2026.05.25
Claude CodeをローカルLLM(DeepSeek V4 Flash on DwarfStar 4)で動かしてみた
TL;DR
- Redisの開発者として知られる Salvatore Sanfilippo (antirez) 氏が、DeepSeek V4 Flash に特化したローカル推論エンジン DwarfStar 4 (ds4) を公開しました。「たった1つのモデルを完璧に動かす」ことに振り切った設計が特徴です。
- 一部のレイヤー(routed MoE expert)のみを2-bit量子化する非対称量子化を採用することで、モデル全体の精度を保ちつつ、必要なメモリ量を大幅に削減しています。これにより、284Bパラメータのモデルを約81GBまで圧縮し、128GBメモリのMacで動作可能としています。MacBook Pro M4 Max 128GBでは、長コンテキストでもプリフィルで120 t/s程度、生成で15 t/s程度の性能を維持しました。
- これを利用すれば、DeepSeek V4 Flashをバックエンドとして、Claude Codeをローカル環境で動かすことができます。性能面では、以前にローカルGPUサーバーで実験したGemma 4 26B A4BやQwen 3.6-35B-A3Bと比較して、よりオリジナルのClaude Codeに近い応答が得られている印象です。
はじめに
こんにちは、グループ研究開発本部 AI研究開発室のT.I.です。
さて、2026年4月24日、DeepSeekはDeepSeek V4 Previewを公開しました。V4には、1.6Tパラメータの DeepSeek V4-Pro と、284Bパラメータの DeepSeek V4-Flash の2つのモデルがあり、いずれも MIT ライセンスで HuggingFace にウェイトが公開されています(deepseek-ai/DeepSeek-V4-Pro [HuggingFace])。コンテキスト長は1Mトークンと非常に長く、Math/STEM/Coding 領域では既存のクローズドモデルのトップレベルを上回る性能を発揮しています。
しかし、いくらオープンウェイトとはいえ、284Bや1.6Tものパラメータをローカルで動かすには、要求されるGPUリソースがあまりに大きく、これをローカルLLMと呼んでよいものかと正直、思ってしまいます。そんな中、Redisの作者である Salvatore Sanfilippo (antirez) 氏が、DeepSeek V4 Flash のためだけに書き下ろした専用推論エンジン DwarfStar 4 (ds4) を公開しました。発表当初は ds4 という名称のみでしたが、のちに DwarfStar 4 と改名されています。これにより、DeepSeek V4 FlashをApple Siliconのローカル環境で実行することが可能になりました。とはいえ、要求スペックは128GBのRAMが推奨(96GBでも動作可能)と、やはり敷居が高いですね、動かすのは無理そうです。

と思いきや、手元のMacBook Pro M4 Maxのメモリは128GBありました。これなら動かせそうです。
今回のブログでは、この DwarfStar 4 を M4 Max 128GB の MacBook Pro で動かし、Claude Code をローカル環境で実行してみた結果を紹介します。
DeepSeek V4 Flash を M4 Max 128GB MacBook Pro で動かしてみる
セットアップ
DwarfStar 4 の導入は非常に簡単で、公式のREADMEに従って以下のコマンドを実行するだけです。
$ git clone https://github.com/antirez/ds4.git $ cd ds4 $ make $ ./download_model.sh q2-imatrix
checkpoint のダウンロードは回線次第ですが、10分強で完了しました。make はものの数秒で終わります。
推論を実行してみます。
$ ./ds4 -p "Dwarf Starとはどのような天体でしょうか?子供向けに簡潔に解説してください" ds4: context buffers 751.71 MiB (ctx=32768, backend=metal, prefill_chunk=2048, raw_kv_rows=2304, compressed_kv_rows=8194) ds4: Metal device Apple M4 Max, 128.00 GiB RAM ds4: requesting Metal residency (may take tens of seconds)... done ds4: warming Metal model views... done ds4: Metal model views created in 1.934 ms, residency requested in 22422.558 ms, warmup 3.268 ms (mapped 82697.67 MiB from offset 5.08 MiB) ds4: Metal mapped mmaped model as 2 overlapping shared buffers ds4: metal backend initialized for graph diagnostics 子供向けにわかりやすく説明する必要がある。Dwarf Star(矮星)という用語を簡単に説明する。まず「小さな星」という直訳から入り、太陽と比較するのがわかりやすい。白色矮星や赤色矮星の例を挙げるが、子供向けなので専門用語は避ける。光る理由や寿命について簡潔に伝える。全体に「かわいい」「おばけ」など比喩を使って親しみやすくする。 Dwarf Star(ドワーフスター)は、日本語で「矮星(わいせい)」という小さな星のことです。 子ども向けにやさしく説明すると: - **小さな星** で、太陽よりもずっと小さいけれど、とっても明るく光っています。 - 種類はいろいろあって、**赤い小さい星**(赤色矮星)や、**白い小さい星**(白色矮星)があります。 - たとえば「プロキシマ・ケンタウリ」という星は赤色矮星で、太陽の隣にある一番近い星です。 - 長い時間かけてゆっくり光り、最後は暗くなっていきます。 「小さいけど、ずっと輝き続けるかわいい星」とイメージしてもらえたらいいな! ds4: prefill: 68.07 t/s, generation: 31.64 t/s
とのことです。以下のようにメモリ使用量は大変なことになっていますが、なんとか耐えて動いています。

生成速度のベンチマークを取ってみました。
$ ./ds4-bench \ -m ds4flash.gguf \ --prompt-file speed-bench/promessi_sposi.txt \ --ctx-start 2048 \ --ctx-max 65536 \ --step-incr 2048 \ --gen-tokens 128 ds4-bench: context buffers 1311.89 MiB (ctx=65665, backend=metal, prefill_chunk=2048, raw_kv_rows=2304, compressed_kv_rows=16418) ds4: Metal device Apple M4 Max, 128.00 GiB RAM ds4: requesting Metal residency (may take tens of seconds)... done ds4: warming Metal model views... done ds4: Metal model views created in 2.591 ms, residency requested in 22591.451 ms, warmup 14.857 ms (mapped 82697.67 MiB from offset 5.08 MiB) ds4: Metal mapped mmaped model as 2 overlapping shared buffers ds4: metal backend initialized for graph diagnostics ctx_tokens,prefill_tokens,prefill_tps,gen_tokens,gen_tps,kvcache_bytes 2048,2048,315.66,128,25.85,52184460 4096,2048,262.00,128,24.55,80373132 6144,2048,243.06,128,22.45,108561804 8192,2048,229.92,128,23.24,136750476 10240,2048,212.02,128,21.78,164939148 12288,2048,212.23,128,21.51,193127820 14336,2048,194.91,128,19.08,221316492 16384,2048,168.93,128,14.48,249505164 18432,2048,117.29,128,8.43,277693836 20480,2048,75.73,128,9.13,305882508 22528,2048,110.94,128,11.77,334071180 24576,2048,121.04,128,13.40,362259852 26624,2048,128.55,128,13.24,390448524 28672,2048,139.41,128,14.49,418637196 30720,2048,125.55,128,14.49,446825868 32768,2048,135.36,128,15.75,475014540 34816,2048,138.58,128,15.34,503203212 36864,2048,136.30,128,14.72,531391884 38912,2048,133.00,128,15.01,559580556 40960,2048,137.45,128,15.82,587769228 43008,2048,135.47,128,15.63,615957900 45056,2048,137.55,128,15.55,644146572 47104,2048,84.51,128,12.11,672335244 49152,2048,100.88,128,13.17,700523916 51200,2048,116.29,128,14.37,728712588 53248,2048,121.84,128,14.37,756901260 55296,2048,123.99,128,12.91,785089932 57344,2048,95.72,128,13.95,813278604 59392,2048,120.42,128,13.71,841467276 61440,2048,120.90,128,14.66,869655948 63488,2048,117.13,128,14.33,897844620 65536,2048,119.74,128,14.75,926033292
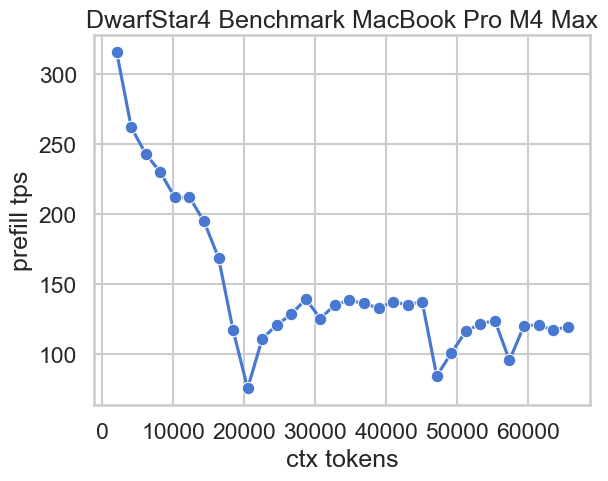
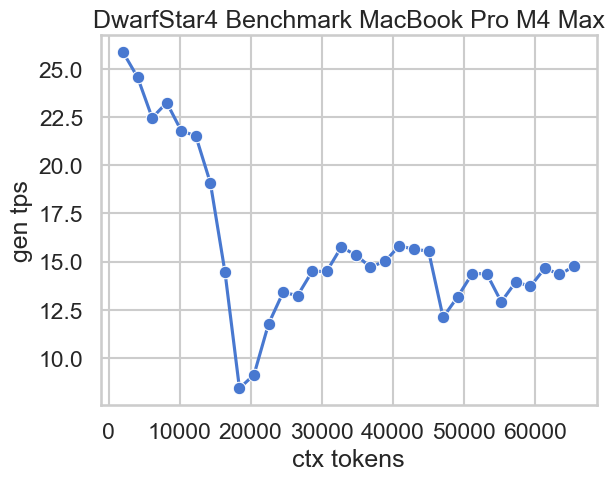
プリフィルと生成の速度をプロットしたものが以下です。コンテキスト長が伸びるにつれて速度はいずれも低下しますが、長コンテキストでもプリフィルで120 t/s 程度、生成で15 t/s 程度のパフォーマンスを維持しています。
Claude Code を動かしてみる
./ds4-server を起動すれば、OpenAI互換の /v1/chat/completions および Anthropic互換の /v1/messages エンドポイントが立ち上がるので、Claude Code や各種クライアントからそのまま接続できます。
$ ./ds4-server --ctx 100000 --kv-disk-dir /tmp/ds4-kv --kv-disk-space-mb 8192
前回のブログ(Claude Code をローカルLLM(Gemma 4、Qwen 3.6、Bonsai 8B)で動かしてみた)で紹介したように、Claude Code のバックエンドをローカルLLMに切り替えるのは簡単で、環境変数を書き換えるだけで済みます。
$ export ANTHROPIC_BASE_URL=http://127.0.0.1:8000 $ export ANTHROPIC_MODEL="deepseek-v4-flash" $ claude
これで、Claude Code の接続先がローカルの DwarfStar 4 サーバーに切り替わります。
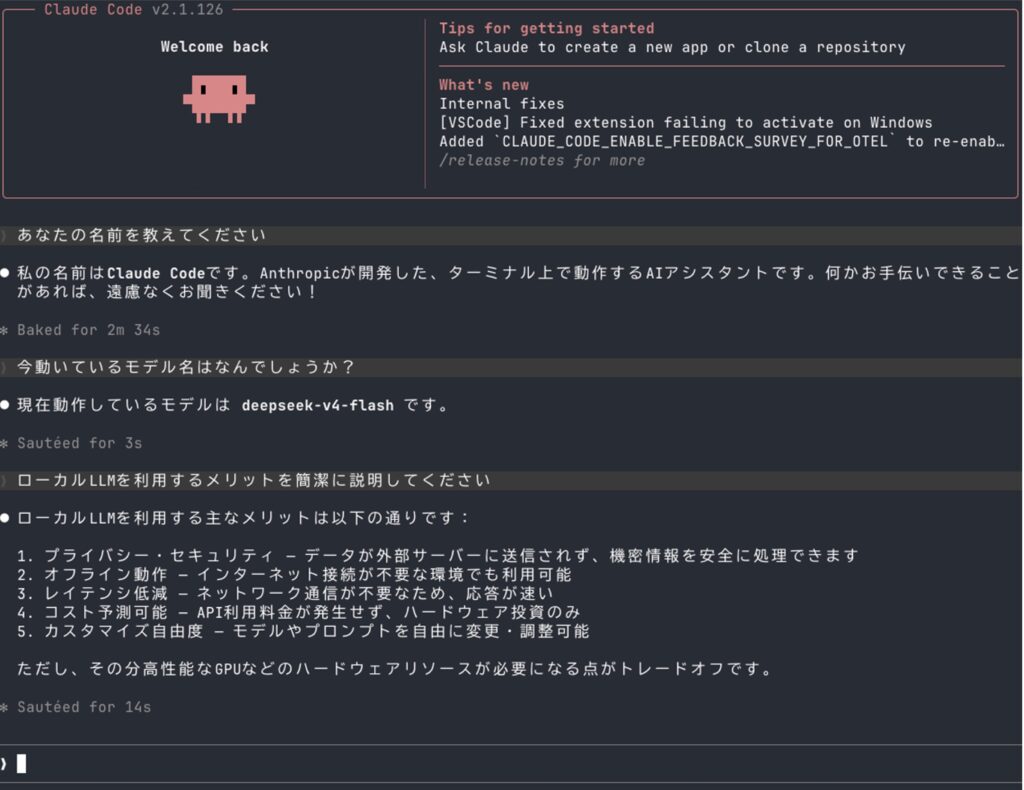
最初のやり取りでは約3万トークンの事前読み込みが入るため少し待たされますが、その後の応答は比較的サクサク進みます。自己認識も正しく、「君の名は?」と聞くと deepseek-v4-flash と返してくれます。前回のブログでローカルGPUサーバー上で実行した Gemma 4 26B A4B や Qwen 3.6-35B-A3B と比較しても、よりオリジナルの Claude Code に近い応答が得られている印象です。Pythonの分析環境の構築から EDAコードの生成まで、速度や性能では本家には及ばないものの、これが MacBook Pro のラップトップ上で動いているというのはなかなかの感慨があります。MacBook Pro M5 Max で同様に Claude Code を動かした技術検証として、「128GB M5 Max MacBook Pro で「ds4」を試したら、Claude Codeがローカルで動いた話 (note)」から始まる一連の記事も公開されています。本ブログよりさらに詳細な実験が紹介されているので、そちらもご覧ください。
試しに、EDAコードを実行し、その結果をもとにレポートを生成してもらいました。
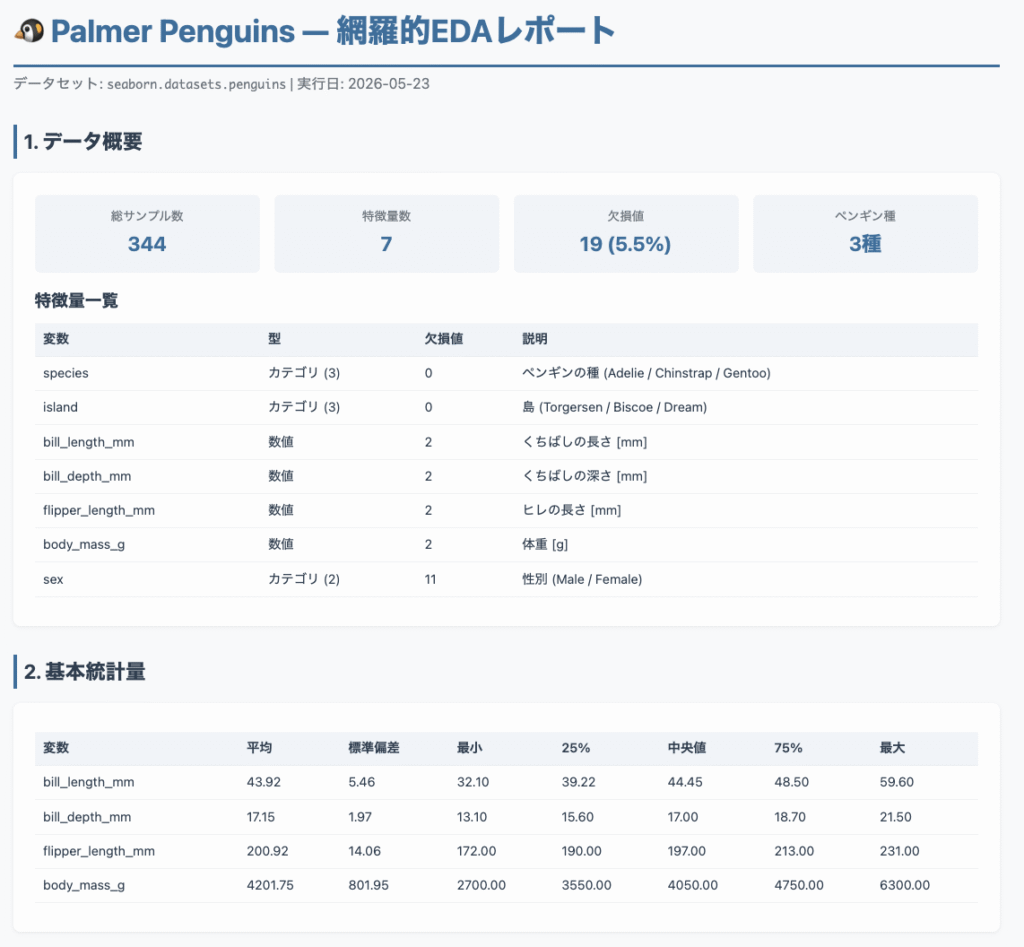
可視化については、最初に出力されたコードでは日本語が文字化けしていましたが、問題点を指摘するとシステムで利用可能なフォントを探索し、コードを修正して以下のように正しく表示されるようになりました。
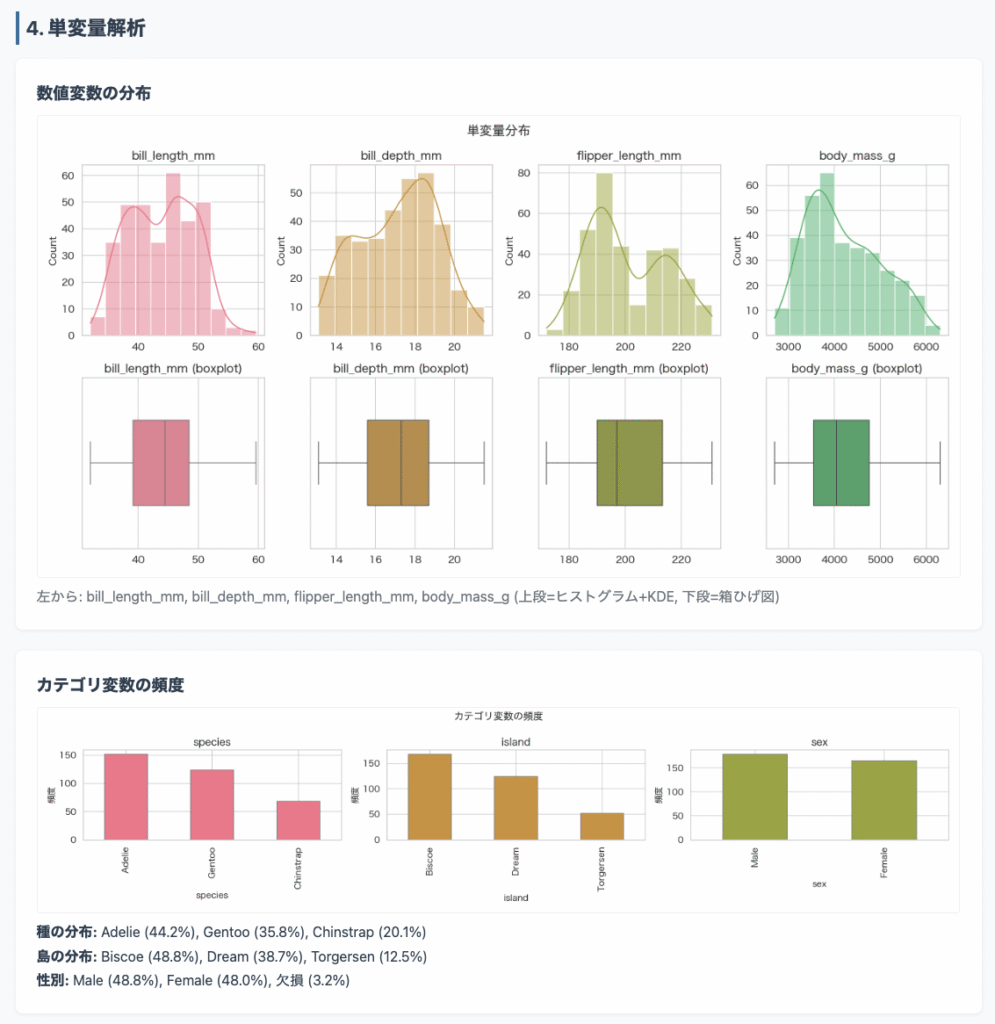
レポートの全体像はこのような感じとなります。
なお、メモリ使用量は ds4 の推論中に110GB程度まで上昇しますが、推論時以外は解放されます。常に128GBの上限に張り付いているわけではないものの、他のアプリで負荷の高い作業を並行して行うのは難しいでしょう。この MacBook Pro は DeepSeek V4 Flash 専用機として、別マシンから接続して利用するのが現実的な運用方法かもしれません。また、後述するように DwarfStar 4 は KVキャッシュをディスクに保存する設計のため、/tmp/ds4-kv 配下に KVキャッシュファイルがどんどん溜まっていく点にも注意が必要です。
$ ls -lhtr /tmp/ds4-kv total 16386312 -rw-r--r--@ 1 TI wheel 419M May 23 15:02 803f6007d626d9a97bc4fc0316194a8eb7a981c9.kv -rw-r--r--@ 1 TI wheel 422M May 23 15:11 6158748fc462752e415177de9681bd087949e579.kv -rw-r--r--@ 1 TI wheel 459M May 23 15:14 46fb40f5391120c3a1309d6707bada41b37619e3.kv -rw-r--r--@ 1 TI wheel 466M May 23 15:15 e0a67cc9ff8fbff220faebde1754d21a88606fae.kv -rw-r--r--@ 1 TI wheel 550M May 23 15:22 45cd9e59c28217ef3e626d81bdd68c6580f3d57b.kv -rw-r--r--@ 1 TI wheel 612M May 23 15:26 081878d925e1cb559bbe58192913e83eb31d7bd4.kv -rw-r--r--@ 1 TI wheel 726M May 23 15:35 969dfbef4ce1f2fd0cbc243631299cd6d7d9f0ae.kv -rw-r--r--@ 1 TI wheel 402M May 23 15:35 6cbde7d64b977e0b296efa6447124b8c6b040b51.kv -rw-r--r--@ 1 TI wheel 426M May 23 15:35 1bcba3e66ab619adb32a2f7146ccfa9b3d135e43.kv -rw-r--r--@ 1 TI wheel 723M May 23 15:37 d3ad70e8bfaff0daee44c7a58010b798965085dc.kv -rw-r--r--@ 1 TI wheel 855M May 23 15:43 7c67bc6c7bbc55b9316b72c1a094304d4d82675a.kv -rw-r--r--@ 1 TI wheel 695M May 23 15:44 3748a6c5b4a08a7e970689f8e679bccddb0f6955.kv -rw-r--r--@ 1 TI wheel 830M May 23 15:45 043e4ad7c5be2372f4ed5ac0f829d09a2c366208.kv
なお、前回のブログ同様に簡単な EDA デモを行いましたが、これはあくまでネタであって、実際の分析業務でこれを提出するのはやめておきましょうね(マジでやめてください)。
DeepSeek V4 と DwarfStar 4 について
ここで、今回のブログの主役である DeepSeek V4 Flash と DwarfStar 4 の技術的なポイントを整理しておきます。
DeepSeek V4 の概要
まず、対象となる DeepSeek V4 Flash のスペックを整理しておきます。詳細は DeepSeek の Docs や HuggingFace のモデルページ、テクニカルレポート(DeepSeek V4 Technical Report)を参照ください。DeepSeek V4 Pro は1.6Tパラメータの MoE アーキテクチャを採用したモデルで、アクティブパラメータは49Bです。一方の DeepSeek V4 Flash は、284Bパラメータでアクティブパラメータは13B程度となっています。両者ともコンテキスト長は1Mトークンと非常に長いことが特徴です。
冒頭でも紹介したように、DeepSeek V4 Pro は他のクローズドモデルと比較しても、Math/STEM/Coding 領域でトップレベルの性能を発揮しています。そして、今回ローカルで実行した DeepSeek V4 Flash も、性能面では V4 Pro に匹敵するレベルのモデルです。
さらに、DeepSeek V4 Flash の特色として、KVキャッシュが非常に圧縮されている点が挙げられます。KVキャッシュとは、LLM のキーテクノロジーである Attention の処理を高速化する仕組みで、推論時に過去の Key-Value を保持しておくことで再計算を避けることができます。この高い圧縮率に着目して、DwarfStar 4 は開発されています。
DwarfStar 4 の技術要素
続いて、DwarfStar 4 の技術的なポイントを整理しておきます。公式リポジトリの README (DwarfStar 4 README) には、以下のように記載されています。
DwarfStar 4 is a small native inference engine specific for DeepSeek V4 Flash. It is intentionally narrow: not a generic GGUF runner, not a wrapper around another runtime: it is completely self-contained.
(DwarfStar 4 は、DeepSeek V4 Flash 専用の小型ネイティブ推論エンジンである。これは意図的に用途を絞っており、汎用的な GGUF ランナーでもなければ、他のランタイムをラップしたものでもなく、完全に自己完結している。)
文字通り DeepSeek V4 Flash の専用エンジンとして開発されており、「汎用性を捨てて全振り」する姿勢は見習いたいものです。DeepSeek V4 Flash に着目した理由として、README では以下の8項目が挙げられています。
- アクティブパラメータ数が13B程度と比較的少ない
- Thinking mode の出力長も他のモデルと比較して1/5程度で済む
- コンテキストウィンドウが100万トークンと非常に長い
- 総パラメータ数が284Bと多いため、27Bや35Bクラスと比較して知識が豊富
- 英語・イタリア語の性能が高い
- KVキャッシュの圧縮率が高く、長コンテキストでの推論やディスクへのKVキャッシュ永続化が可能
- 2-bit量子化でも高い性能を発揮し、128GBのメモリで動作可能
- 今後も DeepSeek による V4 Flash のアップデートが期待できる
まず、量子化について見ていきます。通常、巨大モデルをローカルで動かす際は、すべてのレイヤーを一律に低ビットへ圧縮することが多いのですが、DwarfStar 4 ではレイヤーごとに異なるビット幅を割り当てる Asymmetric Quantization を採用しています。ポイントは、「量子化に弱い箇所だけ高精度のまま残す」 という戦略です。MoE のルーティング先のエキスパートは数が多く、ここを2-bitに圧縮するとサイズ削減効果が大きい一方、共有エキスパートや Attention 層、出力層を低ビット化すると品質劣化が顕著になる傾向があります。そこで重要度の低い部分だけ大胆に圧縮し、重要度の高い部分は精度を維持することで、284Bモデルを約81GBに圧縮しつつ品質劣化を最小限に抑える、というアプローチを取っています。今回の実験では128GBのRAMを持つ MacBook Pro を利用しましたが、さらにメモリが許すならば4-bit量子化のモデルも利用可能です。
$ ./download_model.sh q2-imatrix # 96/128 GB RAM machines, imatrix-tuned q2 $ ./download_model.sh q4-imatrix # >= 256 GB RAM machines, imatrix-tuned q4
もう1つの面白い設計が、KVキャッシュのディスク永続化 です。推論時のKVキャッシュは通常 RAM に保持されますが、DwarfStar 4 では「圧縮されたキャッシュなら SSD に置いても問題ない」という割り切りで、ディスクに保存する設計を採用しています。先ほどの Claude Code での実験でも見たように <sha1>.kv というファイル名で順次保存され、次に同じプロンプトが来た場合は KVキャッシュをディスクから読み戻すだけで済むため、大幅に高速化されます。「DwarfStar 4 で DeepSeek V4 Flash 284B を DGX Spark に載せてみた」では、DGX Spark 環境での DwarfStar 4 のベンチマークを通じて、この KVキャッシュの効率について詳しく紹介されています。
まとめ
今回のブログでは、DeepSeek が発表したオープンウェイトモデル DeepSeek V4 Flash を、Salvatore Sanfilippo (antirez) 氏が公開した専用ローカル推論エンジン DwarfStar 4 を用いて、M4 Max 128GB の MacBook Pro 上で動かし、Claude Code を実行してみました。
DwarfStar 4 の設計思想は「汎用性を捨てて、1つのモデルを完璧に動かす」というもので、非対称2-bit量子化によって284Bモデルを約81GBに圧縮し、さらに KVキャッシュのディスク永続化を組み合わせるといった技術要素が興味深い点です。これらの工夫により、Claude Code をローカル環境で完結して実行することが可能となっています。さすがに本家 Claude の性能には及びませんが、前回のブログで紹介した Gemma 4 や Qwen 3.6 と比較すると、よりオリジナルの Claude Code に近い応答が得られている印象です。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- DeepSeek V4 Preview Release | DeepSeek API Docs
- deepseek-ai/DeepSeek-V4-Pro [HuggingFace]
- DwarfStar 4 (ds4) GitHubリポジトリ
- Claude Code をローカルLLM(Gemma 4、Qwen 3.6、Bonsai 8B)で動かしてみた
- 128GB M5 Max MacBook Pro で「ds4」を試したら、Claude Codeがローカルで動いた話 (note)
- DwarfStar 4 で DeepSeek V4 Flash 284B を DGX Spark に載せてみた (DevelopersIO)
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD