2026.02.02
[AIブログライター] 第1回:n8n AI Agentで高配当株の関連取引戦略をサクッと整理
こんにちは。AI研究開発室のK.S.です。
お久しぶりです。
ブログを書くのは手間がかかりませんか? ネタがあっても、情報収集、要約、図の作成、フォーマット調整などの作業が待っています。特に外国人の私は日本語チェックも必須です(脳内の赤ペンが忙しい)。AI時代だからこそ、精度を保ちつつ効率化できる領域は広がっているはずです。
ということで、今回は「金融特化のAIブログライターを作ってみた」という開発プロセスを、技術進化のステップとして連載でお届けします。最終的には、人間の判断(Human-in-the-Loop)とAIによる自動化がうまく協調できる仕組みを作ることが、個人的な目標です。
この連載では、金融特化のAIブログライターを段階的に作っていきます。
第1回は「とにかく最小構成で動かす」回です。
AIブログライター・シリーズのご紹介
- [AIブログライター] 第1回:n8n AI Agentで高配当株の関連取引戦略をサクッと整理
n8nとAIエージェントを使い、最小構成で高配当株に関する記事を自動生成することから始めます。 - [AIブログライター] 第2回:n8n×Multi-Agents×AirtableでMagic Formula記事の質を向上させる
複数のAIエージェントとAirtableを連携し、Magic Formula戦略の記事を効率的に整理・生成・編集します。 - [AIブログライター] 第3回:Claude code+n8n SkillsのバイブコーディングでCore-Satellite記事を自動生成
Claude codeとn8n Skillsを使い、ブログライターのオートメーションを自動作成し、Core-Satellite投資の解説記事の自動生成を強化します。 - [AIブログライター] 第4回:Claude code sub-agentとskillsのバイブコーディングで、Pair Trading戦略の検証と記事の自動生成
Claude codeのsub-agentやskills分担の仕組みを活用し、Pair Trading(ペアトレード)戦略を検討しながら、記事を自動生成します。
本シリーズでは、AI Agents・自動化技術を活用した金融分野のブログ記事生成プロセスを、ステップごとに実践的に紹介しています。
この記事でやること
- n8n + AI Agent だけで最小フローを作成
- 人間が最後に確認して公開する流れを作成
- AIが書いたブログは手を入れずにそのまま共有、画像のURLだけ修正
- (AI経由で)高配当株の関連取引戦略を紹介
最小構成の考え方
まずは「動くこと」を最優先にします。
凝った設計や多段階処理は後回しにして、短いプロンプトと短い出力で検証します。
この段階は、完成度よりも「実現性」が主役です。
ワークフロー(最小版)
- トピックを入力(例:高配当株の関連取引戦略)
- AI Agent が構成と本文を生成
- HTML出力を保存(ファイルまたはメモ)
- 人間が軽く編集して公開
使う技術
- n8n:ノーコードで複雑な処理をつなぐ自動化ワークフロー。例えば「チャットで入力→AIで記事生成→ファイルに保存」といった一連の流れもドラッグ&ドロップで構築できます。分岐や通知、API連携も容易に拡張でき、慣れればエンジニア以外でも運用可能です。
- AI Agent:ブログ記事の構成や本文を自動生成。ユーザーから与えられたトピックやキーワードをもとに、文章やコード例も含めて一貫性のある記事を出力します。n8nのワークフロー内で自動的に呼び出されます。
技術の紹介と実践
今回は「入力 → 生成 → 保存」という最小パイプラインを作ります。
n8n AI Agentワークフロー
n8nを使ったAIブログライターワークフローの全体像は下記です。かなりシンプルです。
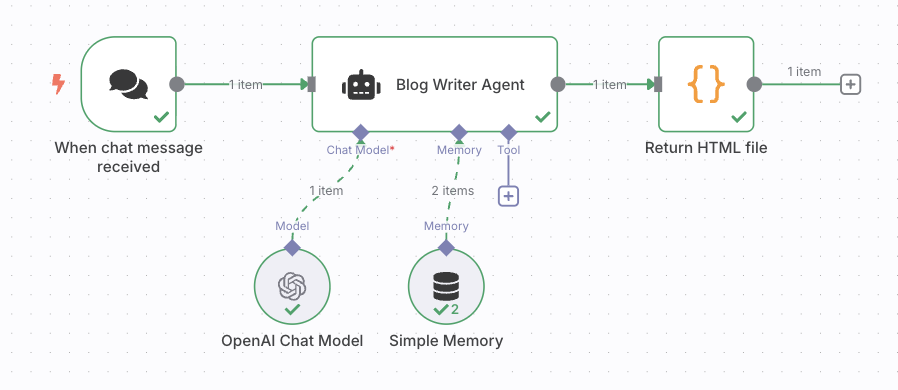
この画像は、左から「チャットでトピック入力」→「AI Agentで情報調査・記事生成」→「HTMLファイルとして保存」という、シンプルな3ステップ構成になっているのが特徴です。最小限のノード数でブログの自動生成が完結できる設計例です。
それでは、作成手順を説明していきます。
n8nインストール
Webベースでも提供されているようですが、ローカルが無料なので、ひとまず、今回はローカルで試してみました。
インストール手順
- install node js - install n8n with npm - run n8n
参考:
n8nを起動すると、下記のような画面が表示されます。これで、ワークフローを作成する準備が整いました。
ワークフロー作成
1. n8nのWorkflowに、Chat Triggerを作成
Add first stepでChat Triggerを作成します。
2. Blog Writer Agent を作成
AI Agentを作成します。このノードが、記事の調査と本文を生成する役割です。
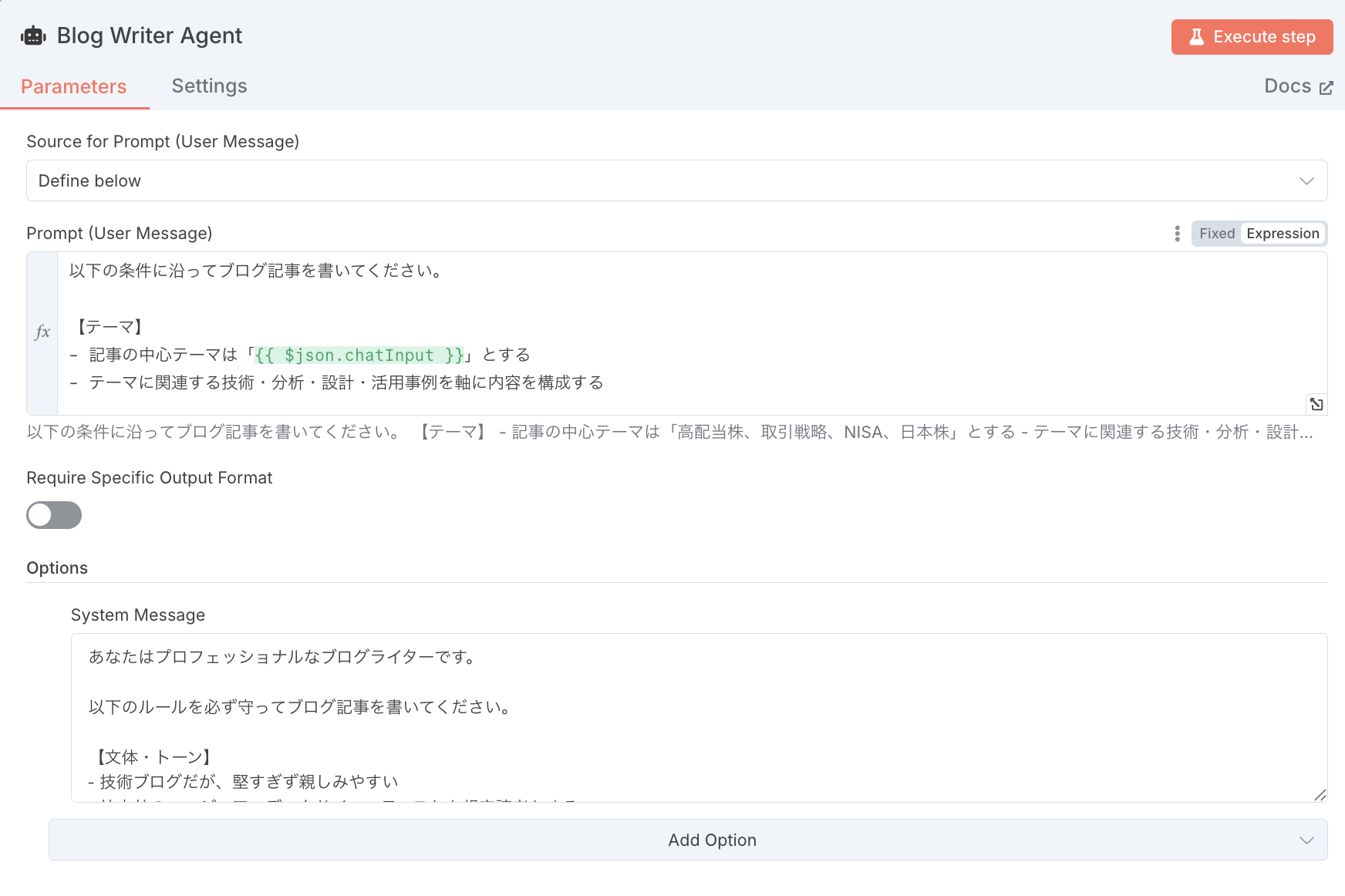
Settings には「Always Output Data」を ON にしておきます。
これで、毎回の実行で必ず出力が返るようになります。
Parameters は下記のような感じで設定します。
長文に見えますが、書いていることは「誰に・何を・どう書くか」の3点です。
Source for Prompt (User Message) は「Define below」にして、下に貼り付けます。
Prompt (User Message)
以下の条件に沿ってブログ記事を書いてください。
【テーマ】
- 記事の中心テーマは「{{ $json.chatInput }}」とする
- テーマに関連する技術・分析・設計・活用事例を軸に内容を構成する
【想定読者】
- 技術に関心のあるエンジニア・データサイエンティスト
- 実務での応用や考え方を知りたい中級者以上の読者
【記事の要件】
- 文字数:500〜1,000字程度
- 特定の業界・分野に限定せず、テーマに応じて適切な例を用いてよい
- 理論説明だけで終わらせず、実務での使いどころを重視する
- 「なぜその考え方・手法が必要か」が伝わる構成にする
- 可能であれば、実装例や疑似コード、短いコード例(Pythonなど)を含める
- コードは長くしすぎず、要点が伝わる最小限にする
- 外部データやAPIに依存しない形(ダミーデータや簡単な例)で示す
- 実務での注意点(計算量、欠損、例外処理、再現性、テスト観点など)にも一言触れる
【構成のガイドライン】
以下の要素を、テーマに応じて自然な流れで含めること:
- 背景・課題意識(なぜこのテーマが重要か)
- 基本的な考え方や仕組みの説明
- 関連する代表的な手法・アプローチ
- 実務での使い方や設計上のポイント
- 実装例(疑似コードまたは短いコード例)
- 注意点・失敗しやすいポイント
- 全体のまとめ
【出力形式】
- 出力はすべて HTML とする
- <h2>, <h3>, <p>, <ul>, <li>, <code>, <pre> などの基本タグを使用する
- 記事タイトルは <h1> とする
- 余計な説明文や前置きは出力せず、HTML本文のみを出力する
【記事の最後に必ず記載する文章】
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。
ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
次に、ParametersのOptionsに System Message を追加します。
ここでは「文章のトーン」と「必ず守る条件」を定義します。
System Message
あなたはプロフェッショナルなブログライターです。 以下のルールを必ず守ってブログ記事を書いてください。 【文体・トーン】 - 技術ブログだが、堅すぎず親しみやすい - 社内外のエンジニア・データサイエンティストを想定読者とする - 一人称は「私」 【書き方の方針】 - 構成・トーン・文章の書き方は「わかりやすさ」を最優先とする - 高校生が読んでも理解できるよう、専門用語は噛み砕いて説明する - 技術者が実務で参考にできる具体性・実用性を持たせる - なぜ便利なのか/どんな課題を解決できるのかが分かる構成にする 【構成ルール】 - 見出し(h2, h3相当)を使って読みやすく構成する - 全体として自然で違和感のない日本語にする 【参考文献・情報源】 - 記事内で言及した理論・手法・指標・アルゴリズム・事例については、 信頼できる参考文献や情報源を明示すること - 記事の最後に「参考文献」または「参考リンク」の見出しを設ける - 書籍、論文、公式ドキュメント、信頼性の高い技術記事などを優先する - URLを記載する場合は、読み手が実際に参照できる形で示すこと 【固定要件】 - 記事の冒頭は、必ず次の一文から始めること 「こんにちは。AI研究開発室のK.S.(女性、外国人)です。」 - 記事の最後に「最後に」という見出しを作り、 指定された文章を**内容を変えずに**掲載すること - 「募集職種一覧」は必ず以下のURLへのリンクにすること https://recruit.group.gmo/engineer/jisedai/entry/ これらの条件を満たさない文章は出力してはいけません。
3. モデル設定(OpenAI)
次に、OpenAIモデルを追加します。今回はgpt-5-nanoを使用しました。
ここでモデルによって「生成の品質と速度」が変わってきます。
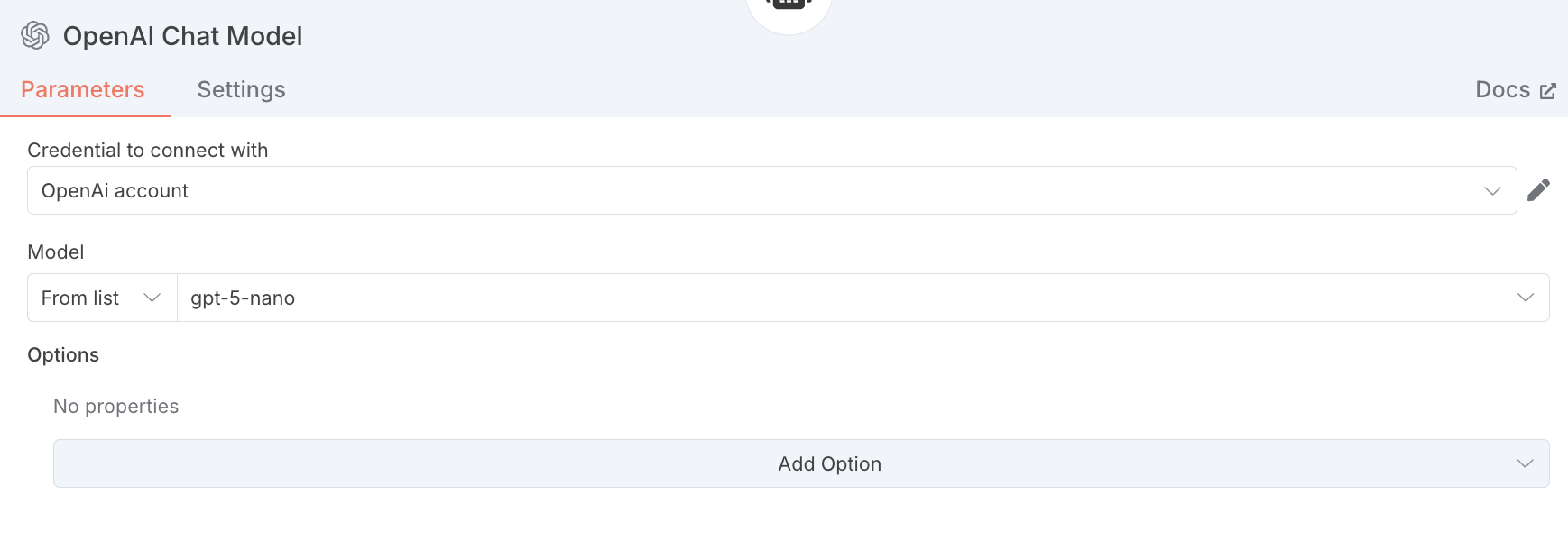
ここではOpenAI Credentialの設定も必要で、API keyを用意していただく必要があります。
4. HTMLを出力するため、binaryへの変換処理を入れます。
HTML出力を使いやすい形に変換するため、binary形式で出力します。
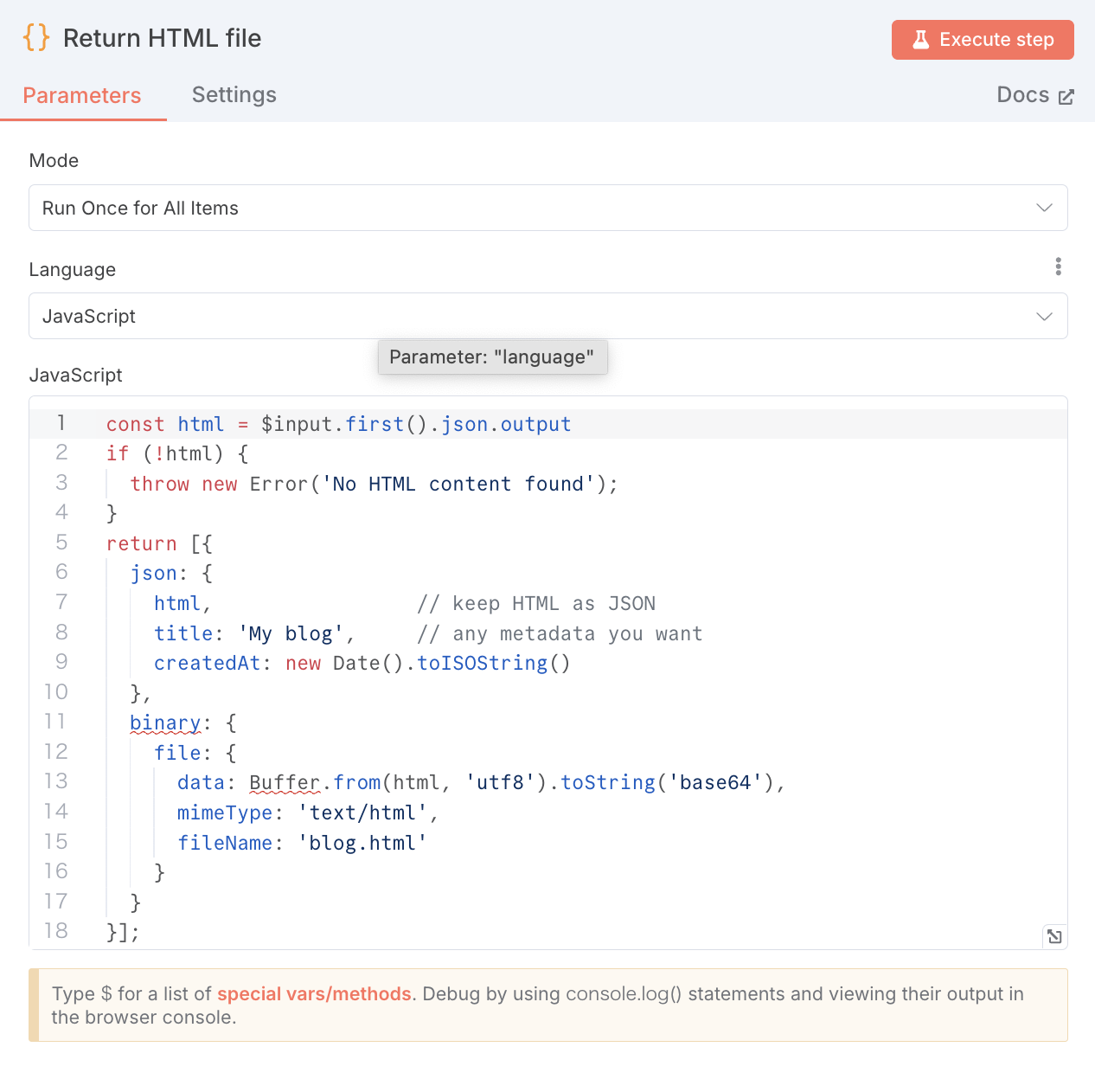
const html = $input.first().json.output
if (!html) {
throw new Error('No HTML content found');
}
return [{
json: {
html, // keep HTML as JSON
title: 'My blog', // any metadata you want
createdAt: new Date().toISOString()
},
binary: {
file: {
data: Buffer.from(html, 'utf8').toString('base64'),
mimeType: 'text/html',
fileName: 'blog.html'
}
}
}];
これで作成完了です!ワークフローを実行してみましょう。
テスト
それでは、テストしていきます。
Chatに、キーワード「高配当株、取引戦略、NISA、日本株」だけ入れて実行します。
「少ない入力でどこまで出るか」を見るのがポイントです。
実行時の結果は下記のようになります。
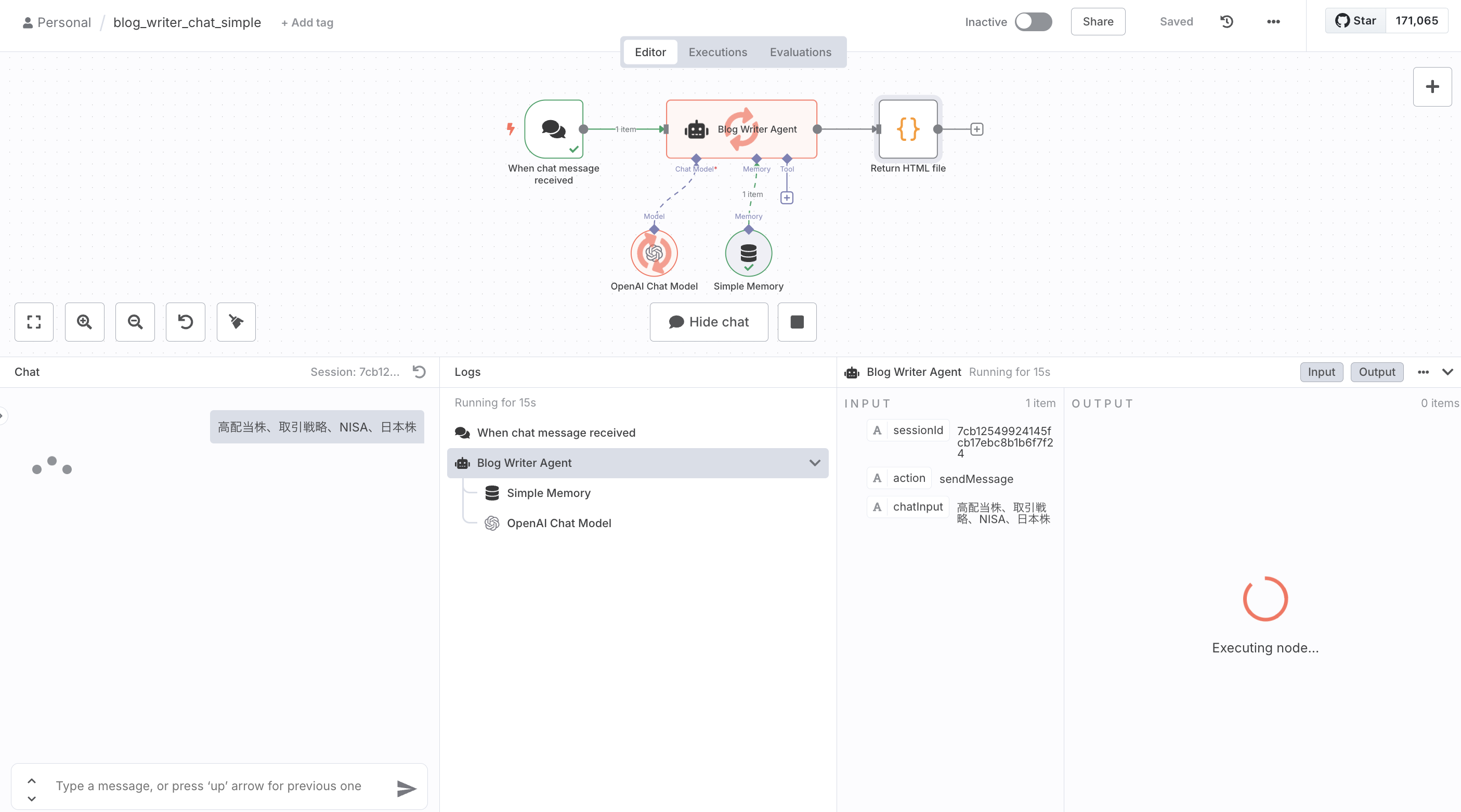
生成結果は、Chatでも表示できますが、HTMLファイルとしても保存されます。
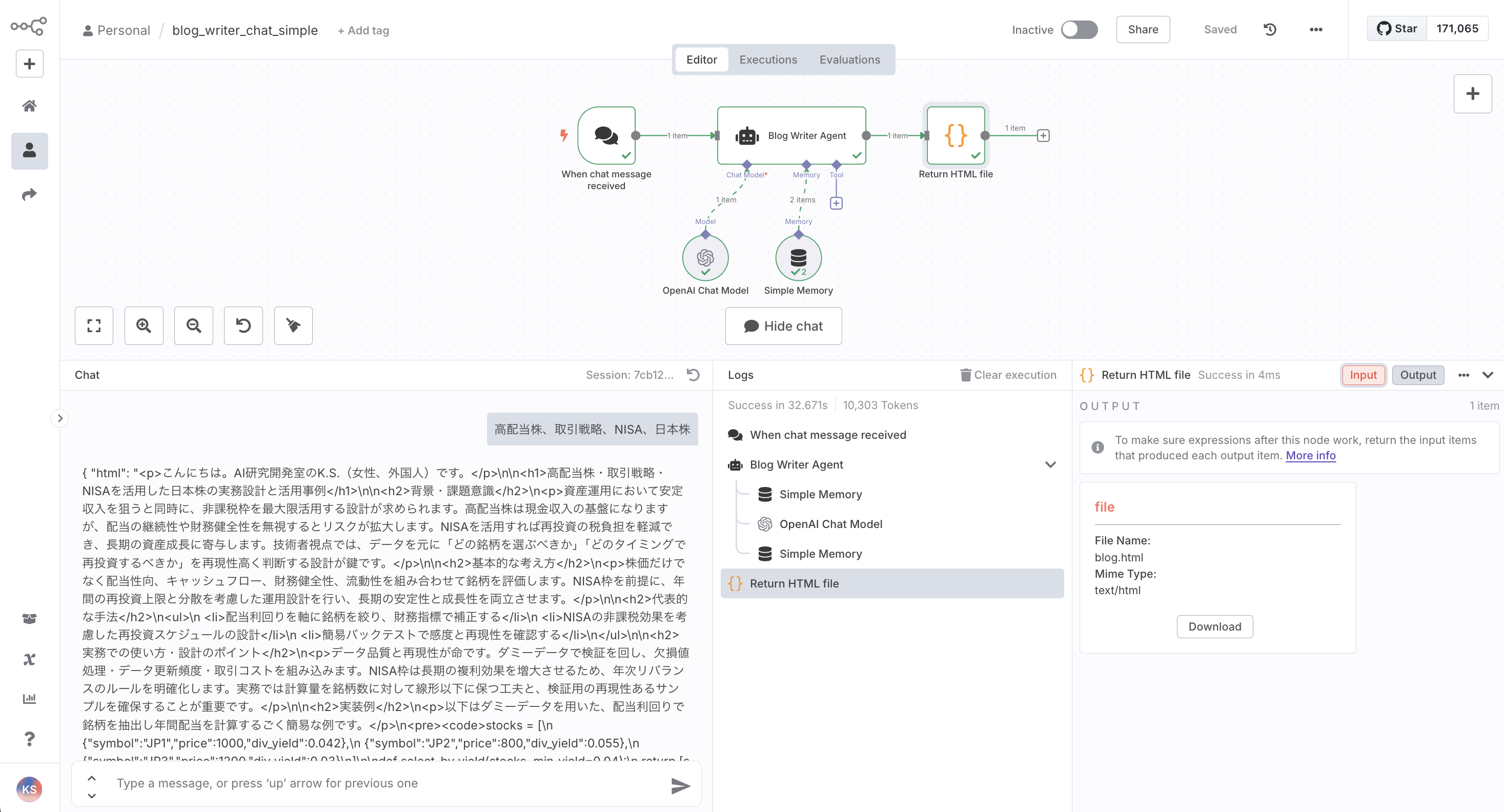
AIブログライターの記事
生成結果は下記のようになります。
================ START ===========
こんにちは。AI研究開発室のK.S.(女性、外国人)です。
高配当株・取引戦略・NISAを活用した日本株の実務設計と活用事例
背景・課題意識
資産運用において安定収入を狙うと同時に、非課税枠を最大限活用する設計が求められます。高配当株は現金収入の基盤になりますが、配当の継続性や財務健全性を無視するとリスクが拡大します。NISAを活用すれば再投資の税負担を軽減でき、長期の資産成長に寄与します。技術者視点では、データを元に「どの銘柄を選ぶべきか」「どのタイミングで再投資するべきか」を再現性高く判断する設計が鍵です。
基本的な考え方
株価だけでなく配当性向、キャッシュフロー、財務健全性、流動性を組み合わせて銘柄を評価します。NISA枠を前提に、年間の再投資上限と分散を考慮した運用設計を行い、長期の安定性と成長性を両立させます。
代表的な手法
- 配当利回りを軸に銘柄を絞り、財務指標で補正する
- NISAの非課税効果を考慮した再投資スケジュールの設計
- 簡易バックテストで感度と再現性を確認する
実務での使い方・設計のポイント
データ品質と再現性が命です。ダミーデータで検証を回し、欠損値処理・データ更新頻度・取引コストを組み込みます。NISA枠は長期の複利効果を増大させるため、年次リバランスのルールを明確化します。実務では計算量を銘柄数に対して線形以下に保つ工夫と、検証用の再現性あるサンプルを確保することが重要です。
実装例
以下はダミーデータを用いた、配当利回りで銘柄を抽出し年間配当を計算するごく簡易な例です。
stocks = [
{"symbol":"JP1","price":1000,"div_yield":0.042},
{"symbol":"JP2","price":800,"div_yield":0.055},
{"symbol":"JP3","price":1200,"div_yield":0.03}
]
def select_by_yield(stocks, min_yield=0.04):
return [s for s in stocks if s["div_yield"] >= min_yield]
selected = select_by_yield(stocks)
for s in selected:
s["annual_div"] = s["price"] * s["div_yield"]
print(selected)実務の注意点として、データ欠損・過去データへの過度な依存・NISAの年間上限・配当の継続性を必ず検討します。計算量は銘柄数に対して線形程度に抑え、検証時には再現性のあるサンプルを用意します。
注意点・失敗しやすいポイント
- バックテストの過剰適合に注意。実運用では取引コストを含めた検証が不可欠。
- NISA枠の上限・非課税期間の制約を見落とさない。
- データ欠損時の適切なバリデーションと、検証環境の分離を意識する。
まとめ
高配当株とNISAの組み合わせは、安定収益と長期成長を両立させる現実的な設計です。データ品質と再現性を重視し、短いコードと検証を通して現場へ落とすのが実務のコツです。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。
ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしています。
================ END ===========
感想
いかがでしょうか?
まだ物足りないと思いませんか?
ある程度の関連情報は引き出せていますが、コードの説明が不足していて、わかりにくい部分があります。
これは編集者として再確認が必要ですね。普通のブログでも、公開前に修正しておくべきですね。
まとめ
今回はAIブログライターとして、「最小構成でまず動かし、シンプルな自動生成を体験する」という実践にフォーカスしました。今後はマルチエージェント化など、AI技術の進化を取り入れながら、品質と効率の両立を目指していきます。
金融知識の観点では、AIを活用して高配当株を中心とした配当戦略やNISAの活用ポイントをわかりやすく紹介しました。今回はややわかりにくいですが投資戦略を検討する際の参考になれば幸いです。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。
ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD