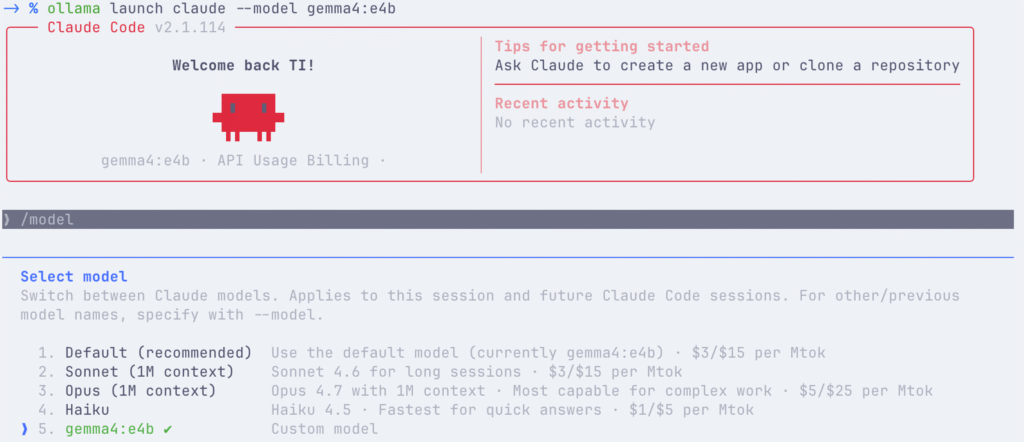
AIエージェントツールは様々なものが開発・公開されております。また、Claude Codeのコード流出事件を受けて、Claude Codeのオープンソース実装がいくつか公開されております。しかし、色々とグレーゾーンな部分もあり、セキュリティ的にも不安があります。最初から使い慣れたClaude CodeをローカルLLMで動かせれば、それに越したことはないですね。難しそうに思われますが、実は非常に簡単です。Ollamaをインストールしたならば、以下のコマンドを実行するだけで、ローカルLLM(例 Gemma4 (E4B)) でClaude Codeが動かせます。
$ ollama launch claude --model gemma4:e4b
また、LM Studioなどを使っている場合は、ANTHROPIC_BASE_URLを設定すれば良いだけです。(参考 Claude Code Docs – LLM Gateway)
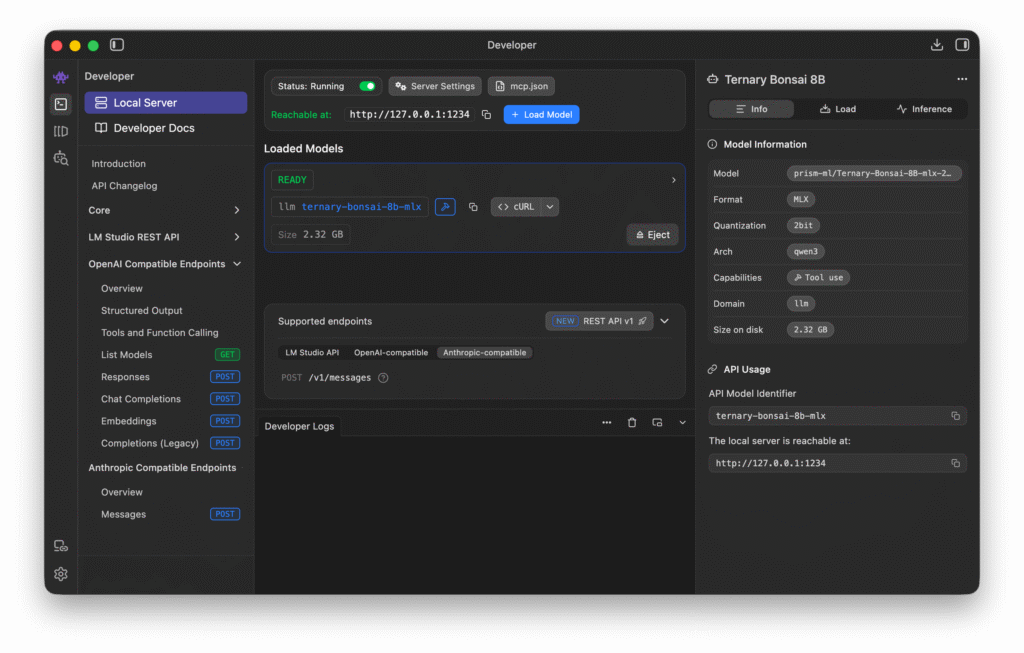
$ export ANTHROPIC_BASE_URL=http://127.0.0.1:1234 $ claude
この場合、モデル名の表示は正しくないですが、ローカルLLMを使用することができます。なお、注意としてモデルをロードする際に、十分な長さのコンテキストウィンドウを確保する必要があります。
Claude CodeをローカルデスクトップPCで使ってみる
はじめにで、今回のブログの目的はほぼ達成しているのですが、実際にローカルデスクトップPCで、どの程度実用的なのかを実験してみます。GPUとして、NVIDIA GeForce RTX 4090を搭載したPCを利用します。
Gemma 4
まずは、Gemma 4で動かしてみます。Gemma 4は、Googleが4月2日にリリースしたオープンウェイトのモデルです(参考:Gemma 4: Byte for byte, the most capable open models)。
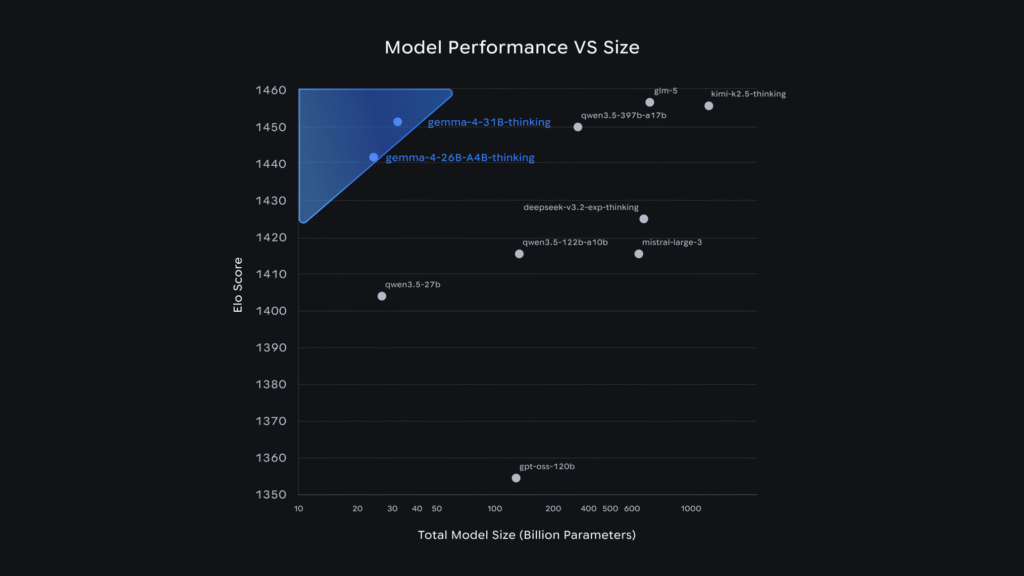
Gemma 4は、31B, 26B A4B, E4B, E2Bの4種類のモデルが公開されています。31Bはデンスなモデルですが、26B A4Bは、MoEを利用してアクティブなパラメータが3.8B級の効率的なモデルです。性能も、31Bに匹敵するレベルとなっています。E2BとE4Bは、小型でモバイル端末などでも利用可能なモデルとなっています。
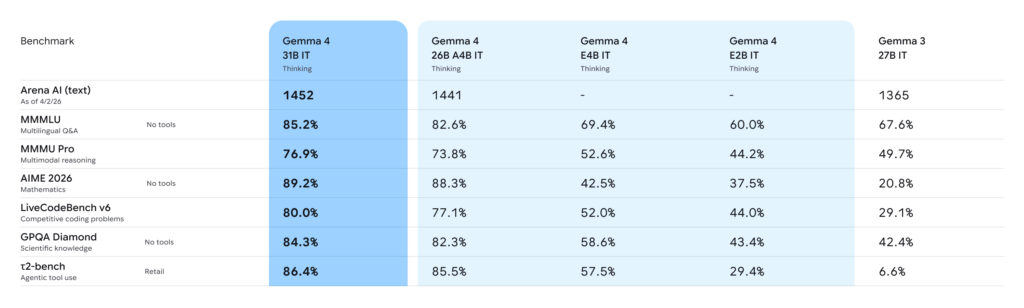
今回の実験では、Gemma 4 26B A4Bモデルを利用してみます。Ollamaを利用してのClaude Codeの起動は、以下の通りです。
$ ollama launch claude --model gemma4:26b
試しに、uvを利用して、データ分析環境を構築し、Palmer Penguinsのデータセットを分析してもらいました。実行速度としてはオリジナルのClaude Codeと比べると、ローカルなのでやや遅い印象ですが、環境構築などの基本的なCLI操作の提案などは、ある程度スムーズに進み実行できます。試しにHTML形式のレポートを作成してもらった結果が以下になります。
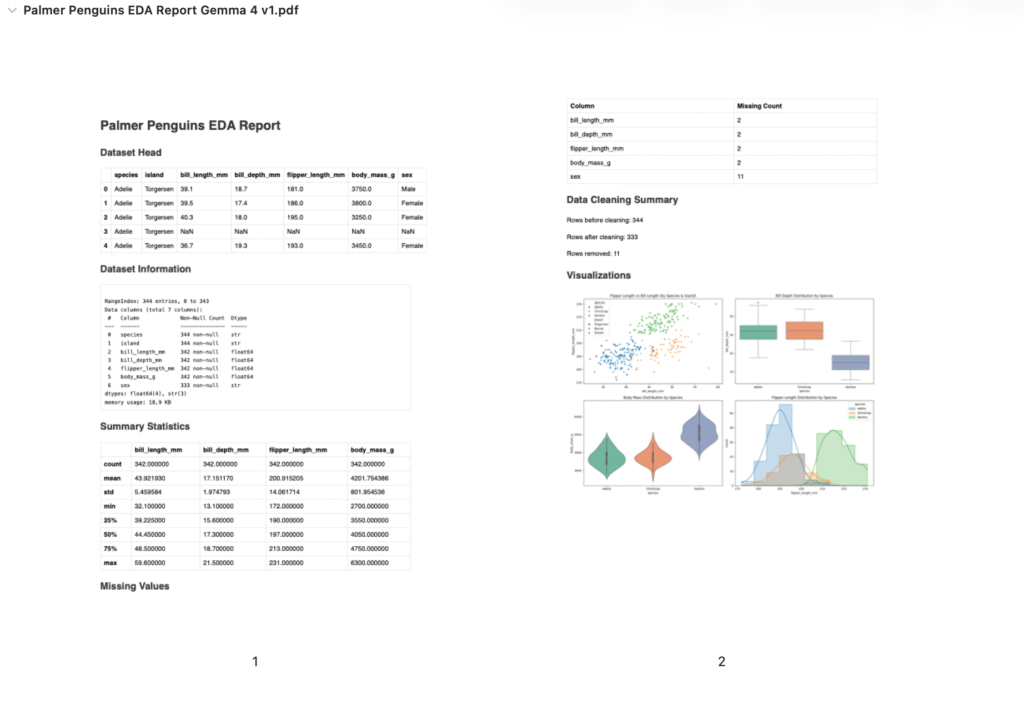
随分と内容に乏しいのが残念ですが、これは指示が不足している点もあるので、こちらからフィードバックを踏まえての改善が必要そうです。ちなみに、Claudeをバックエンドとして利用した場合では、曖昧な指示でも以下のようにGemma 4と比べると長大なレポートを作成してくれました。

Screenshot
分析の質・内容としては、Gemma 4とどんぐりの背比べですが、分量と見せ方に関しては、Claudeをバックエンドにした方が圧倒的でした。
Qwen 3.6-35B-A3B
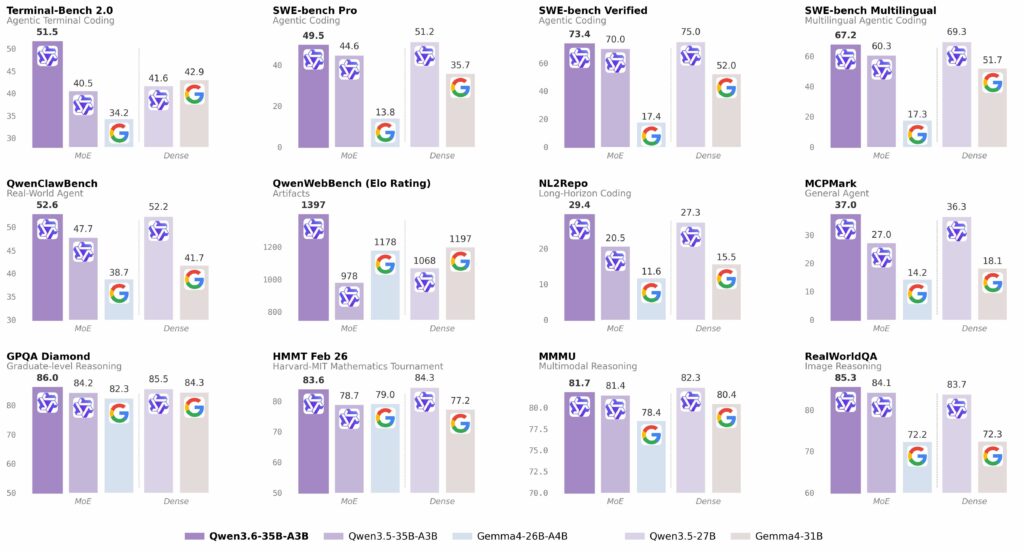
次に、Qwen 3.6-35B-A3Bで動かしてみます。これは、Alibabaが、4月15日にリリースしたオープンウェイトモデルです(参考:Qwen 3.6-35B-A3B: Agentic Coding Power, Now Open to All)。先に紹介したGemma 4と比べるとより高いパフォーマンスを発揮すると報告されています。
Gemma 4と同様に以下のコマンドで、Claude CodeをQwen 3.6-35B-A3Bで動かすことができます。
$ ollama launch claude --model qwen3.6:35b
Gemma 4と同様に、Palmer Penguinsのデータセットを分析してもらい、HTML形式のレポートを作成してみました。Gemma 4とほぼ同規模のパラメータサイズのモデルですが、Gemma 4と比べると、Qwen 3.6-35B-A3Bの方がやや考える時間が長い印象を受けました。環境構築などの基本的なタスクは概ね問題なくできますし、分析作業もフィードバックなどをもとに進めることが可能です。
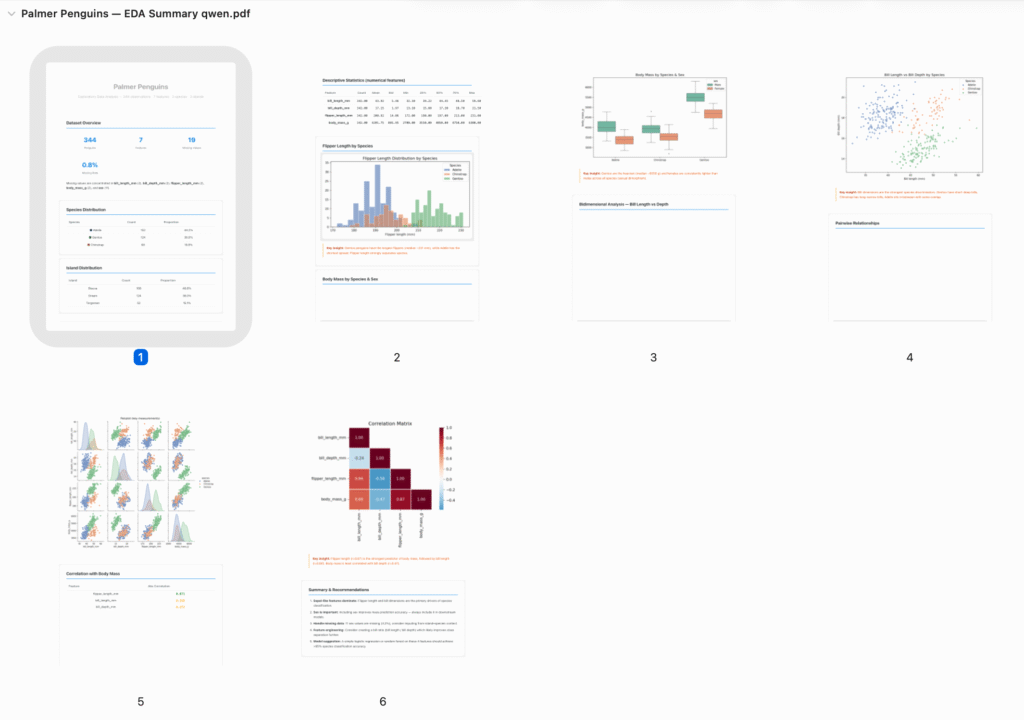
作成したレポートの質としては、まあ、やはりローカルLLMなので、Gemma 4とは大差はなく、そのままでは物足りないですね。適切なフィードバックを与えて、改善していく必要がありそうです。
MacBook ProでもローカルLLMでClaude Codeを実行してみる:1-bit/Ternary Bonsai 8B
ここまでは、NVIDIA GeForce RTX 4090を搭載したPCで、比較的大規模なモデルを利用してClaude Codeを動かしてみました。しかし、実際にはローカルのラップトップでも動かしてみたいです。そのためには、やはり小型軽量モデルの方が有利です。
1-bit Bonsai は、Prism MLが、3月31日にリリースしたオープンウェイトモデルです(参考:Announcing 1-bit Bonsai: The First Commercially Viable 1-bit LLMs)。モデルのウェイトが1-bitで量子化されているという、非常に尖ったモデルで、Bonsai 8Bは、8Bのパラメータ数ながら僅か1GB程度のサイズに収まっています。
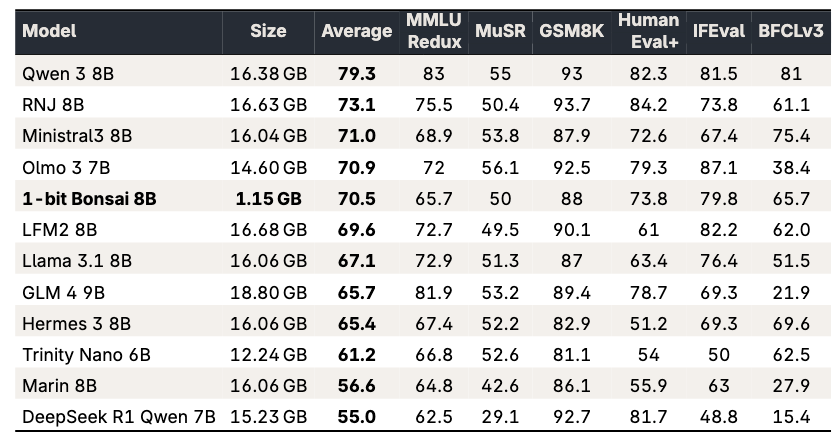
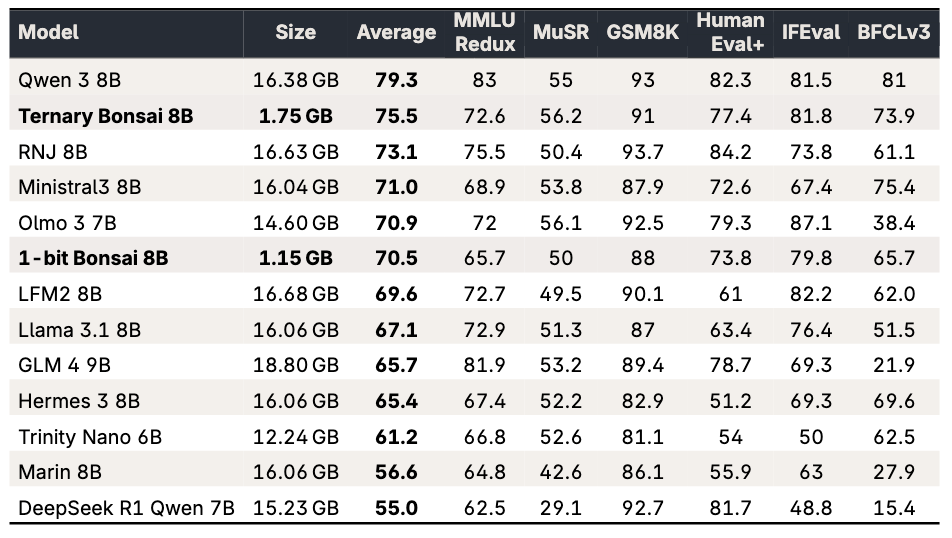
更に1-bitではなく、1.58 bitに拡張した Ternary Bonsai 8Bも、4月16日にリリースされました(参考:Introducing Ternary Bonsai: Top Intelligence at 1.58 Bits)。1.58 bitとは何だと思われるかもしれませんが、0 or 1 の 1 bit から、-1, 0, +1 の3通りのウェイトに拡張したもので、これが約1.58 bitの情報量に対応します。その分、1-bit Bonsai 8Bと比べるとモデルサイズは増加(約600 MBほど)しますが、それでも他の8B級のモデルと比較して約1/10程度と圧倒的な軽量さを誇ります。
Ternary Bonsai 8Bの導入は、LM Studioを利用してモデルをダウンロードして、ロードし利用します。
$ export ANTHROPIC_BASE_URL=http://127.0.0.1:1234 $ claude
動かしてみましたが、Bonsai 8Bは高速なモデルではあるものの、Claude Codeの実行時には膨大なトークンを消費するため、全く実用的な速度ではありません。以下はClaude CodeからTernary Bonsai 8Bへのアクセス時のログですが、プロンプトの処理がなかなか終わりません。
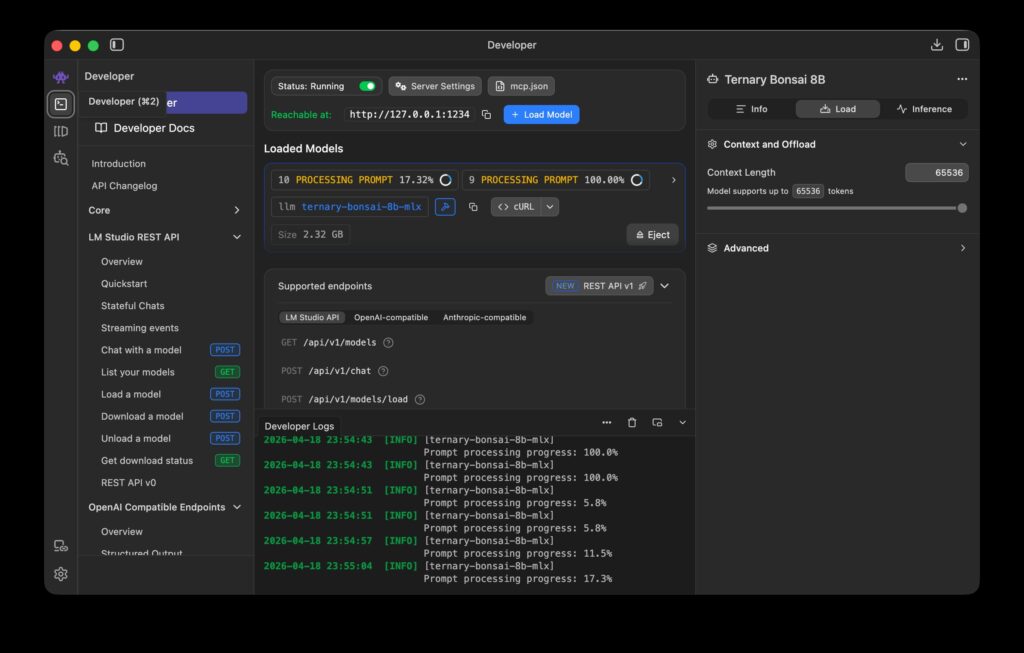
数分待っても、基本的な作業が全く進まないことも多く、出力結果も不安定で、途中で止まったり、エラーが発生することがあります。

色々と試行錯誤しましたが、やはり、Claude Codeのシステムを動かすには、小型のオープンウェイトモデルでは限界がありますね。実験は主にはM1 MaxのMacBook Proで行いましたが、M4 MaxのMacBook Proを利用すると速度は多少改善されますが、同様の結果でした。
Claude Codeの代わりにOpenCodeを使ってみる
Claude CodeをローカルLLMを使って動かそうと苦労したのですが、結局、Claude Codeは、Claudeのような高性能なLLMを前提に設計されているため、ローカルLLMで動かすには、やはり性能的な限界があります。どうしても、ローカルLLMでAIエージェントツールを動かしたい、というのであれば、もっと軽量なツールを利用した方が良さそうです。OpenCodeは、オープンソースで開発されているAIエージェントツールです。
OpenCodeをローカルLLMで動かすことは、Claude Codeの場合と同様にollamaコマンドから簡単にできます。今回はMacBook Proで、gemma4:e4bモデルを使用します。
$ ollama launch opencode --model gemma4:e4b
以下のように、ターミナルでOpenCodeが起動して、バックエンドとしてはローカルLLMのgemma4:e4bがOllamaを通じて利用されていることがわかります。

OpenCodeは、Claude Codeと比べると、より軽量な設計となっているためか、非常にサクサクと動作します。以下のように、返答までのラグも許容範囲で、工夫次第では様々なタスクに活用できるかもしれません。

まとめ
今回、Claude Codeの中の人をローカルLLMに切り替えて動かしてみました。最新のオープンウェイトモデルであるGemma 4やQwen 3.6-35B-A3Bを利用すれば、ある程度は実用的に動かすことができましたが、オリジナルのClaude Codeには到底及びません。また、GPUの性能が十分でないと、やはり実用的な速度で実行は難しいです。また、Bonsai 8Bのような小型軽量モデルでは、そもそもClaude Codeを動かすには性能的に厳しいです。Claude Codeでは、内部で大量の推論プロセスを実行しており、Claudeのような高性能なLLMを前提に設計されているため、ローカルLLMで動かすには、やはり性能的な限界があります。どうしても、ローカルLLMでAIエージェントツールを動かしたい、というのであれば、もっと軽量なツールを利用した方が良さそうです。OpenCodeは、Claude Codeと比べると、より軽量な設計となっているためか、非常にサクサクと動作します。ただ、やはりローカルLLMの性能に依存する部分も大きい印象です。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD