2026.06.05
Claude Code トークン枯渇問題と最適化戦略
D.M. です。
2026年6月現在の AI エージェント開発の進化は目覚ましいものがありますが、あまりに Claude のトークン消費が激しいため、100ドルの Claude Max サブスクリプションでは「5時間ごとの利用トークン上限(Rate Limit)」で作業が止まる、という現実的な壁の話をよく聞くようになりました。
最上位プラン Claude Max 20x が開発者全員に必要な時代になってきているのですが、会社の状況的に必ずしも用意できるとは限りません。
今回は、この「トークン枯渇問題」を現場でどう対策していくのか、実戦的な Tips を3つの軸に整理してご紹介したいと思います。
結論ファースト
トークン最適化を考える三軸
①そもそもClaude使わない(Codex など別エージェントに作業を分散します)
②トークンの文章を短くして使う(言葉の単純化・LSP)
③ネイティブ機能でトークン消費を抑える工夫
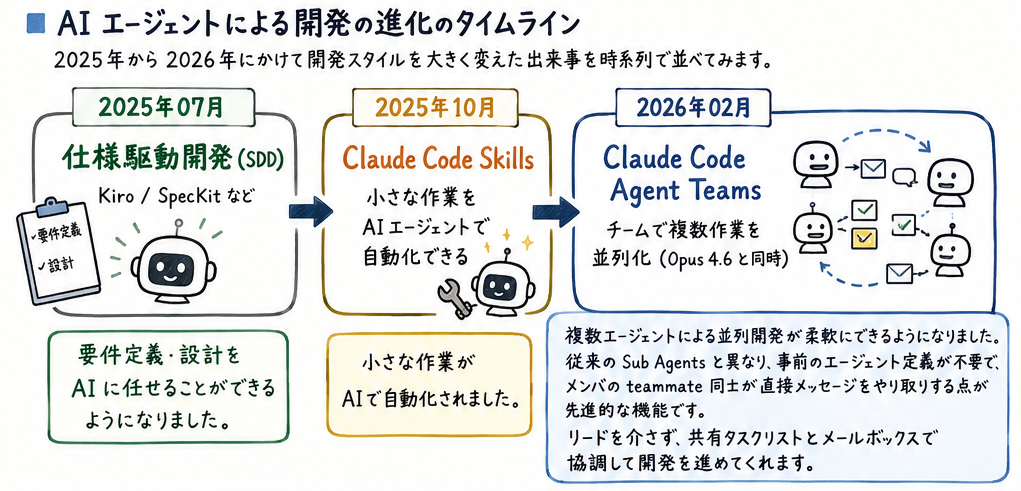
課題:トークンが枯渇するようになった時代の流れ
AI エージェントによる開発の進化のタイムライン
2025年から2026年にかけて開発スタイルを大きく変えた出来事を時系列で並べてみます。
2025年07月 仕様駆動開発(SDD)
Kiro / SpecKit など
要件定義・設計を AI に任せることができるようになりました。
2025年10月 Claude Code Skills
小さな作業をAIエージェントで自動化できるようになりました。
2026年02月 Claude Code Agent Teams
複数エージェントによる並列開発が柔軟にできるようになりました。
従来的な Sub Agents と異なり、事前のエージェント定義が不要。
メンバの teammate 同士が直接メッセージをやり取りする点が先進的な機能。
リードを介さず、共有タスクリストとメールボックスで協調して開発を進められる。
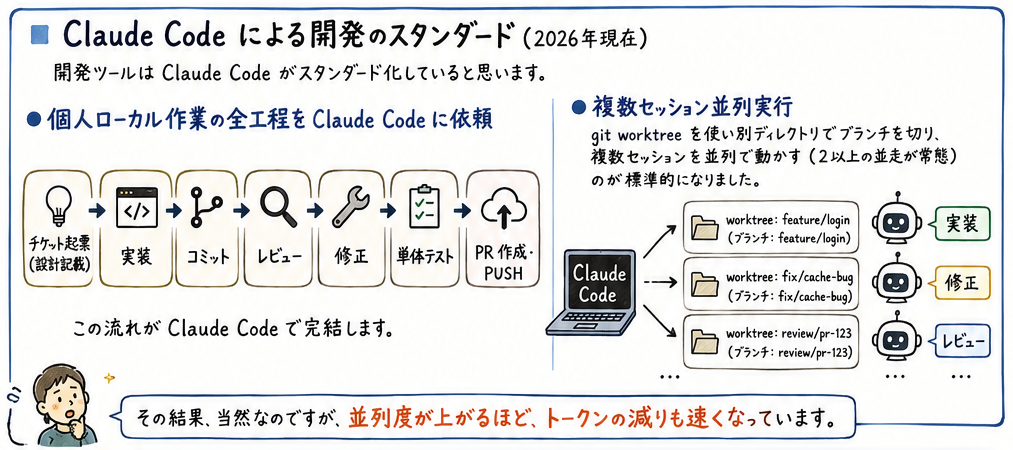
Claude Code による開発のスタンダード
上述のような技術革新を経た結果、2026年現在においては開発ツールは Claude Code がスタンダード化していると思います。
・個人ローカル作業の全工程を Claude Code に依頼
「チケット起票(設計記載)→ 実装 → コミット → レビュー → 修正 → 単体テスト → PR 作成・PUSH」の全ての流れを Claude Code にお任せしている状況です。
・複数セッション並列実行
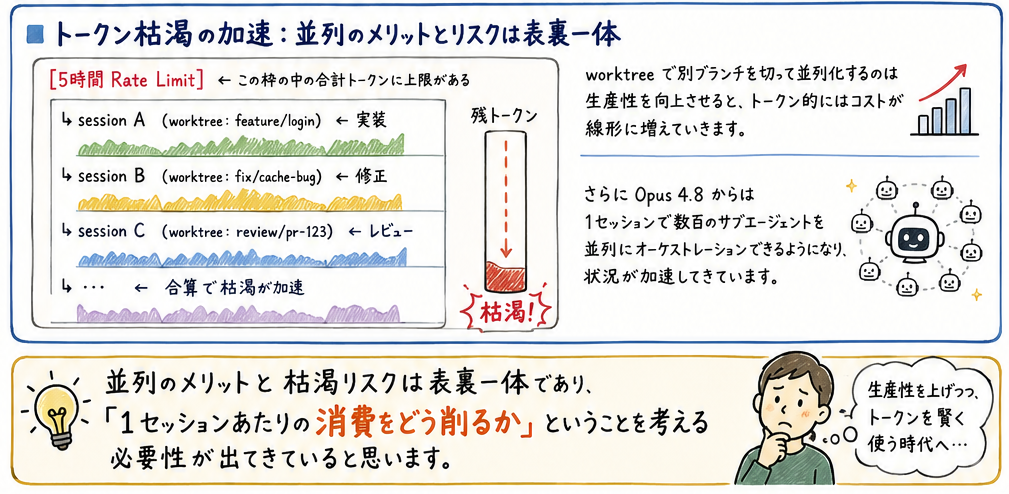
git worktree を使い別ディレクトリでブランチを切り、複数セッションを並列で動かす(2以上の並走が常態)のが標準的になりました。
その結果、当然なのですが、並列度が上がるほど、やりとりする言葉の量=トークンの増加が速くなっています。
[5時間 Rate Limit] ← この枠の中の合計トークンに上限がある
├ session A (worktree: feature/login) ← 実装
├ session B (worktree: fix/cache-bug) ← 修正
├ session C (worktree: review/pr-123) ← レビュー
└ … ← 合算で枯渇が加速worktree で別ブランチを切って並列化するのは生産性を向上させると、トークン的にはコストが線形に増えていきます。
さらに Opus 4.8 からは 1セッションで数百のサブエージェントを並列にオーケストレーションできるようになり、状況が加速してきています。
並列のメリットと枯渇リスクは表裏一体であり、「1セッションあたりの消費をどう削るか」ということを考える必要性が出てきていると思います。
(補足:Claude Max 20x のプラン名・上限値・週次枠の有無は変わりやすいので、最新は公式ドキュメントでの確認をおすすめします。2026年6月時点では 5時間ウィンドウ運用が前提)
実践的対策: トークン最適化戦略
本題です。
サブスクリプションにて Claude Code を使う場合、トークンを最適化する施策として以下3軸が有効だと考えています。
アジェンダ
アジェンダ
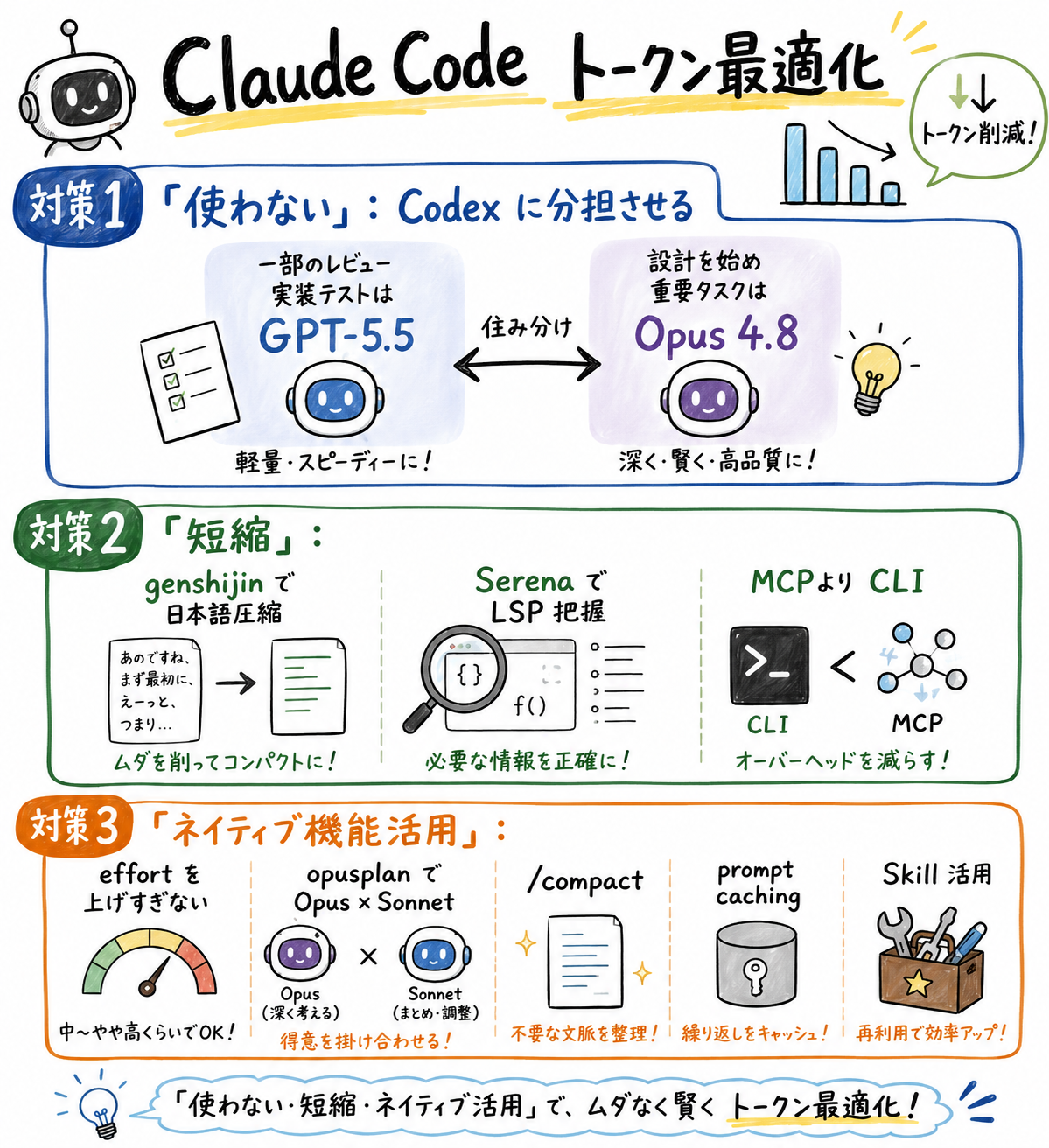
対策1:そもそも Claude を使わない
- Codex をサブエージェント的に利用する
- MCP より CLI を使う
対策2:言葉の短縮
- genshijin で文を単純化する
- serena でコードベースを理解しやすくする
対策3:ネイティブ機能でトークン最適化
- effort パラメータ ── 常時 max をやめて auto がいい
- opusplan ── Plan は Opus、実行は Sonnet
- /compact /clear で長いセッションを中間サマリー
- CLAUDE.md が肥大化したら分割する
- 冗長にならないようにプロンプトで指示する
- prompt caching は SKILL で効かせる
- .claudeignore でよけいなファイルを除外
- SKILL 肥大化問題には
disable-model-invocation: true
対策1:そもそも Claude を使わない
Claude のトークン戦略の1発目が「Claudeを使わない」というジョークのような対策です。
Codex をサブエージェント的に使う: シンプルタスク精度向上+セカンドオピニオン
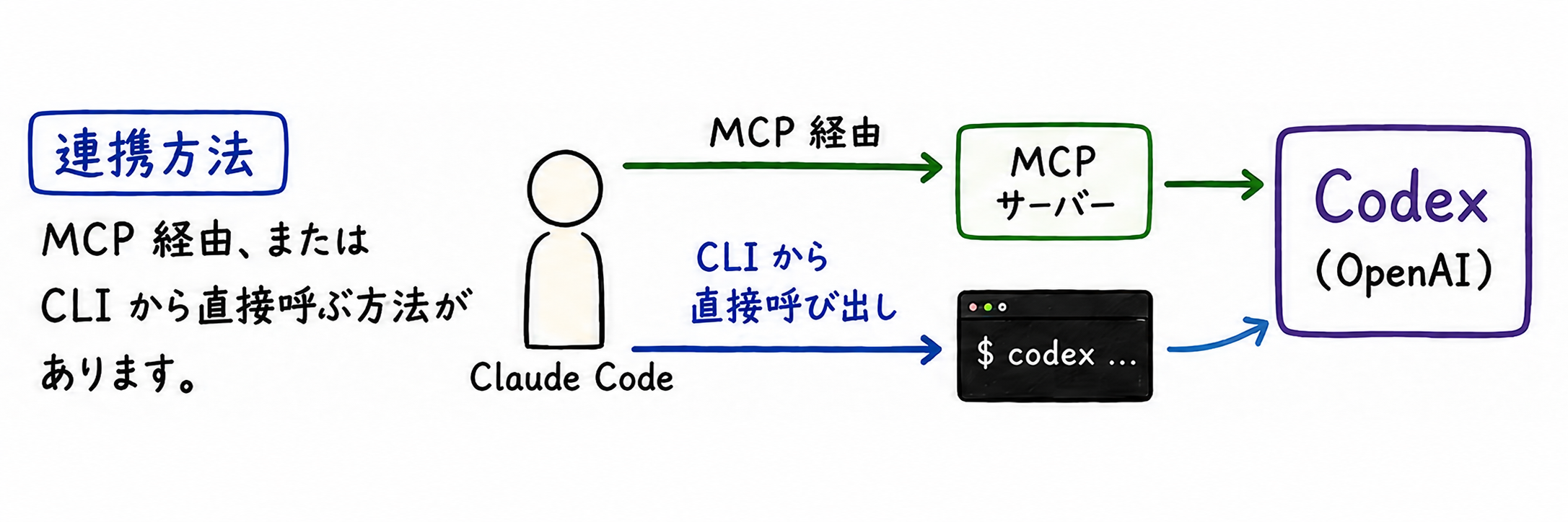
OpenAI ChatGPT 契約のトークンに少し余裕があることが前提になりますが、Codex 連携が非常に効果的です。
Codex をサブエージェント的に利用して Claude Code のトークン消費を抑えます。
連携方法として MCP 経由、または CLI から直接呼ぶ方法があります。
Opus 4.8 vs GPT-5.5(2026年6月時点・各ベンダー公称値)
ここで、なぜ「使い分け」が成立するのか。 モデルの得手不得手を数値で見ると分かりやすいかと思います。
| ベンチマーク | Opus 4.8 | GPT-5.5 | 何を測るテストか |
|---|---|---|---|
| Terminal-Bench 2.0 | 74.6% | 82.7% | ターミナル環境で、コマンド実行・ファイル操作・スクリプト作成・検証、プログラミング |
| SWE-bench Pro | 69.2% | 58.6% | 実際のリポジトリ上で、複雑なIssueの原因を特定し、複数ファイルにまたがる修正を通してテストを通せるか |
つまり、GPT-5.5 はシンプルな開発タスク、Opus 4.8 はリポジトリ全体の設計・実装という住み分けになるかと思います。
加えて、レビューの精度をセカンドオピニオンで向上させたいときにも、別系統のモデルを噛ませる意味があります。
※ MCP より CLI を使う
「Claudeをつかわない」対策の派生として、Codex での実装やレビューの単発タスクは CLI で充分に機能すると考えています。
処理を人間が明確に把握している場合、MCP より CLI で操作させたほうがトークン最適化になります。
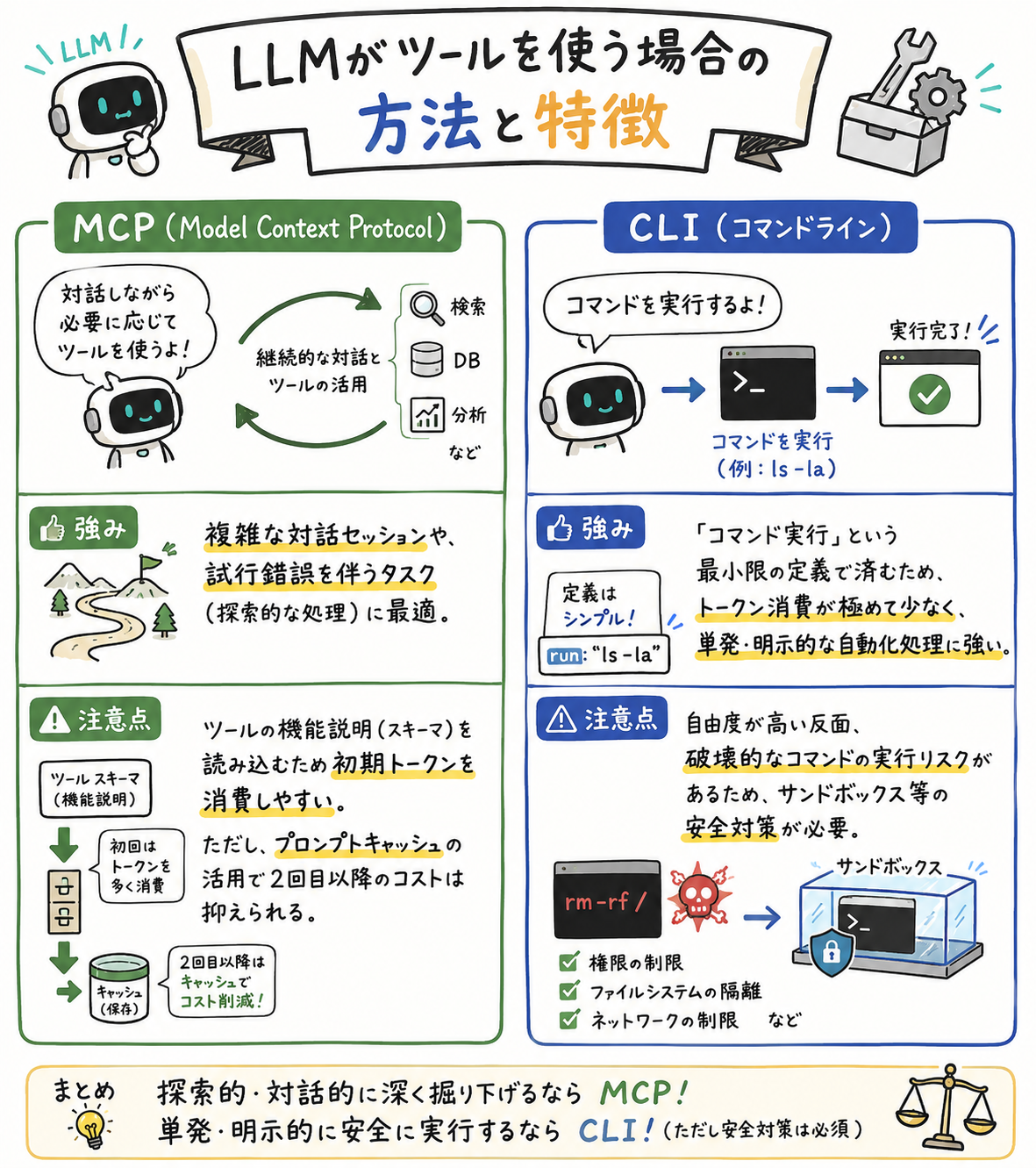
LLMがツールを使う場合の方法と特徴
MCP(Model Context Protocol)
強み: 複雑な対話セッションや、試行錯誤を伴うタスク(探索的な処理)に最適。
注意点: ツールの機能説明(スキーマ)を読み込むため初期トークンを消費しやすい。ただし、プロンプトキャッシュの活用で2回目以降のコストは抑えられるはず。
CLI(コマンドライン)
強み: 「コマンド実行」という最小限の定義で済むため、トークン消費が極めて少なく、単発・明示的な自動化処理に強い。
注意点: 自由度が高い反面、破壊的なコマンドの実行リスクがあるため、ちゃんとわかっている人がサンドボックス等の安全対策をして使うのが適切。
例としてわかりやすいのが git 操作です。 定型的な git 操作はコマンドライン数行で確実に動きますし、トークンも食いません。 逆に、初めてで全くわからない操作を相談しながら進めるなら、MCP で段階を踏むのが適切かと思います。
ブラウザ操作も同様で、Playwright MCP より Playwright CLI のほうが軽量という印象です。
Codex についても実装やレビューの単発タスクは CLI で充分に要件を満たすことができます。
(この Codex 連携の詳細は別記事で扱う予定です。公開時にリンクを貼る)
対策2:言葉の短縮
genshijin(原始人):レスポンス日本語文章を単純化する Skill + MCP Middleware
https://github.com/interfacex-co-jp/genshijin
genshijin は Claude Code 向けの日本語レスポンス単純化スキル(+MCP)で、本家 caveman を日本語版にした仕組みになるかと思います。
LLMからの回答の日本語を簡易表現にしてトークンを減らします。公式では トークンを約75%削減すると謳っています。(削減率は、実環境での実測は各自の –stats 等で取るのが確実です)
実際の例はこんな感じです。(公式から引用)
Before: データベースのコネクションプーリングというのは、リクエストが来るたびに新しい接続を確立するのではなく、あらかじめ作成しておいた接続を再利用する仕組みのことです。 After: プール = DB接続再利用。ハンドシェイク省略し、高負荷時に高速に動作。
内容は保ったまま、トークンだけ削っていることがわかると思います。CLAUDE.md や SKILL 等もこちらで事前に圧縮することができるかと思います。
また、 MCP server を多数使っていて「tool description が重い」という点についても MCP の genshijin-shrink を使うことで最適化を図れます。
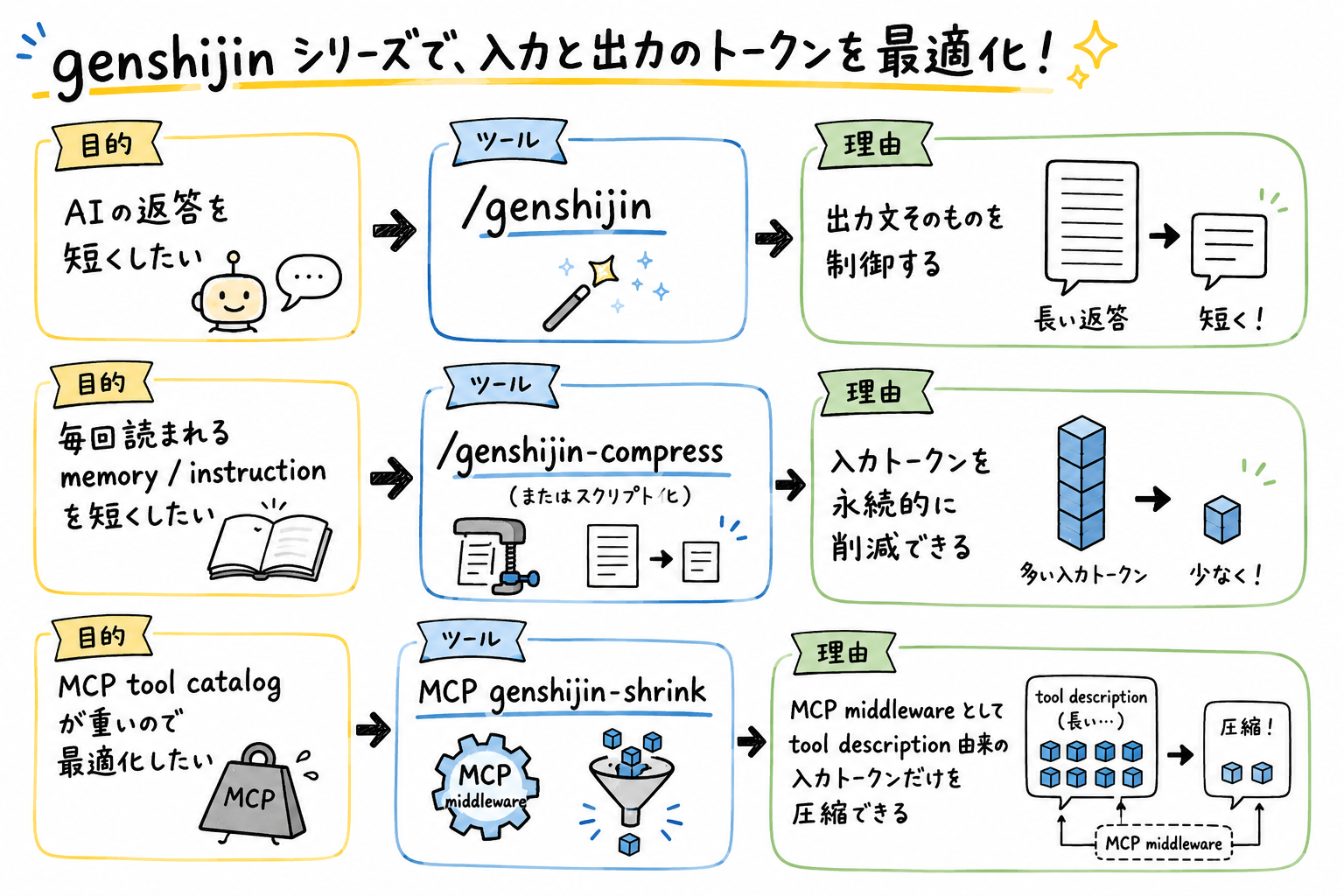
整理すると以下のような用途に向いています。
目的:
AIの返答を短くしたい
ツール:
/genshijin
理由:
LLMからの出力文そのものを単純化できる
目的:
毎回読まれる md (memory / instruction) を短くしたい
ツール:
/genshijin-compress または CLI/スクリプト化
理由:
ファイルの日本語をシンプルに修正し入力トークンを永続的に削減できる
目的:
MCP tool catalog が重い
ツール:
MCP genshijin-shrink
理由:
tool description 由来の入力トークンだけを短いもの圧縮できる
Serena ── コードベースを LSP でセマンティックに把握するための MCP
https://github.com/oraios/serena
コードベース調査フェーズのトークン消費が大きい場合、対策としては Serena MCP があります。
内部的には LSP(Language Server Protocol)でコードをシンボル単位に把握しており、ファイル全体を読まずに必要な箇所だけを拾っています。つまり、巨大なファイルをコンテキストに流し込む代わりに、関連するシンボルだけを読むことで、大規模・複雑なリポジトリほど、この token 効率化が効いてくると思います。
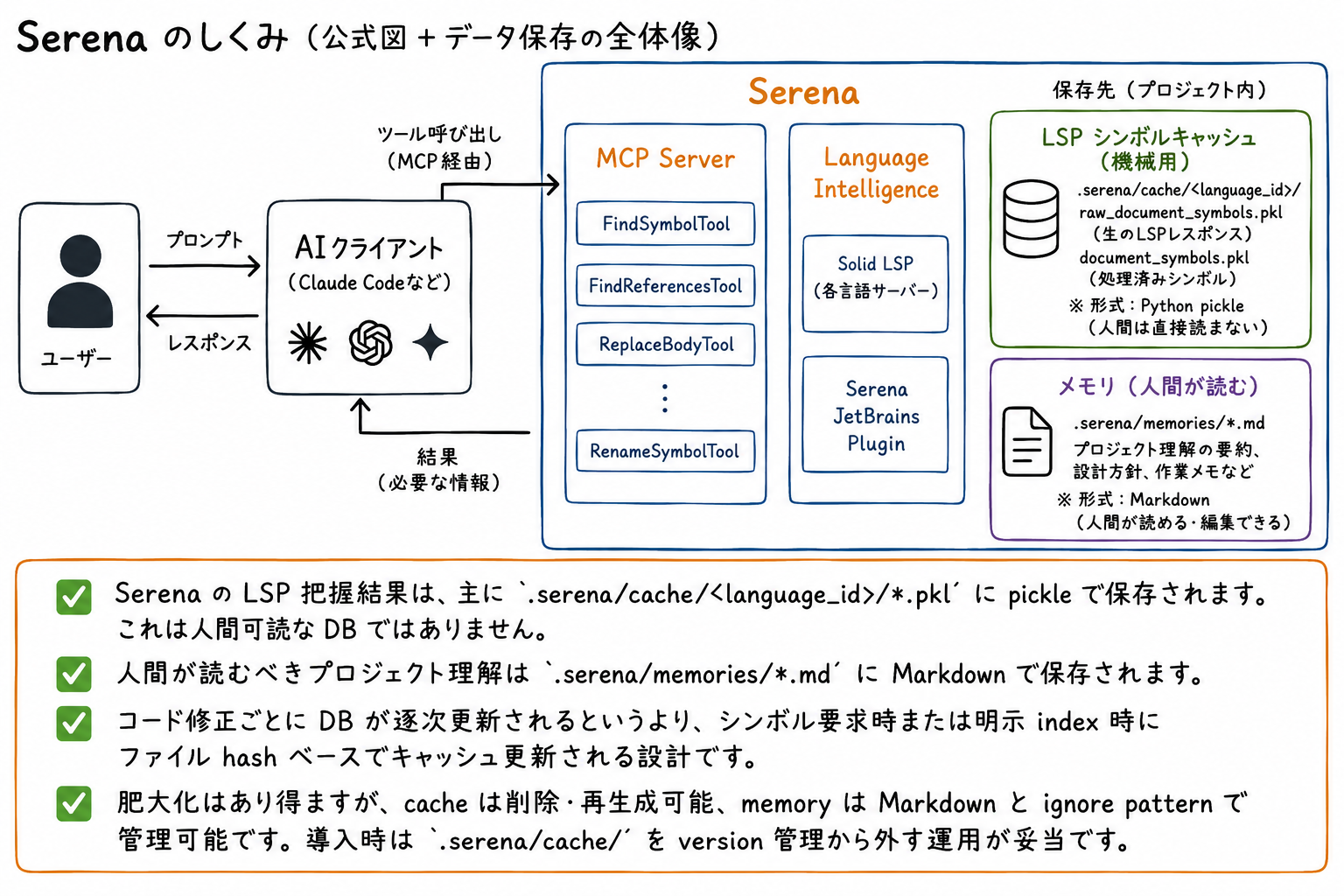
Serena の LSP 把握結果は、主に以下のような Python pickle ファイルで保存されます。これは人間可読な DB、SQLite、Vector Store などではありません。人間が直接読む前提の形式ではないため、直接的には触る必要がないかと思います。
.serena/cache/[language_id]/*.pkl
仮に人間が確認したい場合、可読ドキュメントは .serena/memories/*.md に Markdown で保存されています。
[project]/.serena/memories/.md
~/.serena/memories/global/.md
更新が1つの負荷になる可能性がありますが、コード修正ごとに md が逐次更新されるというより、シンボル要求時または明示 index 時にファイル hash ベースでキャッシュ更新される設計で負担が最小化されています。
レポジトリの成長に伴い md, pkl の肥大化はあり得ますが、cache は削除・再生成可能、memory は Markdown と ignore pattern で管理可能です。導入時は .serena/cache/ を version 管理から外す運用が妥当です。
対策3:ネイティブ機能でトークン最適化
最終パートは Claude が元々持っている機能を活かす作戦です。
ネイティブ機能だけでも、削れるところは多いと思います。
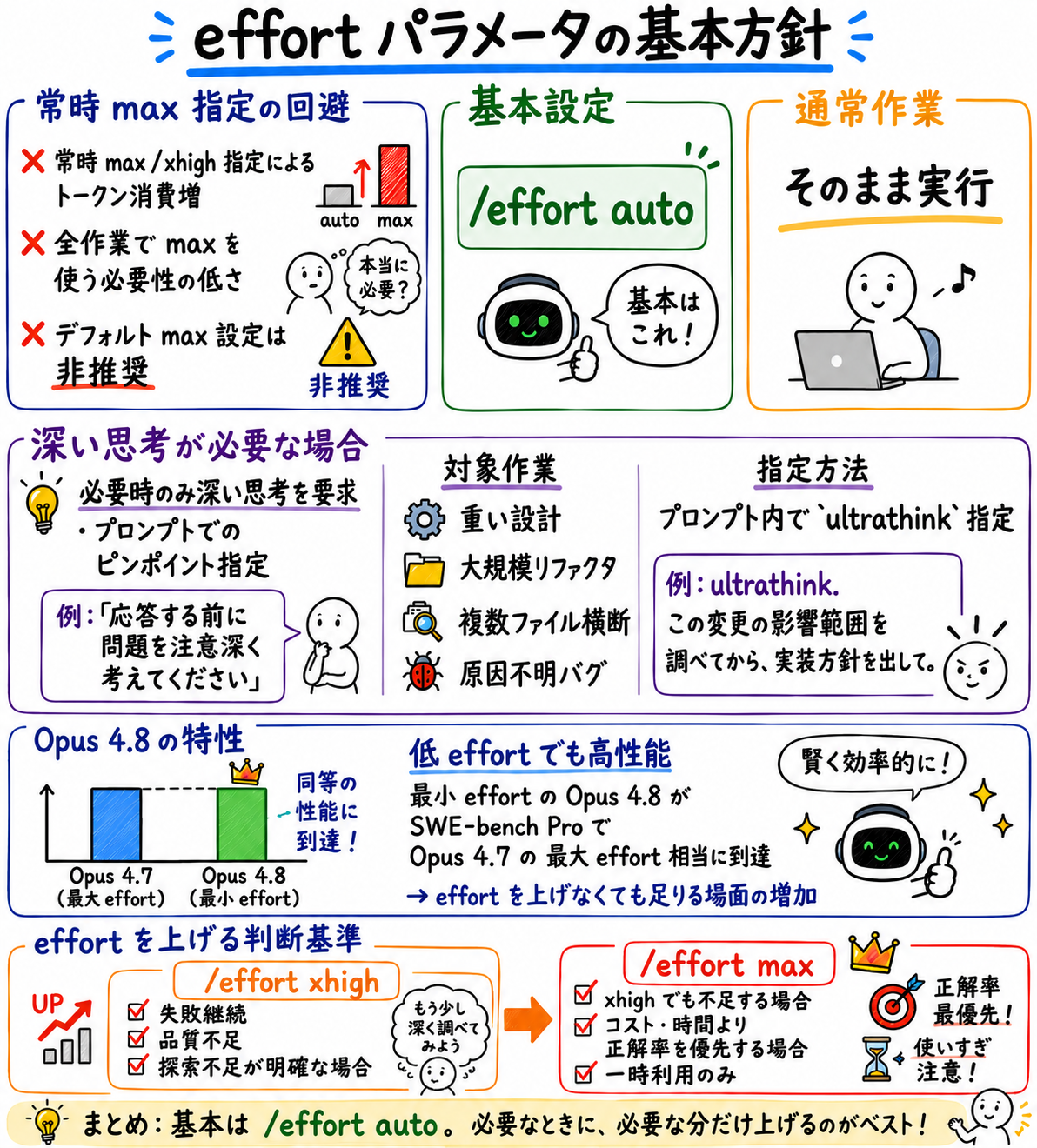
effort パラメータ で常時 max ではなく auto でよい
Thinking レベルを指定する effort パラメータも重要です。 常に max / xhigh を要求すると当然トークンを食ってしまうわけですが、必ずしも全ての作業を max で行う必要はありません。デフォルト max のような設定は推奨されないと考えた方が良いと思います。
逆に、必要なときだけ深く考えさせることがプロンプトの指定で可能です。 「応答する前に問題を注意深く考えてください」といったプロンプトで、ピンポイントに要求するのが良いのではないでしょうか。
加えて、 Opus 4.8 の特性として、最小 effort の Opus 4.8 が、SWE-bench Pro で Opus 4.7 の最大 effort 時の性能に並ぶという結果が公表されています。 effort を上げなくても足りる場面が増えたということが言えると思います。
基本設定:
/effort auto
普段:
そのまま使う
重い設計・大規模リファクタ・複数ファイル横断・原因不明バグ:
プロンプト内で「ultrathink」を付ける
例: ultrathink. この変更の影響範囲を調べてから、実装方針を出して。
失敗が続く、品質が足りない、探索不足が明確:
/effort xhigh
それでも足りない、かつコスト・時間より正解率を優先:
/effort max
ただし一時利用だけ
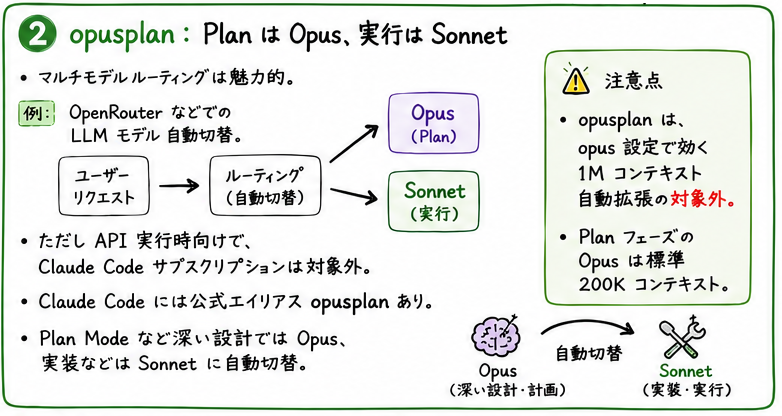
モデルエイリアス opusplan ── Plan は Opus、実行は Sonnet
マルチモデルルーティング(OpenRouter などのゲートウェイで、必要に応じてLLMモデル自動切替)は非常に魅力的なのですが、これは API 実行時専用で、Claude Code サブスクリプションでは対象外です。
逆に、Claude Code には起動時のモデル指定として opusplan があります。 Plan Mode での設計の深い思考は Opus に任せ、実装時は Sonnet へ自動で切り替えてくれます。
# 起動時に
claude –model opusplan
# またはセッション中に
/model opusplan
※ただ、1点注意があります。 opusplan は、opus 設定で効く 1M コンテキストの自動拡張の対象外です。 Plan フェーズの Opus は標準の 200K コンテキストで動きます。
/compact /clear で長いセッションを中間サマリー
セッションが長大化したら /compact でコンテキストを要約することで、冗長な出力を圧縮できます。その後に /clear で全消しも有効です。
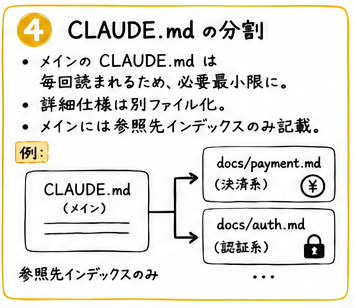
CLAUDE.md が長い場合は分割する
メインの CLAUDE.md ファイルは毎回必ず読まれるので、内容を必要最小限にしておいたほうが得策です。
他はインデックスを書いて分けておく。例えば決済系の仕様はこのファイルだよということを書いておき、参照すべきときだけファイルを読みにいくように指示できます。
例:
決済系:docs/payment.md
認証系:docs/auth.md
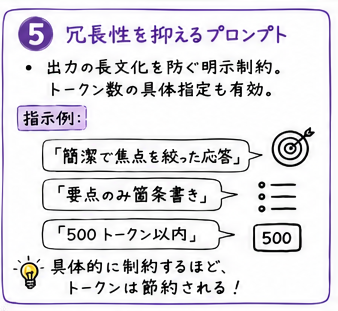
冗長なレスポンスをプロンプトで制限する
LLM は丁寧に長いレスポンスをしがちですが、プロンプト「簡潔で焦点を絞った応答を提供してください」で冗長な出力を抑えることができます。
また、「トークン数を〇〇にしてください」など具体的に指定することも効果があります。
指示例:
「簡潔で焦点を絞った応答してください」
「要点のみ箇条書きでお願いします」
「500トークン以内にしてください」
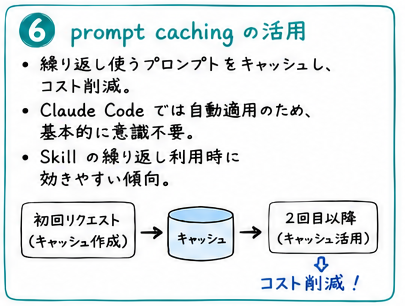
prompt caching は SKILL で効かせる
prompt caching は繰り返し使うプロンプトをキャッシュしてコスト削減する仕組みで、APIの場合に効果が高い手法ですが、 Claude Code では自動で効くので、あまり気にしなくていいと思います。
ただ prompt caching は Claude Code が Skill を繰り返し使うときに効きやすいので、 Skill は使いまくりましょう。
.claudeignore でよけいなファイルを除外
余計なものを読ませない除外設定として、.claudeignore があります(.gitignore と同じ glob 記法)。 テストデータの塊や画像などをコンテキストから外す目的です。
# .claudeignore の例
node_modules/
dist/
*.png
fixtures/large-seed-data.json # テストデータの塊を除外
ただ、怪しい情報もあります。 Claude Code は .claudeignore や .gitignore を確実には尊重しないという報告があり、ignore 指定したはずの .env を読み取ってしまうケースが2026年初頭に指摘されました。
つまり、.claudeignore は「読まないでほしい」という意思表示にはなりますが、ハードな遮断ではないという理解が要ります。 確実に効かせたいなら、PreToolUse フック型の実装など別の仕組みを併用するのが現実的だと考えています。 (機密ファイルの除外を、これ一枚に頼り切らないのが安全)

SKILL 肥大化問題 には disable-model-invocation: true
SKILLが大量にあると初期読み込みの段階でトークンを食ってしまうのでは?という質問がありました。
結論としては一部そういった問題もあると思います。
以下で技術的理由と対策を整理します。
SKILL の技術的仕様
Claude Code は ~/.claude/skills/、プロジェクトの .claude/skills/ を読む。
ただし SKILL.md 本体を全部読むわけではない。description (と when_to_use) が読み込まれる。
SKILL が1回読まれると、セッション中はずっと全体が読み込まれた状態になる。

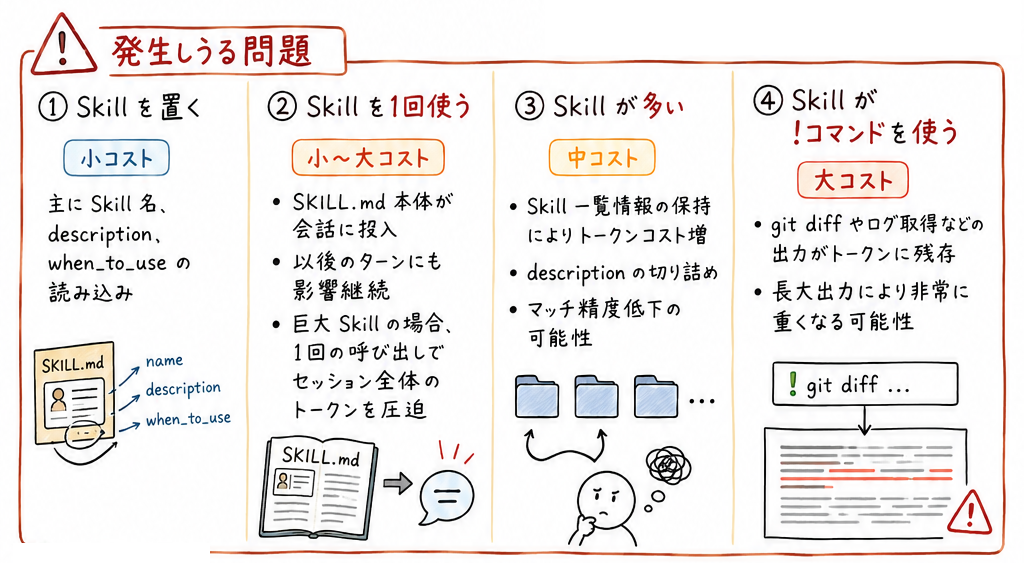
SKILL がトークン増加に影響しうる問題リスト
Skill を置く:
小コスト。主に Skill 名と description / when_to_use が読まれる。
Skill を1回使う:
小コスト。 SKILL.md 本体が会話に入る。以後のターンで効き続けるため重い。
Skill 1つが巨大な場合、一度呼ばれるだけでセッション全体のトークンを圧迫する。
Skill が多い:
中コスト。 Skill 一覧情報を持つので、トークンコストが増える。説明が切り詰められ、マッチ精度も落ちる。
Skill が !コマンド (例えば git diff 、 ログ取得)をする:
大コスト。コマンド出力がトークンに残るので、非常に重くなる。
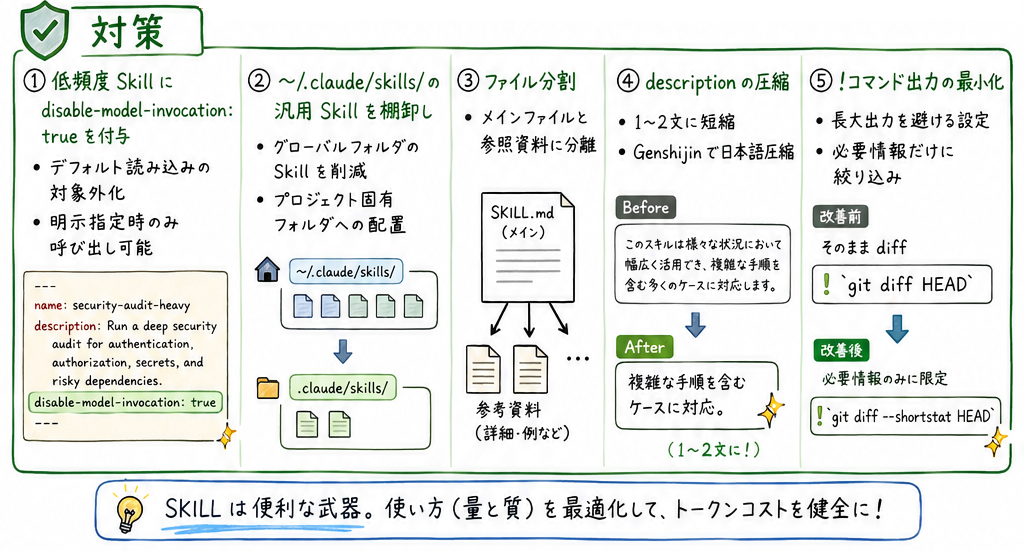
対策
・低頻度 Skill に disable-model-invocation: true を付ける。これでデフォルトで読まれなくなります。明示的に指定すれば、呼ぶことが可能です。
—
name: security-audit-heavy
description: Run a deep security audit for authentication, authorization, secrets, and risky dependencies.
disable-model-invocation: true
—
・~/.claude/skills/ に大量に置いている汎用 Skill を棚卸し。
→ グローバルフォルダのスキルを減らし、プロジェクト固有フォルダのスキルにする。
・ファイルをメインと参照資料に分割
・description を 1〜2 文に圧縮する(Genshijinで日本語圧縮)
・!を使う時は出力が長大化するので、以下のように出力が最小限になるようにチューニングしておく。
改善前)そのままdiff
!`git diff HEAD`
改善後)必要な情報だけに絞り込む
!`git diff –shortstat HEAD`
朝8時ログイン
最後に超アナログな対策として 朝8時にログインすれば、13時には5時間枠がリセットされる、というのがあります。
人間の稼働時間とリセットタイミングを都合よく噛み合わせる、というだけの対策なんですが、地味にチーム内で流行っています。
今日のまとめ
トークン枯渇への対策を3軸で整理しました。
・対策1「使わない」
Codex に分担させる。一部のレビュー実装テストは GPT-5.5、設計をはじめとした重要タスクは Opus 4.8 の住み分け
・対策2「短縮」
genshijin で圧縮、Serena で LSP 把握 、MCPよりCLI
・対策3「ネイティブ機能活用」
effort を上げすぎない、 opusplan で Opus×Sonnet、 /compact 、 prompt caching 、 Skill を活用
これらを組み合わせれば、Max 20x をすぐ用意できない状況でもまだ戦えるのでは!?と思っています。
ただもっと大きな視点では、予算面・プラン面での最適化が必要で、継続的に組織の重要課題となることは間違いありません。
「何があっても開発を止めるな!」という気持ちで最適化を図っていこうと思います。
GMO は採用に力を入れています。鋭意募集中
GMOインターネットグループ グループ研究開発本部では、最新のテクノロジーを調査・検証しながらWebプロダクト、AI、ロボットに関する開発を行う人材を募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD